
文章图片
权重先验过程:该研究使用 Ornstein-Uhlenbeck (OU) 过程作为权重先验 , 该过程的特点是具有漂移(drift)和弥散(diffusion)的 SDE:
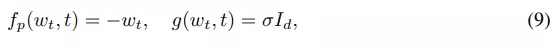
文章图片
权重近似后验使用另一个具有以下漂移函数的 SDE 隐式地进行参数化:
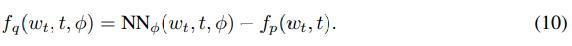
文章图片
然后该研究在给定输入下评估了该网络需要边缘化权重和隐藏单元轨迹(trajectory) 。 这可以通过简单的蒙特卡罗方法来完成 , 从后验过程中采样权重路径 {w_t} , 并在给定采样权重和输入的情况下评估网络激活函数 {h_t} 。 这两个步骤都需要求解一个微分方程 , 两步可以通过调用增强状态 SDE 的单个 SDE 求解器同时完成:
为了让网络拟合数据 , 该研究最大化由无限维 ELBO 给出的边缘似然(marginal likelihood)的下限:
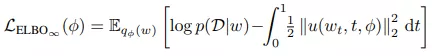
文章图片
采样权重、隐藏激活函数和训练目标都是通过一次调用自适应 SDE 求解器同时计算的 。
减小方差的梯度估计
该研究使用 STL(sticking the landing) 估计器来替换 path 空间 KL 中的原始估计器以适应 SDE 设置:
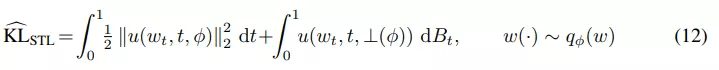
文章图片
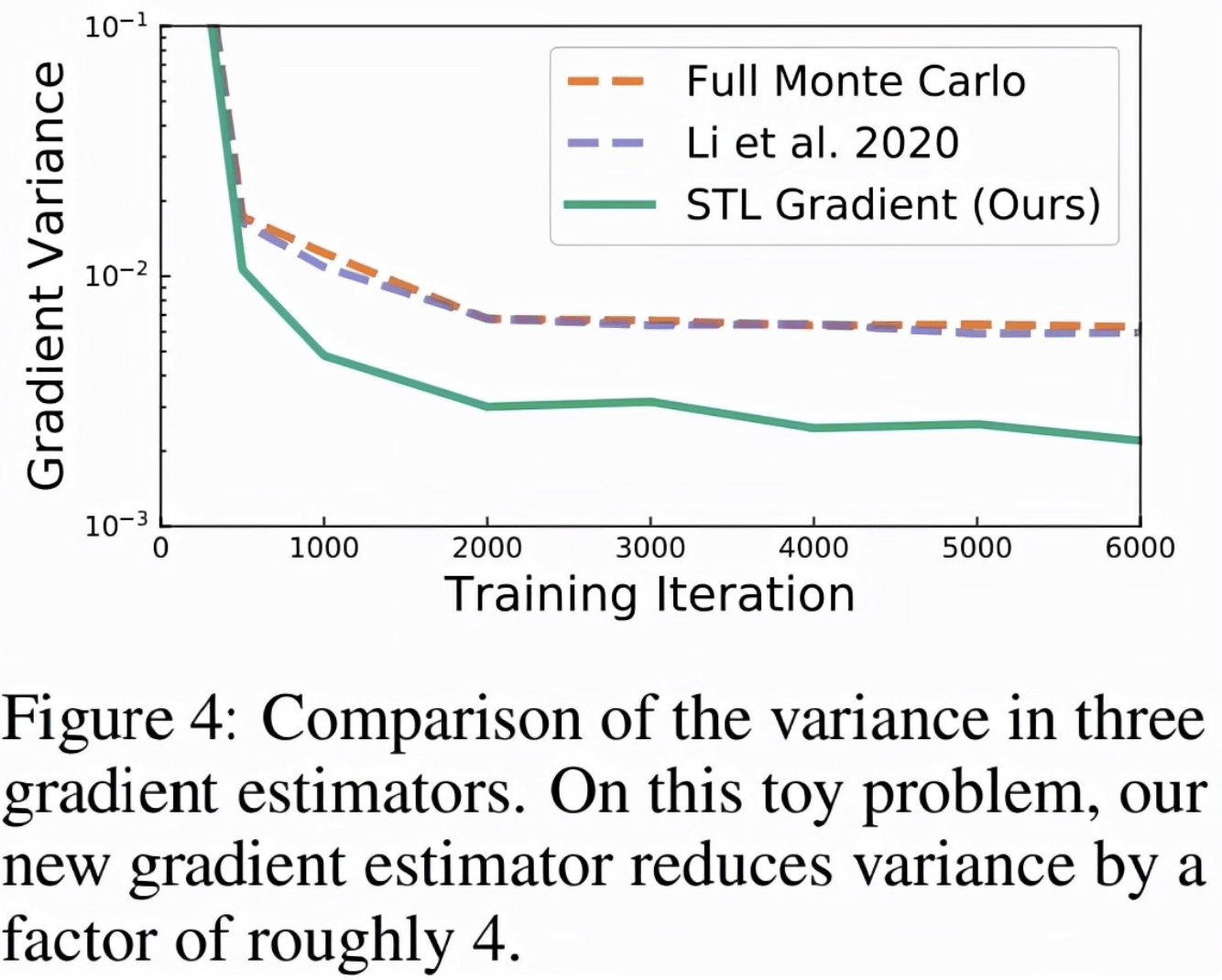
等式 (12) 中的第二项是鞅(martingale) , 期望值为零 。 在之前的工作中 , 研究者仅对第一项进行了蒙特卡罗估计 , 但该研究发现这种方法不一定会减少梯度的方差 , 如下图 4 所示 。
文章图片
因为该研究提出的近似后验可以任意表达 , 研究者推测如果参数化网络 f_w 的表达能力足够强 , 该方法可在训练结束时实现任意低的梯度方差 。
图 4 显示了多个梯度估计器的方差 , 该研究将 STL 与「完全蒙特卡罗(Full Monte Carlo)」估计进行了比较 。 图 4 显示 , 当匹配指数布朗运动时 , STL 获得的方差比其他方案低 。 下表 4 显示了训练性能的改进 。

文章图片
实验
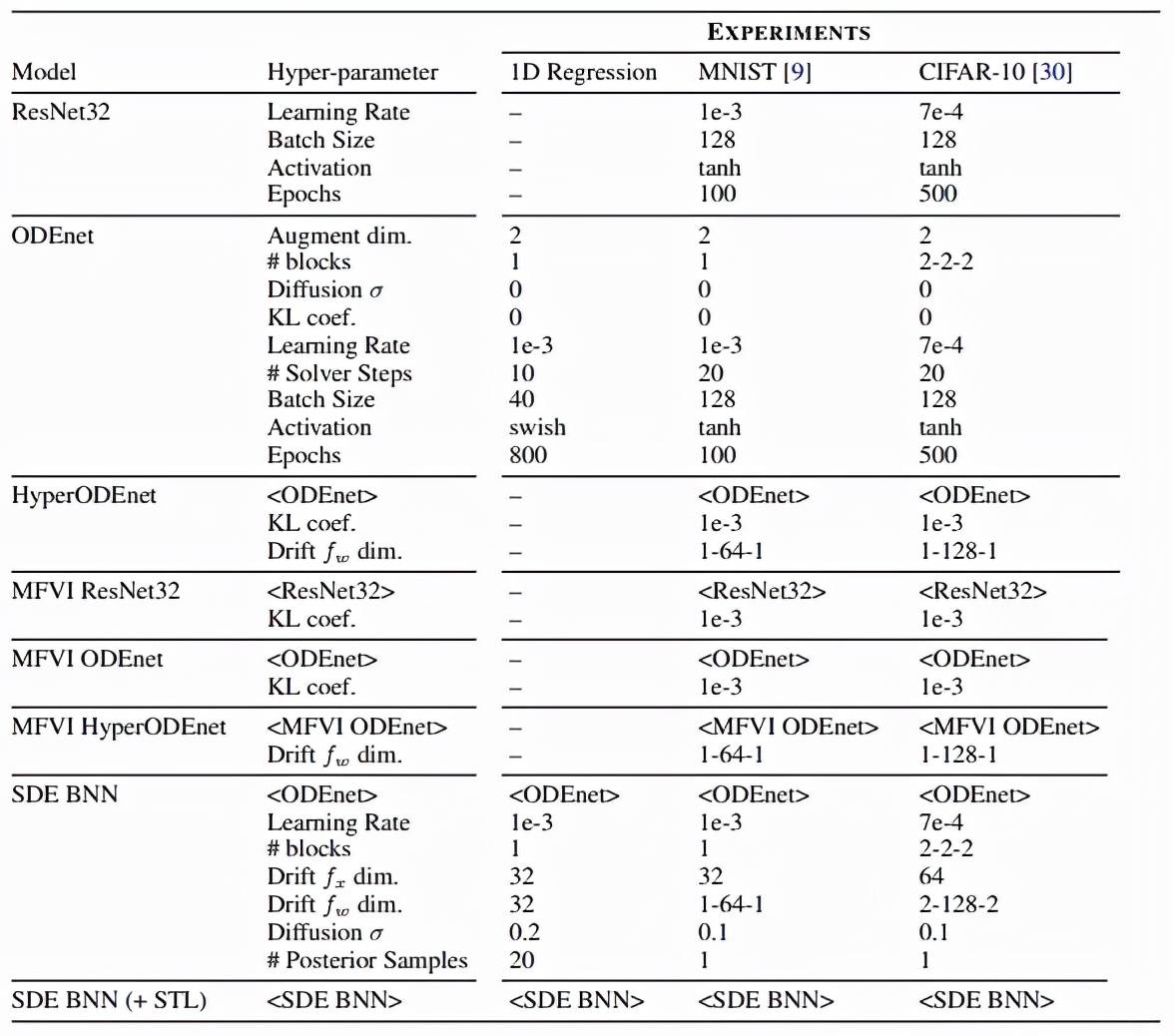
该研究的实验设置如下表所示 , 该研究在 MNIST 和 CIFAR-10 上进行了 toy 回归、图像分类任务 , 此外他们还研究了分布外泛化任务:
文章图片
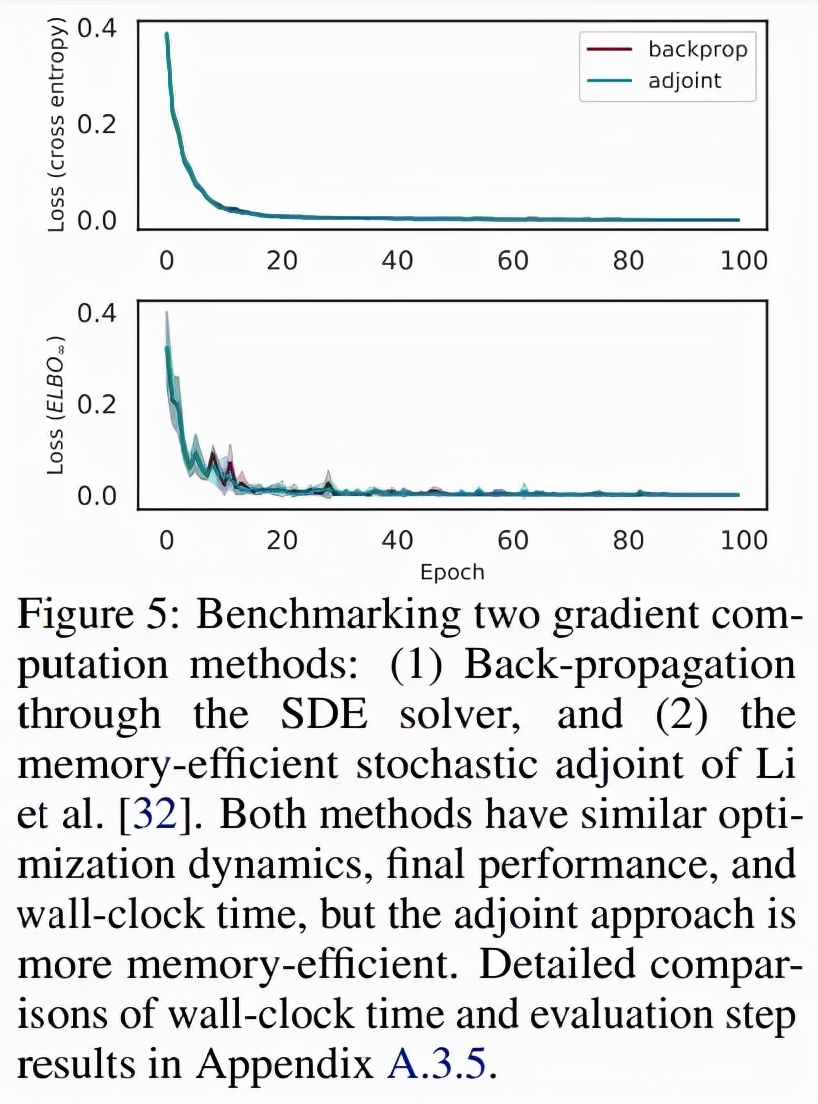
为了对比求解器与 adjoint 的反向传播 , 研究者比较了固定和自适应步长的 SDE 求解器 , 并比较了 Li 等人提出的随机 adjoint 之间的比较 ,图 5 显示了这两种方法具有相似的收敛性:
文章图片
1D 回归
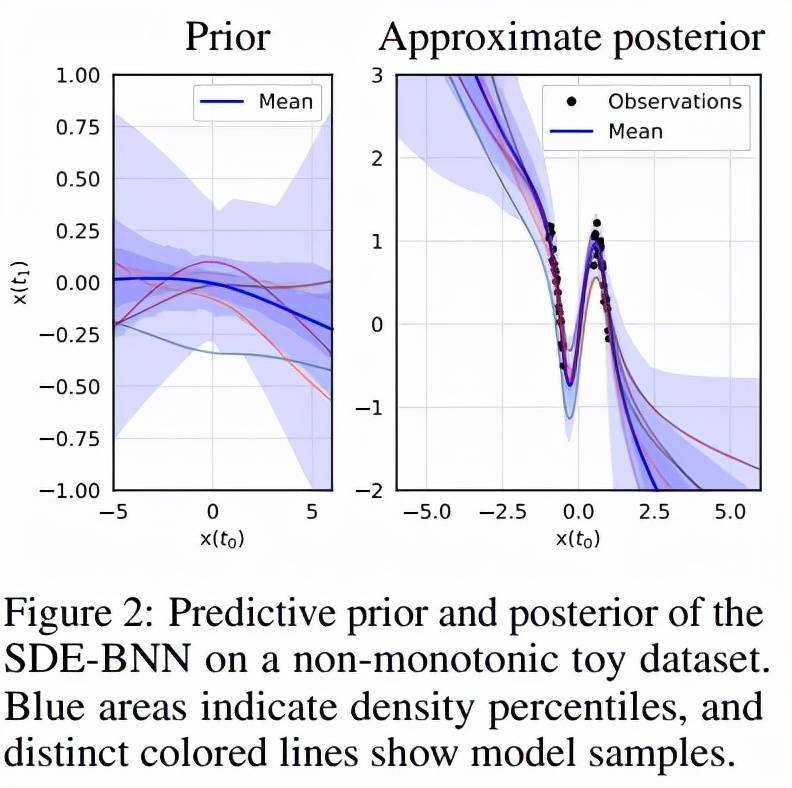
该研究首先验证了 SDE-BNN 在 1D 回归问题上的表现 。 以弥散过程的样本为条件 , 来自 1D SDE-BNN 的每个样本都是从输入到输出的双向映射 。 这意味着从 1D SDE-BNN 采样的每个函数都是单调的 。 为了能够对非单调函数进行采样 , 该研究使用初始化为零的 2 个额外维度来增加状态 。 图 2 显示了模型在合成的非单调 1D 数据集上学习了相当灵活的近似后验 。
文章图片
图像分类
表 1 给出了图像分类实验的结果 。 SDE-BNN 通常优于基线 , 由结果可得虽然连续深度神经 ODE (ODEnet) 模型可以在标准残差网络上实现类似的分类性能 , 但校准(calibration)较差 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。