
文章图片
Supercharger 和多算子硬件融合技术 。
思元 370 采用的全新 MLUv03 指令集功能更加完备 , 效率更高且向前兼容 , 其还采用了全新的多算子硬件融合技术 , 在软件融合的基础上大幅减少算子执行时间 。
新的加速卡还升级了内存 , 从 DDR4 升级为 LPDDR5 , 带宽从 102.4GB/s 提升至 307.2GB/s , LPDDR5 是一种适用于移动端的内存产品 , 是如今中高端手机的标配 。 为什么要把它用在云端 AI 加速卡上?这或许是在带宽、成本和能效比之间进行权衡的结果 。
思元 370 是国内第一款公开发布支持 LPDDR5 内存的云端 AI 芯片 , 从数据上看 , 其内存带宽达到了上一代产品的 3 倍 , 访存能效达 GDDR6 的 1.5 倍 。
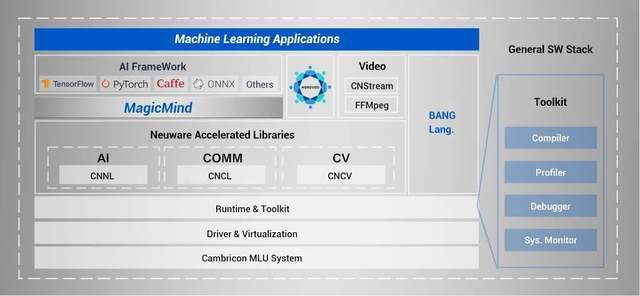
全新推理加速引擎 MagicMind
MagicMind 是寒武纪全新打造的推理加速引擎 , 其定位对标的应该就是英伟达 CUDA 之上的 TensorRT , 但是架构和功能上相对于 TensorRT 更为先进和强大 。 在寒武纪的整体软件栈架构中 , MagicMind 之下是高效软件栈工具和高性能库 , 并且还提供了 Bang 语言支撑定制化开发功能 。
MagicMind 的优势在于可提供极致的性能、可靠的精度以及简洁的编程接口 , 让用户能够专注于业务本身 , 无需理解芯片更多底层细节就可实现模型的快速高效部署 。 与此同时 , 通过 MagicMind 插件化的设计 , 还可以满足在性能或功能上追求差异化竞争力的客户需求 。
MagicMind 支持跨框架的模型解析、自动后端代码生成及优化 , 在 MLU、GPU、CPU 训练好的算法模型上 , 借助 MagicMind , 用户仅需投入极少的开发成本 , 即可将推理业务部署到寒武纪全系列产品上 , 并获得优化后具有竞争力的性能 。
文章图片
推理加速引擎 MagicMind 是寒武纪软件栈 Cambricon Neuware 全新升级的重要组成部分 。
为了加快用户端到端业务落地的速度 , 减少模型训练研发到模型部署之间的繁琐流程 , 寒武纪的统一基础软件平台 Cambricon Neuware 整合了训练和推理的全部底层软件栈 , 包括底层驱动、运行时库、算子库以及工具链等 , 将 MagicMind 和深度学习框架 Tensorflow , Pytorch 做了深度融合 , 可以实现训推一体 。
随着软件栈升级 , 开发者们在寒武纪全系列计算平台上 , 从云端到边缘端 , 用户均可以无缝地完成从模型训练到推理部署的全部流程 , 进行灵活的训练推理业务混布和潮汐式的业务切换 , 可快速响应业务变化 , 提升算力利用率 , 降低运营成本 。
在通用性方面 , Cambricon Neuware 支持 FP32、FP16 混合精度、BF16 和自适应精度训练等多种训练方式并提供灵活高效的训练工具 , 高性能算子库已完整覆盖视觉、语音、自然语言处理和搜索推荐等典型深度学习应用 , 可满足用户对于算子覆盖率以及模型精度的需求 。
支持 8K 解码 , 加入硬件安全模块
思元 370 升级了视频图像编解码单元 , 可提供更高效的视频处理能力和更优的编码质量 , 支持更复杂、更繁重、低延时要求的计算机视觉任务 。
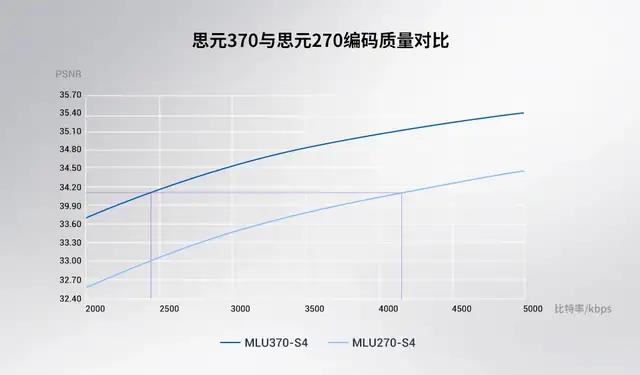
解码方面 , 思元 370 可支持 132 路 1080p 视频解码或 10 路 8K 视频解码 。 编码方面 , 全新编码器通过灵活的码率优化(RDO)控制、多参考帧、二次编码等特性组合 , 在相同图像质量(全高清视频 PSNR)的情况下比上一代产品节省 42% 带宽 , 有效降低带宽成本 。
文章图片
思元 370 视频编码质量显著提升
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。