机器之心报道
编辑:张倩
从 GPT-3 开始 , 一种新的范式开始引起大家的关注:prompt 。 这段时间 , 我们可以看到大量有关 prompt 的论文出现 , 但多数还是以 NLP 为主 。 那么 , 除了 NLP , prompt 还能用到其他领域吗?对此 , 清华大学计算机系副教授刘知远给出的答案是:当然可以 。

文章图片
图源:https://www.zhihu.com/question/487096135/answer/2143082483?utm

文章图片
论文链接:https://arxiv.org/pdf/2109.11797.pdf
在细粒度图像区域 , 定位自然语言对于各种视觉语言任务至关重要 , 如机器人导航、视觉问答、视觉对话、视觉常识推理等 。 最近 , 预训练视觉语言模型(VL-PTM)在视觉定位任务上表现出了巨大的潜力 。 通常来讲 , 一般的跨模态表示首先以自监督的方式在大规模 image-caption 数据上进行预训练 , 然后进行微调以适应下游任务 。 VL-PTM 这种先预训练再微调的范式使得很多跨模态任务的 SOTA 被不断刷新 。
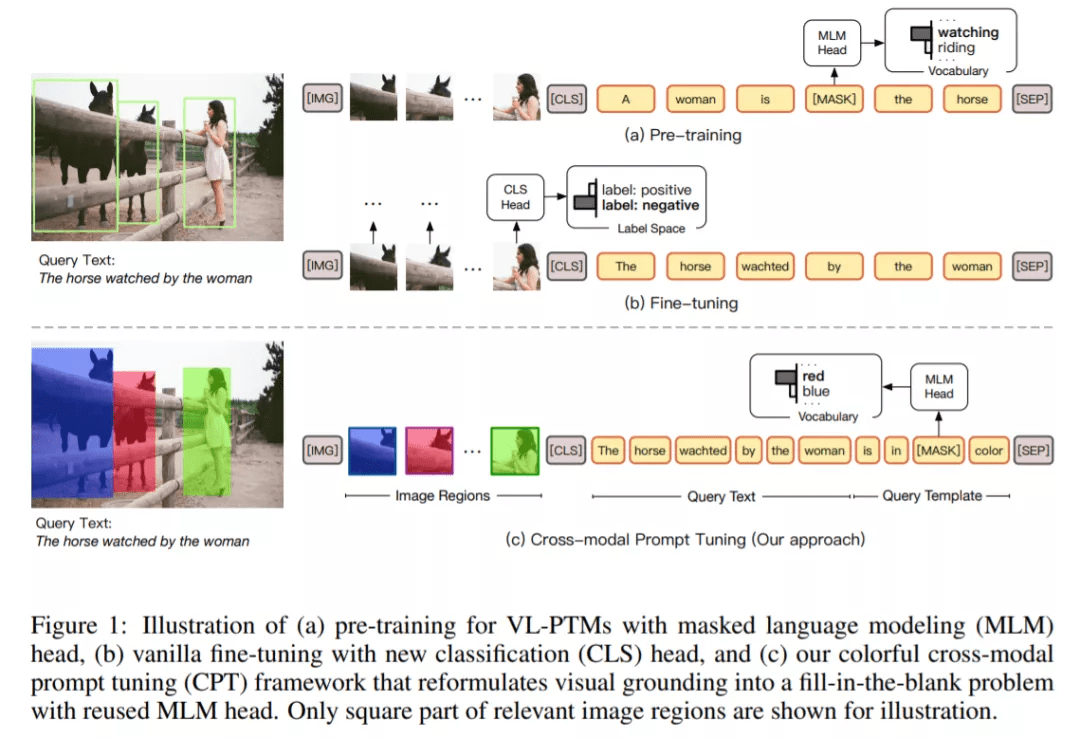
但尽管如此 , 清华大学、新加坡国立大学的研究者还是注意到 , VL-PTM 的预训练与微调的 objective form 之间存在显著差异 。 如下图 1 所示 , 在预训练期间 , 多数 VL-PTM 都是基于掩码语言建模目标进行优化 , 试图从跨模态上下文恢复 masked token 。 然而 , 在微调期间 , 下游任务通常通过将 unmasked token 表示归为语义标签来执行 , 这里通常会引入针对特定任务的参数 。 这种差异降低了 VL-PTM 对下游任务的适应能力 。 因此 , 激发 VL-PTM 在下游任务中的视觉定位能力需要大量标记数据 。
文章图片
在这篇论文中 , 受到自然语言处理领域的预训练语言模型进展启发 , 研究者提出了一种调整 VL-PTM 的新范式——CPT( Cross-modal Prompt Tuning 或 Colorful Prompt Tuning) 。 其中的核心要点是:通过在图像和文字中添加基于色彩的共指标记(co-referential marker) , 视觉定位可以被重新表述成一个填空题 , 从而尽可能缩小预训练和微调之间的差异 。
如图 1 所示 , 为了在图像数据中定位自然语言表达 , CPT 由两部分构成:一是用色块对图像区域进行唯一标记的视觉 sub-prompt;二是将查询文本放入基于色彩的查询模板的一个文本 sub-prompt 。 针对目标图像区域的显式定位可以通过从查询模板中的 masked token 中恢复对应颜色文本来实现 。
通过缩小预训练和微调之间的差距 , 本文提出的 prompt tuning 方法使得 VL-PTM 具备了强大的 few-shot 甚至 zero-shot 视觉定位能力 。 实验结果表明 , prompted VL-PTMs 显著超越了它们的 fine-tuned 竞争对手 。
本文的贡献主要体现在两个方面:
1. 提出了一种用于 VL-PTM 的跨模态 prompt tuning 新范式 。 研究者表示 , 据他们所知 , 这是 VL-PTM 跨模态 prompt tuning+ zero-shot、few-shot 视觉定位的首次尝试;
2. 进行了全面的实验 , 证明了所提方法的有效性 。
CPT 框架细节
视觉定位的关键是建立图像区域和文本表达之间的联系 。 因此 , 一个优秀的跨模态 prompt tuning 框架应该充分利用图像和文本的共指标记 , 并尽可能缩小预训练和微调之间的差距 。
为此 , CPT 将视觉定位重新构建为一个填空问题 。 具体来说 , CPT 框架由两部分构成:一是用色块对图像区域进行唯一标记的视觉 sub-prompt;二是将查询文本放入基于色彩的查询模板的一个文本 sub-prompt 。 有了 CPT , VL-PTM 可以直接通过用目标图像区域的彩色文本填充 masked token 来定位查询文本 , 目标图像区域的 objective form 与预训练相同 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。