机器之心报道
编辑:张倩、杜伟
在这篇论文中 , Yang Liu 等几位研究者全面回顾了用于三个基本 CV 任务(分类、检测和分割)的 100 多个视觉 Transfomer 。这段时间 , 计算机视觉圈有点热闹 。 先是何恺明等人用简单的掩蔽自编码器(MAE)证明了 Transformer 扩展到 CV 大模型的光明前景;紧接着 , 字节跳动又推出了部分指标超过 MAE 的新方法——iBOT , 将十几项视觉任务的 SOTA 又往前推了一步 。 这些进展给该领域的研究者带来了很大的鼓舞 。
在这样一个节点 , 我们有必要梳理一下 CV 领域 Transformer 模型的现有进展 , 挖掘其中有价值的经验 。 因此 , 我们找到了中国科学院计算技术研究所等机构刚刚发布的一篇综述论文 。 在这篇论文中 , Yang Liu 等几位研究者全面回顾了用于三个基本 CV 任务(分类、检测和分割)的 100 多个视觉 Transfomer , 并讨论了有关视觉 Transformer 的一些关键问题以及有潜力的研究方向 , 是一份研究视觉 Transformer 的详尽资料 。

文章图片
论文链接:https://arxiv.org/pdf/2111.06091.pdf
本文是对该综述的简要介绍 。
论文概览
Transformer 是一种基于注意力的架构 , 在序列建模和机器翻译等任务上表现出了惊人的潜力 。 如下图 1 所示 , Transformer 已经逐渐成为 NLP 领域主要的深度学习模型 。 最近流行的 Transformer 模型是一些自监督预训练模型 , 它们利用充足的数据进行预训练 , 然后在特定的下游任务中进行微调 [2]–[9] 。 生成预训练 Transformer(GPT)家族 [2]– [4] 利用 Transformer 解码器来执行自回归语言建模任务;而使用双向编码器的 Transformer(BERT)[5]及其变体 [6], [7] 是在 Transformer 编码器上构建的自编码器语言模型 。
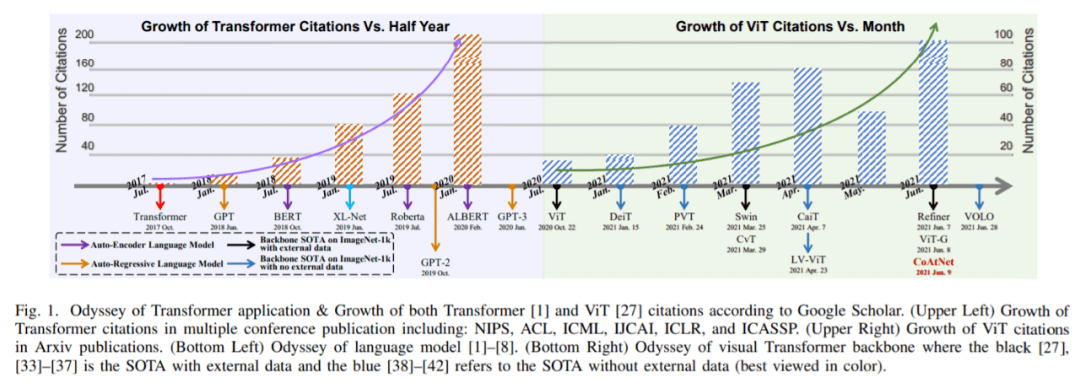
文章图片
在计算机视觉领域 , 卷积神经网络(CNN)一直占据主导地位 。 受 NLP 领域自注意力机制成功的启示 , 一些基于 CNN 的模型开始尝试通过空间 [14]–[16] 或通道 [17]–[19]层面的额外自注意力层来捕获长程依赖 , 而另一些模型则试图用全局 [20] 或局部自注意块[21]–[25] 来彻底替代传统的卷积 。 虽然 Cordonnier 等人在理论上证明了自注意力块的有效性[26] , 但在主流基准上 , 这些纯注意力模型仍然比不上当前的 SOTA CNN 模型 。
【何恺明MAE大火后,想梳理下视觉Transformer?这篇梳理了100多个】如上所述 , 在 vanilla Transformer 于 NLP 领域取得巨大成功之际 , 基于注意力的模型在视觉识别领域也得到了很多关注 。 最近 , 有大量研究将 Transformer 移植到 CV 任务中并取得了非常有竞争力的结果 。 例如 , Dosovitskiy et al. [27]提出了一种使用图像 patch 作为图像分类输入的纯 Transformer , 在许多图像分类基准上都实现了 SOTA 。 此外 , 视觉 Transformer 在其他 CV 任务中也实现了良好的性能 , 如检测 [28]、分割[29]、跟踪[30]、图像生成[31]、增强[32] 等 。
如图 1 所示 , 继 [27]、[28] 之后 , 研究者们又针对各个领域提出了数百种基于 Transformer 的视觉模型 。 因此 , 我们迫切地需要一篇系统性的文章来梳理一下这些模型 , 这便是这篇综述诞生的背景 。 考虑到读者可能来自很多不同的领域 , 综述作者将分类、检测和分割三种基本的视觉任务都纳入了梳理范围 。
如下图 2 所示 , 这篇综述将用于三个基本 CV 任务(分类、检测和分割)的 100 多种视觉 Transformer 方法按照任务、动机和结构特性分成了多个小组 。 当然 , 这些小组可能存在重叠 。 例如 , 其中一些进展可能不仅有助于增强图像分类骨干的表现 , 还能在检测、分割任务中取得不错的结果 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。