文章图片
图 1:与 fairseq 相比 , 对于单个 MoE 层 , Tutel 在具有 8 个 GPU 的单个 NDm A100 v4 节点上实现了 8.49 倍的加速 , 在具有 512 个 A100 GPU 的 64 个 NDm A100 v4 节点上实现了 2.75 倍的加速 。 详细设置为:batch_size = 32, sequence_length = 1,024, Top_K = 2, model_dim = 2,048, ands hidden_size = 2,048
在 Azure NDm A100 v4 群集上实现底层 all-to-all 通信优化 。 Tutel 针对 Azure NDm A100 v4 群集上的大规模 MoE 训练 , 优化了 all-to-all 聚合通信(collective communication) , 其中包括 CPU-GPU 绑定和自适应路由(AR)调整 。 在非一致存储访问结构(NUMA)系统上 , 尤其是在 NDv4 VM 上 , 正确的 CPU-GPU 绑定对于 all-to-all 性能非常关键 。 但是 , 现有的机器学习框架(TensorFlow、PyTorch 等)并未提供高效的 all-to-all 通信库 , 导致大规模分布式训练的性能下降 。
Tutel 可以自动优化绑定 , 并为用户微调提供简洁的接口 。 此外 , Tutel 在 NDm A100 v4 集群上使用了多路径技术 , 即 AR 。 对于 MoE 中的 all-to-all 通信 , 每个 GPU 通信的总数据流量规模并不会发生变化 , 但每个 GPU 之间的数据规模会随着 GPU 数量的增加而变小 。 而更小的数据规模会在 all-to-all 通信中产生更大的开销 , 导致 MoE 训练性能下降 。 借助 Azure NDm A100 v4 集群提供的 AR 技术 , Tutel 提高了小消息组的通信效率 , 并在 NDv4 系统上提供了高性能的 all-to-all 通信 。 得益于 CPU-GPU 绑定和 AR 调整 , Tutel 使用 512 个 A100 GPU , 对通常用于 MoE 训练的每次交换的数百兆字节的消息 , 实现了 2.56 倍到 5.93 倍的 all-to-all 加速 , 如图 2 所示 。

文章图片
图 2:在应用 Tutel 前后 , 具有 64 个 NDm A100 v4 节点(512 个 A100 GPU)的不同消息大小的 all-to-all 带宽 。 Tutel 使用 512 个 A100 GPU , 对大小为数百兆字节的消息实现了 2.56 倍到 5.93 倍的 all-to-all 加速 。
多样、灵活的 MoE 算法支持 。 Tutel 为最先进的 MoE 算法提供了多样化且灵活的支持 , 包括:
- 为 Top-K gating 算法设置任意 K 值(大多数实现方法仅支持 Top-1 和 Top-2 ) 。
- 不同的探索策略 , 包括批量优先路由、输入信息丢失、输入抖动 。
- 不同的精度级别 , 包括半精度(FP16)、全精度(FP32)、混合精度等(下一个版本中将支持 BF16) 。
- 不同的设备类型 , 包括 NVIDIA CUDA 和 AMD ROCm 设备等 。
Tutel 与 Meta 的 MoE 语言模型集成
此前 , Meta 就开源了自己的 MoE 语言模型 , 并利用 fairseq 实现了 MoE 。 微软亚洲研究院与 Meta 合作将 Tutel 集成到了 fairseq 工具包中 。 Meta 也一直用 Tutel 在 Azure NDm A100 v4 上训练其大型语言模型 , 该模型中基于注意力的神经架构类似于 GPT-3 。
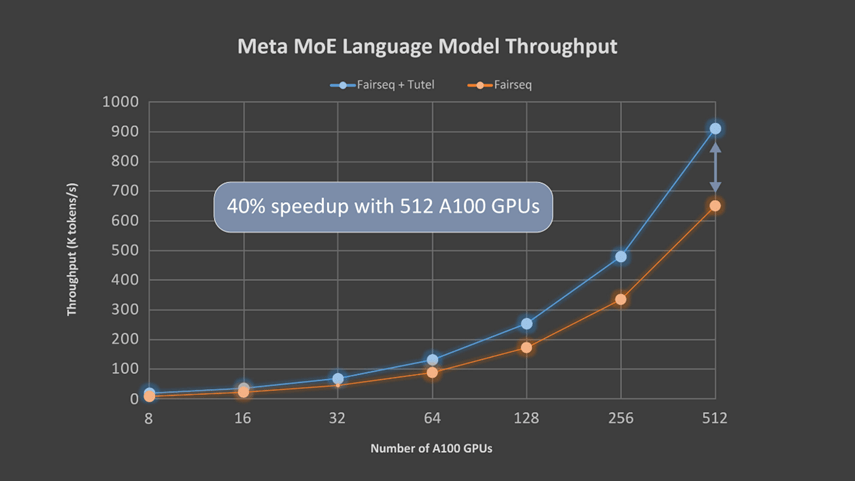
微软亚洲研究院的研究员们使用 Meta 的语言模型评估了 Tutel 的端到端性能 。 该模型有 32 个注意力层 , 每个层都有 32 个 128 维注意力头(32x128-dimension heads) 。 每 2 层中包含 1 个 MoE 层 , 而每个 GPU 都配有一名专家(expert) 。 表 1 总结了模型的详细设置参数 , 图 3 则显示了 Tutel 的加速效果 。 由于 all-to-all 通信成为瓶颈 , 所以随着 GPU 数量的增加 , Tutel 带来的改进从 8 个 A100 GPU 的 131% 提升至 512 个 A100 GPU 的 40% 。 研究员们将在下一个版本中对此做进一步优化 。
文章图片
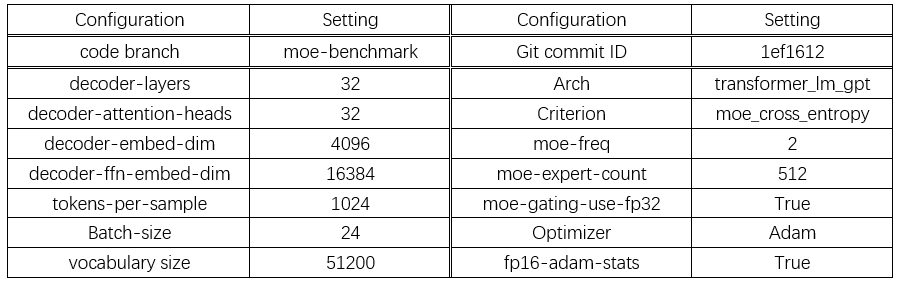
表 1:512 个 A100 (80G) GPU 的 MoE 语言模型配置
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。