用于分割的视觉 Transformer
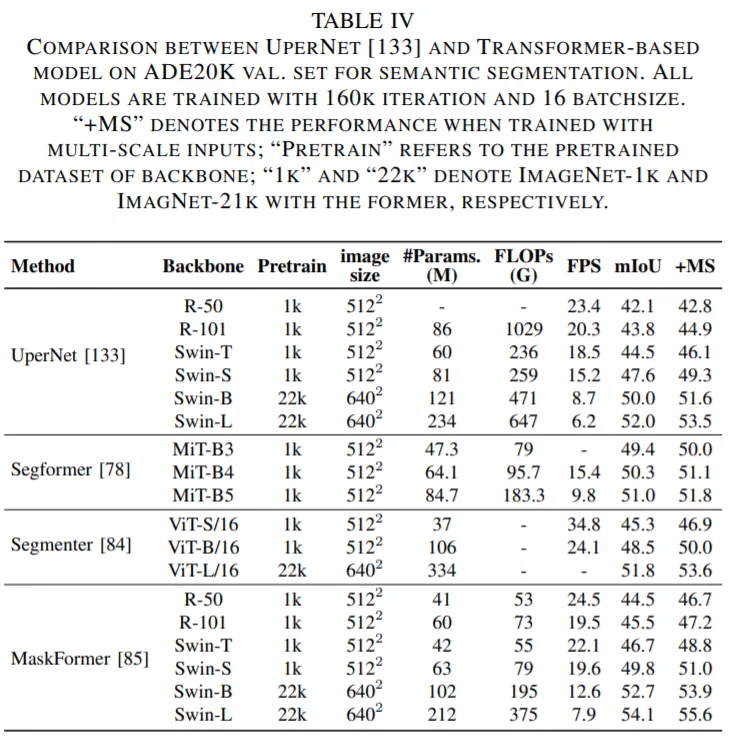
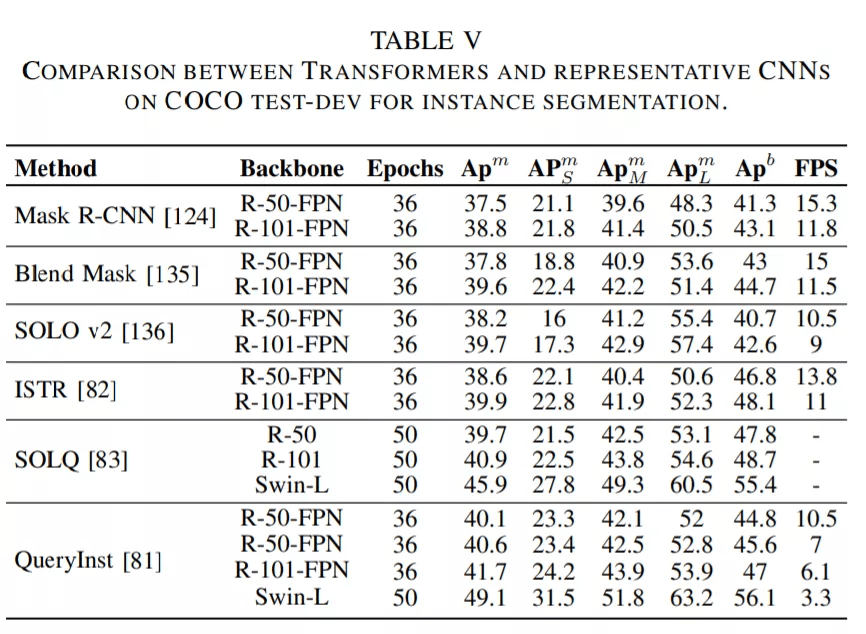
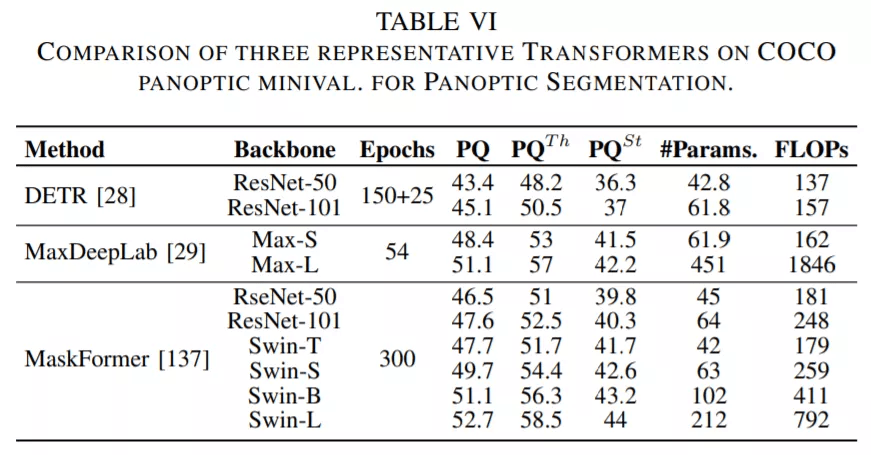
论文第 V 章主要介绍了用于分割的 Transformer 。 按照分割方式的不同 , 这些 Transformer 可以被分为两类:基于 patch 的 Transformer 和基于查询的 Transformer 。 后者可以进一步分解为带对象查询的 Transformer 和带掩码嵌入的 Transformer 。 下面这些表格展示了这些 Transformer 的性能数据 。
文章图片
文章图片
文章图片
在梳理了这一部分的进展之后 , 研究者得出了以下结论:
对于分割任务 , 编码器 - 解码器 Transformer 模型可以通过一系列可学习的掩码嵌入将三个分割子任务统一为一个掩码预测问题[29], [84], [137] 。 这种无框(box-free)方法在多个基准上实现了最新的 SOTA[137] 。 此外 , 基于 box 的 Transformer 的特定混合任务级联模型被证明在实例分割任务中达到了更高的性能 。
关于视觉 Transformer 的几个关键问题
Transformer 是如何打通语言和视觉的?
Transformer 最初是为机器翻译任务而设计的 。 在语言模型中 , 句子中的每一个词都被看作表示高级、高维语义信息的一个基本单元 。 这些词可以被嵌入到低维向量空间表示中 , 叫做词嵌入 。 在视觉任务中 , 图像的每个像素都是低级、低维语义信息 , 与嵌入特征不匹配 。 因此 , 将 Transformer 用到视觉任务中的关键是建立图像到向量的转换 , 并保持图像的特点 。 例如 , ViT[27]借助强松弛条件将图像转换为包含多个低水平信息的 patch 嵌入 , Early Conv. [50] 和 CoAtNet [37] 利用卷积提取高级信息 , 同时降低 patch 的冗余特征 。
Transformer、自注意力和 CNN 之间的关系
从卷积的角度来看 , 其归纳偏置主要表现为局部性、平移不变性、权重共享和稀疏连接 。 这类简单的卷积核可以有效地执行模板匹配 , 但由于归纳偏置强 , 其上界要低于 Transformer 。
从自注意力机制的角度来看 , 理论上 , 当给定足够数量的头时 , 它可以表示任何卷积层 。 这种 fully-attentional 操作可以交替地结合局部和全局层面的注意力 , 并根据特征之间的关系动态地生成注意力权重 。 尽管如此 , 它的实用性还是不如 SOTA CNN , 因为其精度较低 , 计算复杂度较高 。
从 Transformer 的角度来看 , Dong 等人证明 , 当在没有短连接或 FFN 的深层上训练时 , 自注意力层表现出强大的「token uniformity」归纳偏置 。 结果表明 , Transformer 由两个关键部分组成:一个聚合 token 之间关系的自注意力层;一个提取输入特征的 position-wise FFN 。 虽然 Transformer 具有强大的全局建模能力 , 卷积可以有效地处理低级特征[37] , [50] , 增强 Transformer 的局部性[45] , [70] , 并通过填充(padding)来附加位置特征[48] , [49] , [102] 。
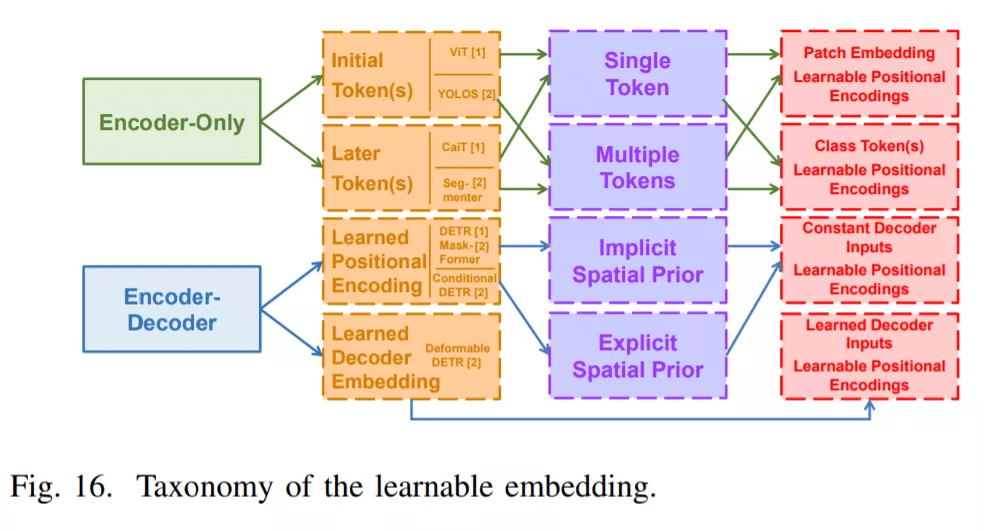
不同视觉任务中的可学习嵌入
Transformer 模型利用可学习嵌入来执行不同的视觉任务 。 从监督任务的视角来看 , 这些嵌入可以被分为类 token、对象、查询和掩码嵌入 。 从结构的角度来看 , 它们之间存在着内在的联系 。 最近的 Transformer 方法主要采用两种不同的模式:仅编码器和编码器 - 解码器结构 。 每个结构由三个层次的嵌入应用组成 , 如下图 16 所示 。
文章图片
从位置层面来看 , 在仅编码器 Transformer 中学习的嵌入的应用被分解为初始 token 和后期 token , 而学习的位置编码和学习的解码器输入嵌入被用于编码器 - 解码器结构 。 从数量层面来看 , 仅编码器的设计应用了不同数量的 token 。 例如 , ViT [27] , [38]系列和 YOLOS [73]在初始层中添加了不同的数字 token , 而 CaiT [40]和 Segmenter [84]则利用这些 token 来表示不同任务中最后几层的特征 。 在编码器 - 解码器结构中 , 所学习的解码器的位置编码 (对象查询[28] , [70] 或掩码嵌入 [137]) 被显式地 [28] , [137] 或隐式地 [69] , [70] 附加到解码器输入中 。 与恒定输入不同 , 可变形 DETR [67]采用学到的嵌入作为输入 , 并关注编码器输出 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。