文章图片
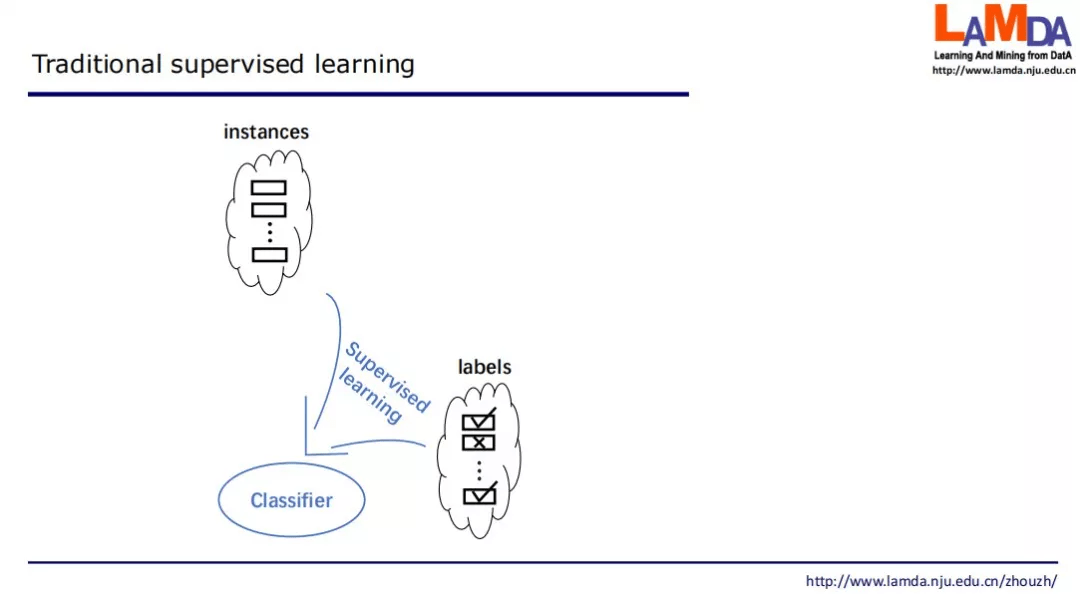
现在返回来看传统的监督学习 。 监督学习首先需要有很多示例以及标签 , 将它们结合起来进行监督学习 , 训练出一个分类器 。
文章图片
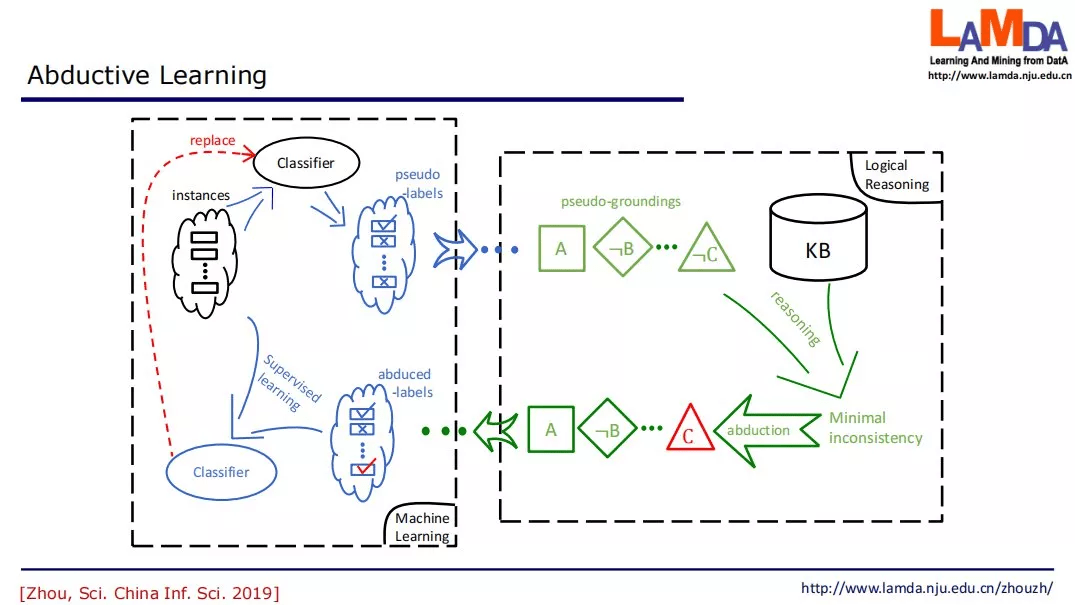
反绎学习的设置不太一样 , 反绎学习中假设有一个知识库 , 以及一个初始分类器 。
在这个学习中 , 我们先把所有的数据提供给这个初始分类器 , 初始分类器猜测一个结果 , 得到结果之后就会把它转化成一个知识推理系统能够接受的符号表示 。
那么接下来这一步 , 我们就要根据知识库里面的知识来发现有没有什么东西是不一致的?如果有不一致 , 我们能不能找到某一个东西 , 一旦修改之后它就能变成一致?或者修改之后使得不一致程度大幅度降低?这就需要我们去找最小的不一致 。 如下图所示:假设我们现在找到 , 只要把这个非 C 改成 C , 那么你得到的事实就和知识都一致了 。 我们就把它改过来 , 这就是红色的这个部分 , 这就是一个反绎的结果 。 而反绎出来的这个 C , 我们现在会回到原来的标签中 , 把标签改掉 , 接下来我们就用修改过的标签和原来的数据一起来训练一个新分类器 。 这个分类器可以代替掉旧的分类器 。 这个过程可以不断地迭代下去 。 这个过程一直到分类器不发生变化 , 或者我们得到的伪事实和知识库完全一致 , 这时候就停止了 。
文章图片
从上图可以看到 , 左半部在进行机器学习 , 而右半部在进行逻辑推理 。 机器学习和逻辑推理这两者互相依赖 , 循环处理往复 , 直到分类器与知识库一致(此时相当于分类器已经 「学到」了知识库中的内容)或者分类器连续数轮不再提升;如果允许对知识库进行修改 , 还可以使得知识库中的内容可以被精化或更新(这是利用数据经验来改善知识的过程) 。
反绎学习不依赖于真实标签 , 但如果存在有标签数据 , 它也可以充分利用 , 例如可以生成更可靠的伪标签等 , 从这个意义上说 , 反绎学习可以被视为一种更具一般性的弱监督学习 , 其监督信息不仅限于标签 , 还可以是领域知识 。
初始分类器可以是预训练好的深度模型或者迁移学习模型 , 甚至可以很简单 , 例如基于聚类或最近邻分类的预处理;其基本作用是让整个过程 「启动」 起来 。 在领域知识丰富可靠时 , 通过知识的利用可以使得整个过程并不依赖于初始分类器的强度 。
知识库目前仍需要人工总结人类经验并写成一阶逻辑规则 。 今后可能通过学习来对知识库进行改善和提炼 。 对数据事实与符号知识的联合优化不再能依靠常规的梯度方法 , 使用了周教授团队自己开发的不依赖梯度计算的零阶优化方法 。
周教授还简要介绍了反绎学习应用于司法案件辅助量刑的初步情况 。
文章图片
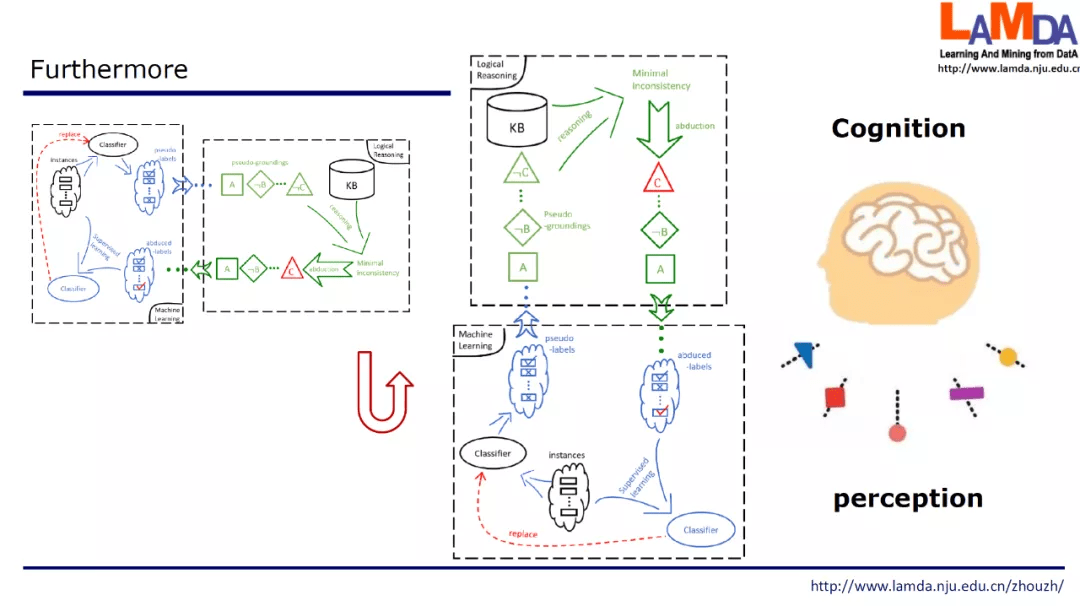
最后 , 如果将反绎学习示意图旋转一下 , 上半部是逻辑推理对应了认知过程 , 下半部是机器学习对应了感知过程 , 则反绎学习也为探索认知和感知交互提供了一个框架 。
想要了解更多关于「学习 + 推理」内容的你 , 不妨深入了解一下这个大会 , 相信你能从中收获满满 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。