以下为机器之心根据周志华教授的现场演讲内容进行的整理 。
周志华教授演讲内容概要
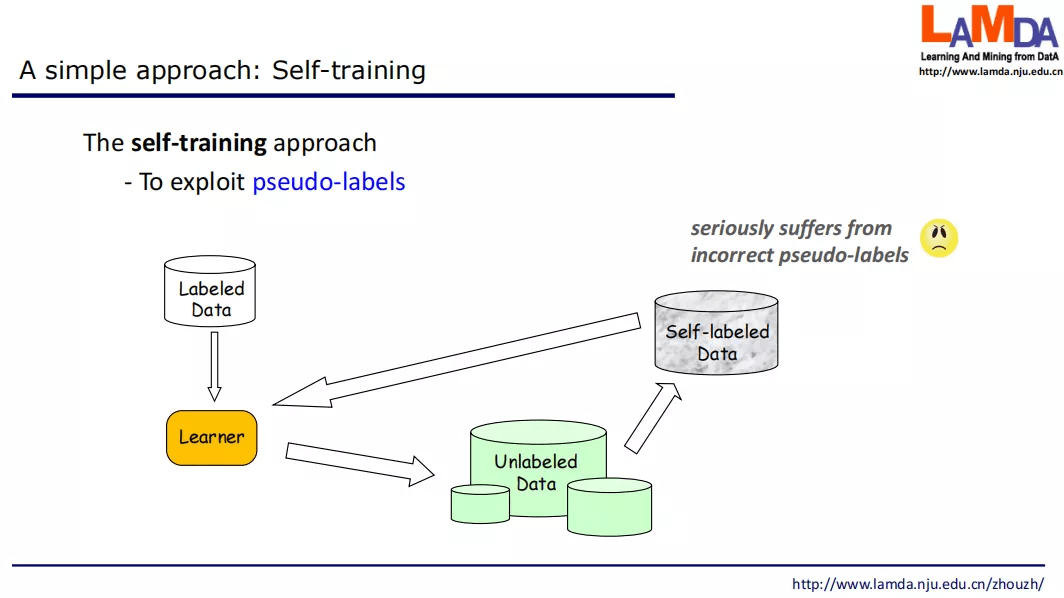
自训练方法(Self-training)
机器学习通常依赖大量的有标签数据 , 而现实中很容易获得大量无标签数据 , 如何利用无标签数据辅助少量有标签数据进行学习 , 是一个重大挑战问题 。 很容易想到的办法有自训练 / 自学习 , 用有标签数据训练一个模型 , 然后用模型来对无标签数据提供伪标签 , 然后基于伪标签数据来更新模型 。 但这样做不太“靠谱” , 因为当初始有标签数据很少时 , 训练出的初始模型性能差 , 伪标签中会有大量错误 , 导致学习性能越来越差 。
文章图片
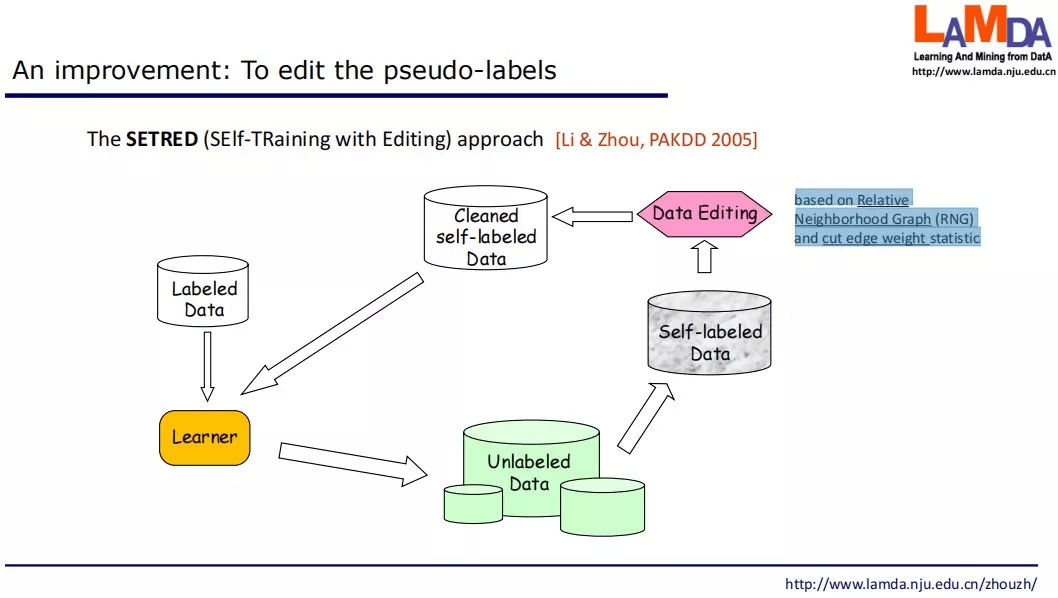
这样的做法在很久以前就有所改进 , 例如对伪标签数据进行数据编辑 , 对数据净化之后再用于学习 。 编辑过程可以采用一些统计假设检验方法 。 然而总体上这样的方法仍然是启发式的 , 人们希望有一些有理论支撑的方法 。
文章图片
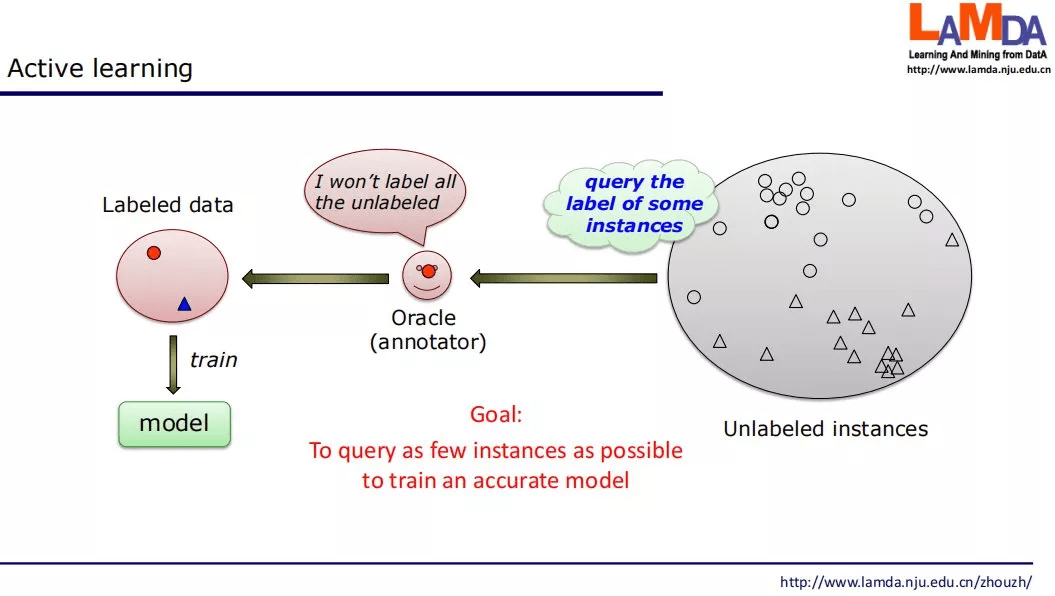
主动学习(Active learning)
主动学习(Active learning)是机器学习的一个分支 , 其主要思路是 , 从大量无标签样本中挑选少量样本给人类专家进行标注 , 从而让人类专家的力气用在 「最有价值」的地方 。 其目标是通过尽量少地选择样本给人类专家标注 , 能够大幅度提升学习性能 。
文章图片
典型的两大类代表性方法是有选择最 informative 的示例进行标注 , 和选择最有代表性的示例进行标注 。 新的发展是同时兼顾 informative 和代表性 。

文章图片
然而 , 主动学习假设了「人在环中」(human-in-the-loop) , 如果没有人类专家的帮助 , 则必须考虑其他的办法来利用无标签数据 , 例如半监督学习 。
【周志华教授发表首届IJCLR开场Keynote:探索从纯学习到学习+推理的AI】半监督学习
半监督学习具有代表性的方法包括生成式方法、半监督 SVM、基于图的方法、基于分歧的方法 。

文章图片
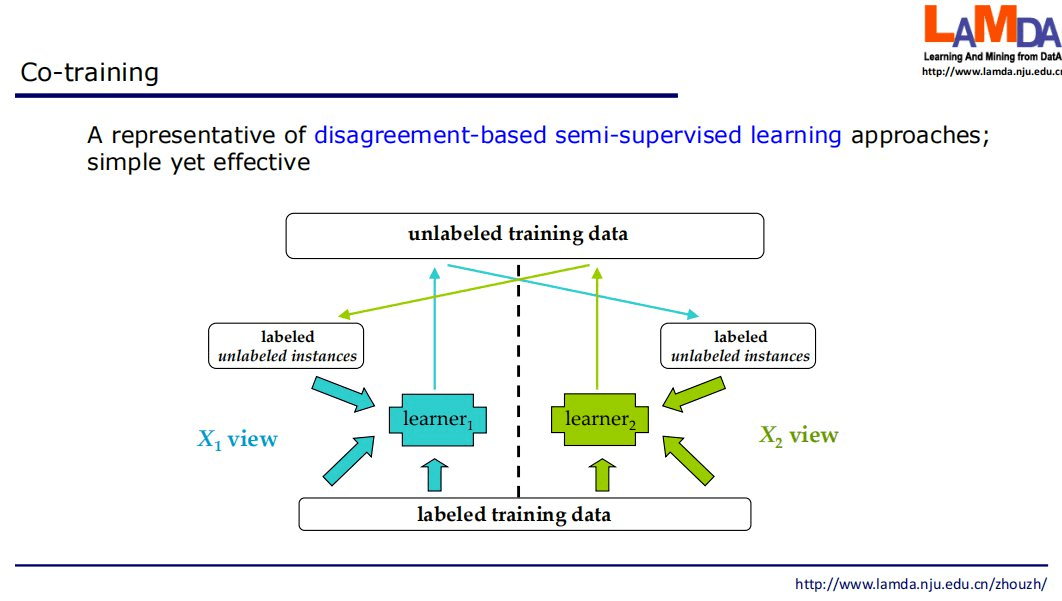
基于分歧的半监督学习是该领域的主流范型之一, 通过训练多个学习器 , 利用它们之间的分歧来对无标签数据进行利用 。 协同训练(Co-training)是基于分歧方法的代表 , 它最初是针对 「多视图」 数据提出 , 多视图数据是指一个样本同时由多个属性集合描述 , 每个属性集合称为一个「视图」 。 协同训练首先基于两个视图分别训练一个分类器 , 然后每个分类器挑选一些可信度高的无标签样本 , 标注后提供给另一个分类器作为有标签数据进行使用 。 由于这些分类器从不同角度训练出来 , 可以形成一种互补 , 从而提高分类精度;就如同从不同角度可以更好地理解事物一样 。
文章图片
这个简单的算法被广泛应用 , 在应用中有令人惊讶的优越性能 。 研究者们努力理解它为什么有效、在什么时候有效 。 机器学习领域奠基人、CMU 的 Tom Mitchell 教授等人证明 , 如果数据具有两个满足条件独立性的视图、且每个视图都包含足够产生最优学习器的信息 , 则协同训练能够通过利用无标签数据任意提升弱学习器的性能 。
然而这个理论条件在现实中并不成立 , 因为关联到同一个样本的两个视图通常并不满足条件独立性 。 此后有许多著名学者 , 如计算学习理论大会主席 Balcan 等人做了重要工作 , 最后周志华教授课题组在理论上最终给出了协同训练能够奏效的充分条件和充分必要条件 。 其理论揭示出只要两个学习器有较大差异 , 就能通过协同训练利用无标签数据提升性能 。 该理论说明 , 「两个视图」并非必须 , 只要想办法让学习器之间具有较大差异即可 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。