机器之心报道
编辑:小舟、陈萍
来自多伦多大学和斯坦福大学的研究者开发了一种在连续深度贝叶斯神经网络中进行近似推理的实用方法 。把神经网络的限制视为无限多个残差层的组合 , 这种观点提供了一种将其输出隐式定义为常微分方程 ODE 的解的方法 。 连续深度参数化将模型的规范与其计算分离 。 虽然范式的复杂性增加了 , 但这种方法有几个好处:(1)通过指定自适应计算的容错 , 可以以细粒度的方式用计算成本换取精度;(2)通过及时运行动态 backward 来重建反向传播所需中间状态的激活函数 , 可以使训练的内存成本显著降低 。
【结合随机微分方程,多大Duvenaud团队提出无限深度贝叶斯神经网络】另一方面 , 对神经网络的贝叶斯处理改动了典型的训练 pipeline , 不再执行点估计 , 而是推断参数的分布 。 虽然这种方法增加了复杂性 , 但它会自动考虑模型的不确定性——可以通过模型平均来对抗过拟合和改进模型校准 , 尤其是对于分布外数据 。
近日 , 来自多伦多大学和斯坦福大学的一项研究表明贝叶斯连续深度神经网络的替代构造具有一些额外的好处 , 开发了一种在连续深度贝叶斯神经网络中进行近似推理的实用方法 。 该论文的一作是多伦多大学 Vector Institute 的本科学生 Winnie Xu , 二作是 NeurIPS 2018 最佳论文的一作陈天琦 , 他们的导师 David Duvenaud 也是论文作者之一 。

文章图片
- 论文地址:https://arxiv.org/pdf/2102.06559.pdf
- 项目地址:https://github.com/xwinxu/bayesian-sde
在这种方法中 , 输出层的状态由黑盒自适应随机微分方程(SDE 求解器计算 , 并训练模型以最大化变分下界 。 下图将这种神经 SDE 参数化与标准神经 ODE 方法进行了对比 。 这种方法保持了训练贝叶斯神经 ODE 的自适应计算和恒定内存成本 。
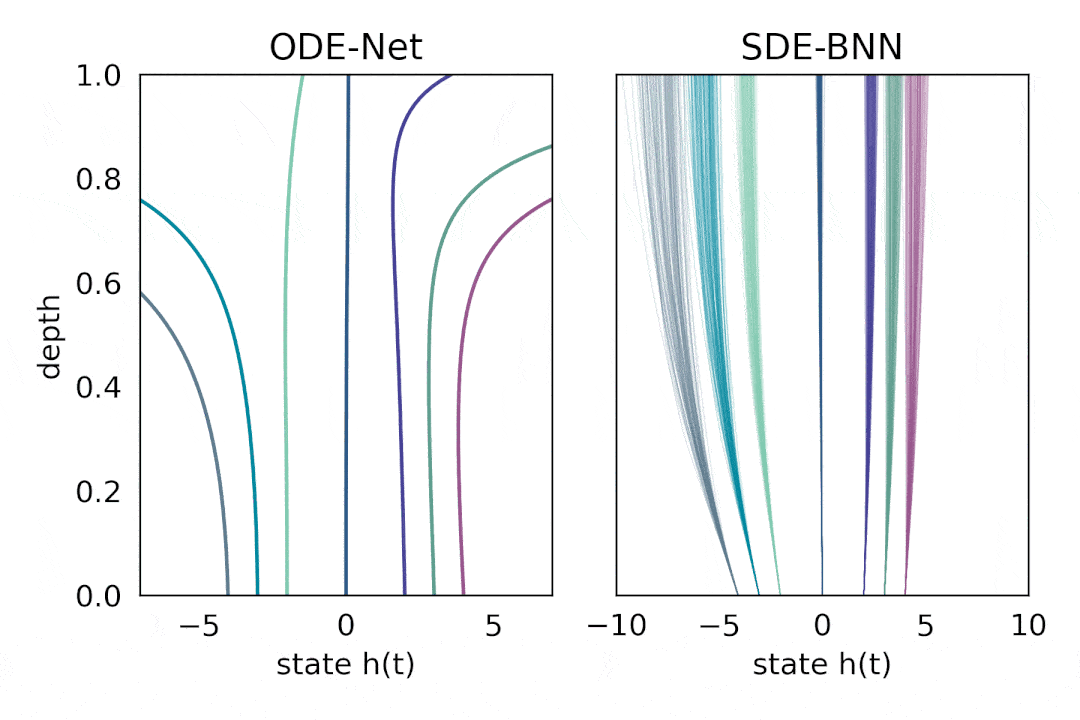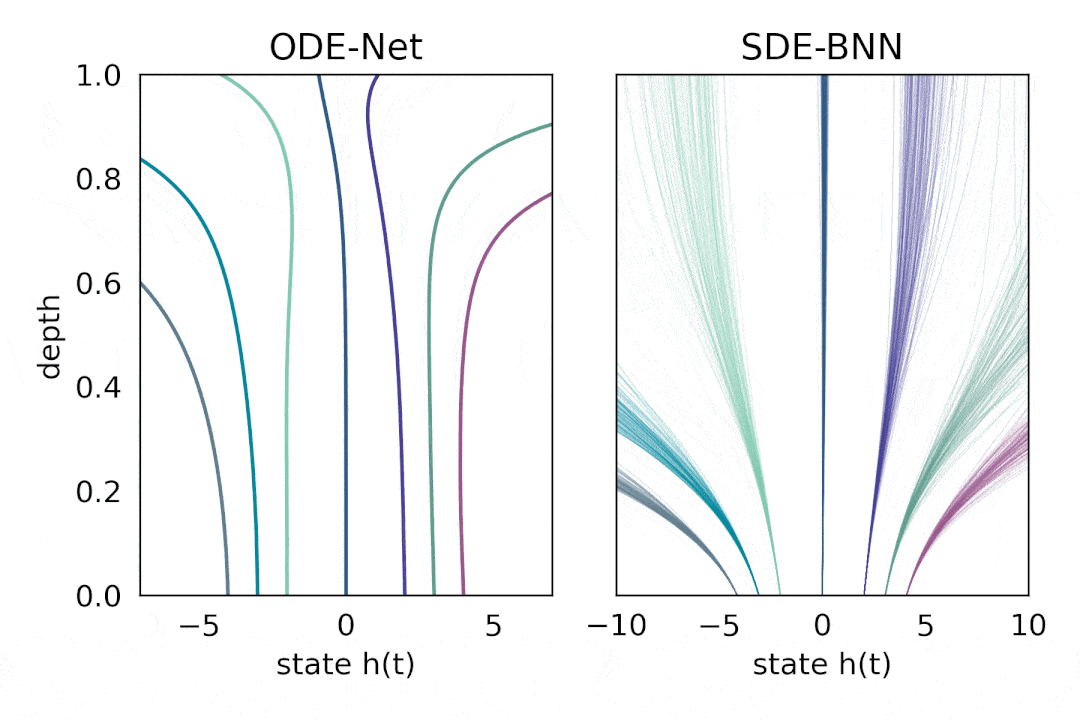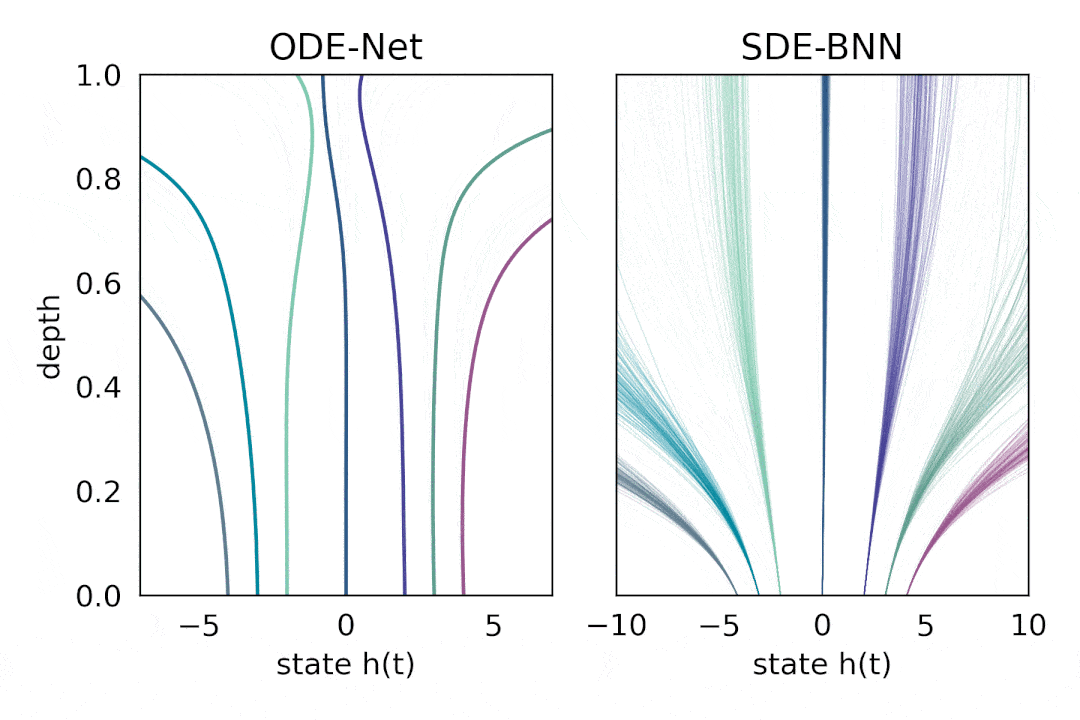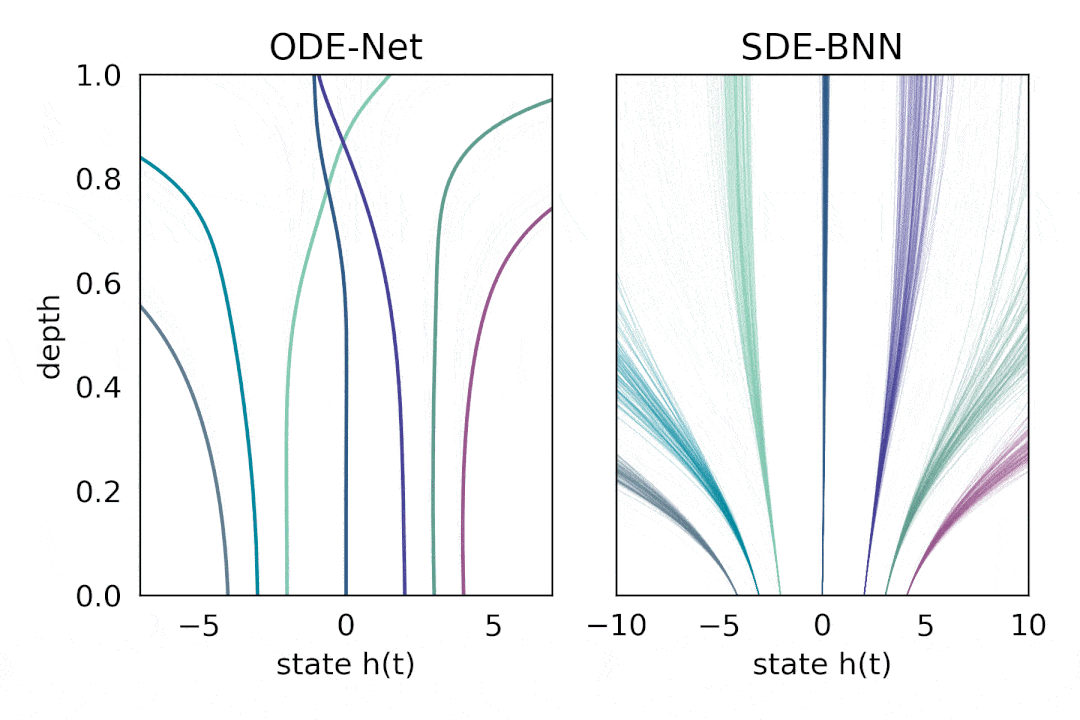
文章图片
无限深度贝叶斯神经网络(BNN)
标准离散深度残差网络可以被定义为以下形式的层的组合:

文章图片
其中 t 是层索引 ,
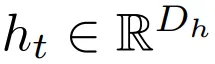
文章图片
表示 t 层隐
藏单元激活向量 , 输入 h_0 = x ,
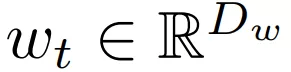
文章图片
表示 t 层的参数 , 在离散设置中
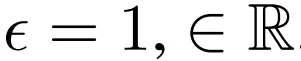
文章图片
该研究通过设置
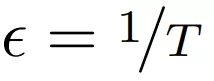
文章图片
并将极限
设为

文章图片
来构建残差网络的连续深度变体 。这样产生一个微分方程 , 该方程将隐藏单元进化描述为深度 t 的函数 。由于标准残差网络每层使用不同的权重进行参数化 , 因此该研究用 w_t 表示第 t 层的权重 。 此外该研究还引入一个超网络(hypernetwork) f_w , 它将权重的变化指定为深度和当前权重的函数 。 然后将隐藏单元激活函数的进化和权重组合成一个微分方程:
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。