本节我们首先了解一下经典的预测编码方法是如何学习层次化的背景知识的 。 如上一节中分析 , 人类的大脑通常可以利用其对过去环境的现有表征以及关于环境如何变化的约束条件 , 对环境的当前状态做出非常好的预测 。 而预测编码模型则是通过生成方式来预测感觉输入 。 一般的 , 这种生成方式构建为一个层次化的结构:上层预测下层的输出(即上层的输入) , 任何预测误差都提供信息来指导上层的学习 。 预测编码模型通过减少各层的预测误差来构建层次化的表征 , 即表征层次结构(Representation hierarchies) , 具体包括两类方法:第一类方法是构建越来越抽象的特征层次 , 通过在层次结构的后期使用更大的输入上下文信息(input context)来实现 , 类似于卷积网络 。 第二类方法是像在泰勒级数展开中一样学习高阶误差的层次结构 。 我们在这一章节具体介绍一种第一类方法 , 即 Rao/Ballard 模型 。
Rao/Ballard 的经典文献 [5] 中使用三级表示层次结构对初级视皮层末梢神经感受野模型进行建模 , 其中来自更上层的反馈传达对前一层神经活动的预测 。 例如 , 将最下层的预测活动与实际活动(原始感官输入)进行比较 。 预测误差是一个层的输出 , 并被转发到下一个更高的层 。 在层次结构中 , 有两类神经元:内部表示神经元和预测误差神经元 。 在预测中间层表征时 , 通过让最上层表征使用相邻的空间上下文对结束停止(End-stopping)进行建模 。 最上层表征为空间更大的上下文构建表示 。 该模型是围绕预测元素(predictive element , PE)建立的 。 人们可以将预测元素视为大脑中的一个处理阶段或皮质层 。 在深度学习术语中 , 它由两个执行互补功能的神经层组成 , 并通过前馈和反馈连接连接 。
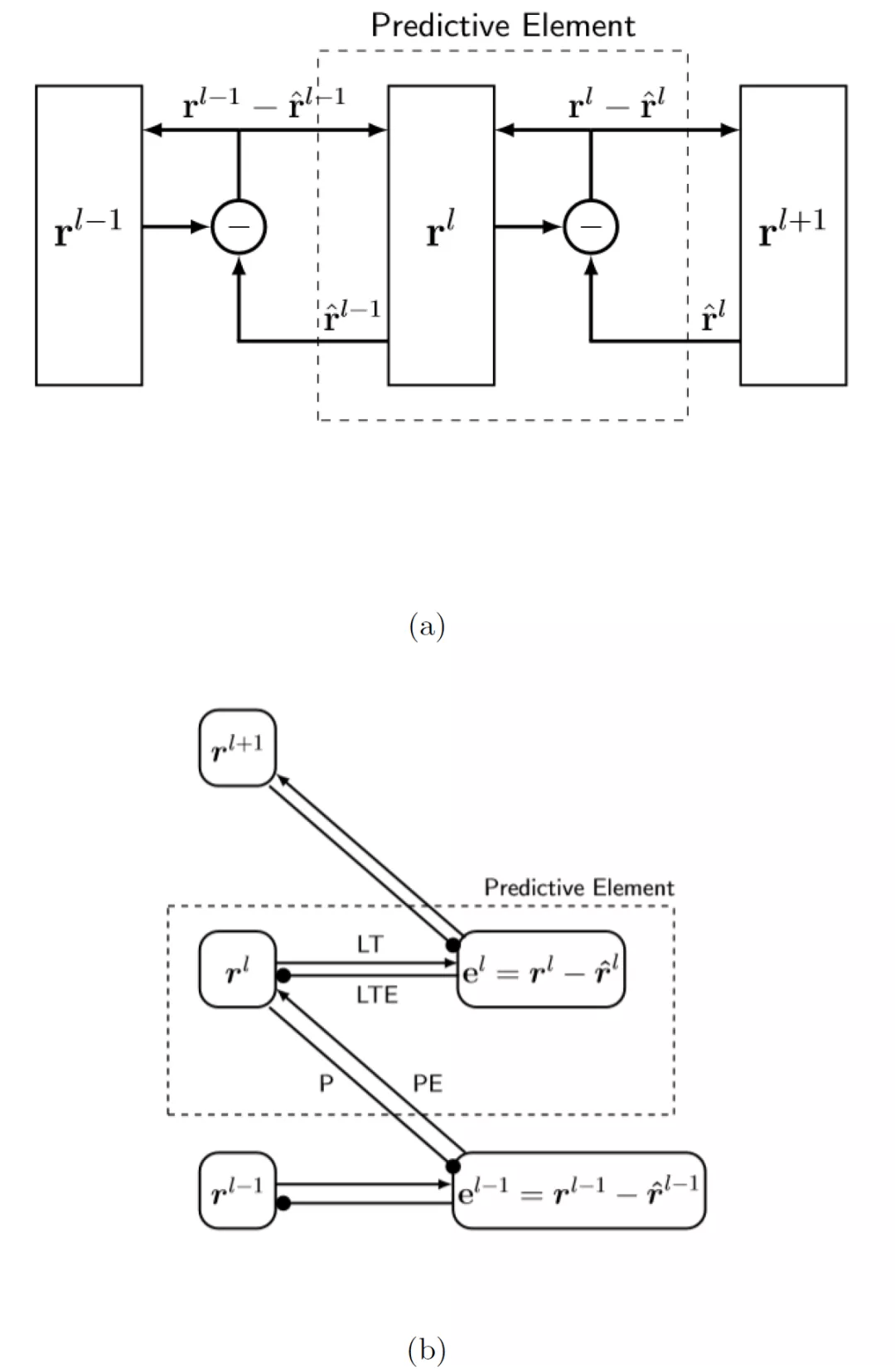
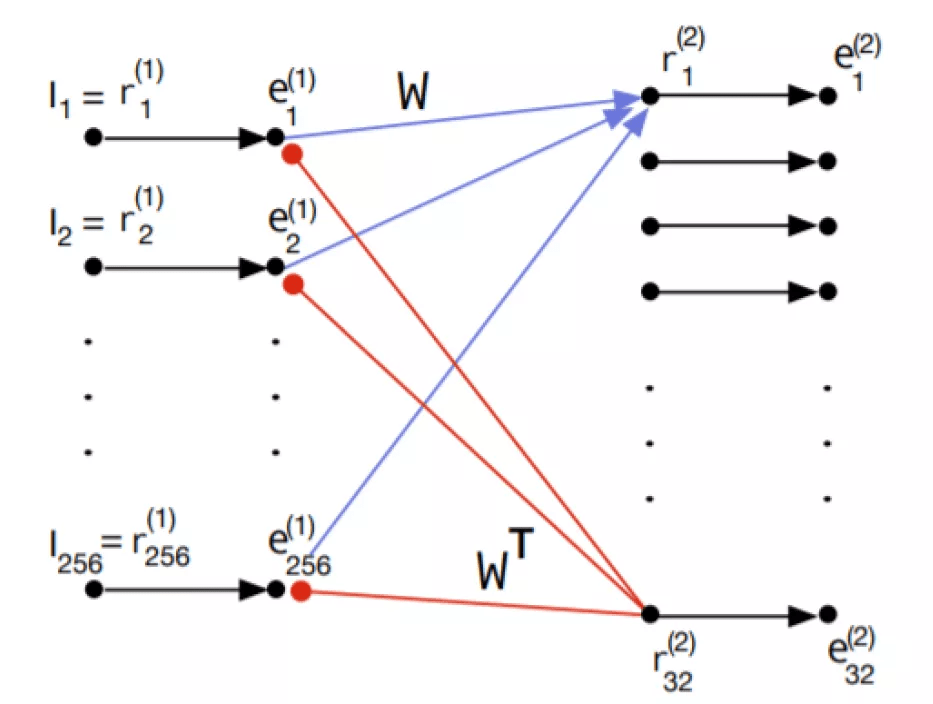
为了方便理解 , 我们给出 PE 的图形化展示 。 将 PE 堆叠成层次结构(图 1(a)) 。 PE 从层次结构中的前一层接收预测误差(通过前向连接) , 并以先验概率的形式(通过后向连接)向前一层发送预测 。 图 1(a)给出信息流的原始视图 。 第 l+1 层学习第 l 层的变换表示 , 从而提高其对第 l 层活动的预测性能 。 r(l)表示输入的假设原因 。 不同的层 l 以越来越高的描述级别提供相同原因的不同表示 。 每一层的表达都表现为形成该层的神经元向量的一组激活水平 。 图 1(b)中的视图显示相邻层之间的交互遵循一个约束协议 , 即 Rao-Ballard 协议 。 在我们的表示中 , 有四种连接类型:预测(prediction , P)、预测误差(prediction error , PE)、横向目标(lateral target , LT)和横向目标误差(lateral target error , LTE) 。 层输出是由 PE 连接提供的信息 。 P 和 PE 为完全连接 , LT 和 LTE 为点对点连接(见图 2) 。 表示模块仅与预测误差模块通信 , 预测误差模块仅与表示模块通信 。 此外 , 预测误差神经元在层次结构中从不向下投射 , 内部表征神经元在层次结构中从不向上投射 。
文章图片
图 1:(a)预测 PE 的 Rao/Ballard 图 。 虚线框中包含的预测元素是预测编码层次结构的构建块 。 围绕减号的圆表示计算预测误差的误差单位向量;(b) 使 Rao-Ballard 协议更加清晰的数据流图 。 e^l 明确预测误差和水平 。 圆箭头表示减法 。 与预测元素关联的四个连接已标记
文章图片
图 2. PE 预测单元 。 e 表示残差单元 , r 表示表征单元 , I 表示输入 。 黑色的小圆圈代表神经元 。 以实心圆结尾的红色箭头表示减法反馈抑制 。 红色箭头表示 P 连接 , 蓝色箭头表示 PE 连接 , 黑色箭头表示 LT 连接
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。