文章图片
MLU370-S4、MLU370-X4 两种加速卡的规格 。
为什么在计算机视觉和自然语言处理任务中 , 寒武纪能够做到超越同级数据中心的 GPU?在性能的背后 , 是寒武纪全方位的技术革新 。
「chiplet」技术 , 未来芯片的发展方向
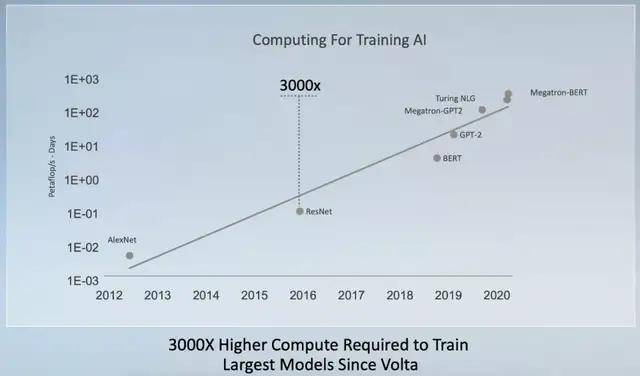
根据英伟达的统计 , 自 2012 年到现在的大规模深度学习模型参数量呈现指数增长 。 相比之下 , 即使通过增加功耗等方法 , AI 芯片的算力还是只能延续每两年翻倍的速度 。
为了提供更高的运算效能 , 人们寻找的方法包括增加处理器核心数量 , 提升缓存容量及 I/O 数量等等 。 这些情况使得 IC 设计者即便使用最先进制程 , 也很难把芯片尺寸变得更小 。
文章图片
自 2017 年底英伟达发布 Tesla V100 之后 , 训练最大模型的算力需求增长了 3000 倍 。
从英伟达 T4 到 A10 的迭代我们可以看出 , 制程从 12nm 进步到 8nm , 功耗翻倍 , 性能提升则是 2.2-2.5 倍 。 另一方面 , 先进制程、低良品率造成的成本问题也让芯片厂商不堪重负 , 使用 chiplet 的方式打造新一代芯片或许是未来的重要发展方向 。
思元 370 是寒武纪首次采用 chiplet 技术打造的芯片 , 在一颗芯片中封装 2 颗 AI 计算芯粒(被称为 MLU-Die) , 每个 MLU-Die 具备独立的 AI 计算单元、内存、IO 以及 MLU-Fabric 控制和接口 , 相互之间通过 MLU-Fabric 保证两个 MLU-Die 间的高速通讯 。
此前 , AMD 在 CPU 上就通过使用 7 纳米制程和 chiplet 构建芯片的方式实现了对于英特尔的「逆袭」 。 最近一段时间 , 英特尔也提出即将使用 chiplet 构建芯片的计划 。 在一块芯片上置入多个 die 虽然可以提高晶圆的利用效率 , 但会面临很多技术方面的问题 , 芯粒间的信息传递速度是其中最大的挑战 。
尤其在深度学习的推理和训练任务中 , 模型和数据在芯片内部是强并行的 , 所以芯粒间信息传递速度的问题还会更加凸显 。 对此 , 寒武纪称 MLU-Fabric 能够以低功耗、低延时、超高带宽的技术来解决传递速度的问题 , 帮助用户实现应用无感知的体验 , 单从这点来看 , 寒武纪 MLU-Fabric 芯粒间的互联技术已经超越了 AMD 的处理器 。

文章图片
思元 370 采用 chiplet 技术 , 可实现不同算力、内存和编解码器的组合 。
尽管寒武纪已经凭借思元 370 验证了自己在 chiplet 技术上的突破 , 但 chiplet 技术 , 仍会面临着诸多挑战 , 例如在封装技术与生产工艺、EDA 工具链、片上互联(NoC)或 Interposer 上互联、chiplet 间接口与协议标准化、chiplet 模块的 DFT、验证、可靠性与 DFM 等方面仍然有较多经验需要积累 。
【寒武纪发布云端AI芯片思元370,chiplet技术打造,性能大幅提升2倍】但寒武纪对 chiplet 技术依然充满信心 , 并希望思元 370 可以通过不同的组合为客户提供更多样化的产品选择 。
处理器架构大幅更新
架构方面的改进是思元 370 的又一个升级重点 , 在 AI 芯片上 , 整型常用于推理 , 浮点运算应用于训练 , 寒武纪自研的智能处理器架构 MLUarch03 拥有新一代张量运算单元 , 全面加强了 FP16、BF16 以及 FP32 的浮点算力 , 同时支持推理和训练任务 。

文章图片
寒武纪智能芯片架构演进 。
芯片的指令集对于任务执行效率与硬件本身几乎同等重要 , 当年英特尔在摩尔定律减缓的情形下就采取了 Tick Tock 策略——一代提升制程 , 一代改进指令集 。 自研架构的寒武纪对自家芯片拥有完整操控权限 , 也可以实现两条腿走路 , 其在思元 370 上更新了指令集 , 内置的 Supercharger 模块大幅提升了各类卷积效率 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。