
文章图片
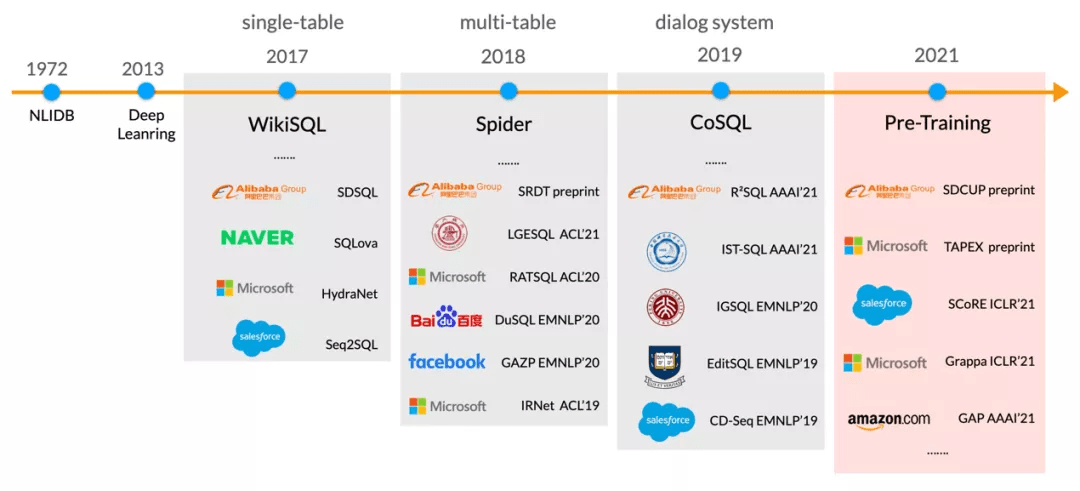
目前谷歌、微软、亚马逊等公司都在加快对相关技术的布局 。 如下图所示 , 按照目标下游任务的不同 , 预训练表格模型可以分为三大类:单轮、多轮和生成 。
- 单轮模型旨在提升下游的 Text-to-SQL 语义解析任务 , 代表工作有耶鲁的 Grappa 和亚马逊的 GAP;
- 多轮模型旨在提升基于表格的对话式语义解析任务(CoSQL) , 代表工作有微软的 SCORE 和 Element AI 的 PICARD;
- 生成模型旨在提升 Table-to-Text 和 TableQA 的 Response Generation 生成的效果 , 代表工作有 Intel 的 TableNLG 和 HIT 的 TableGPT 。
表格问答相关工作
一个表格问答系统主要由三个模块组成 , 其中:
- 自然语言理解模块主要执行语义解析算法 , 将自然语言问句转为对应可执行的 SQL 语句;
- 对话管理模块执行多轮的状态跟踪和策略优化;
- 自然语言生成模块则根据解析出的 SQL 语句和 SQL 的执行结果生成对应的回复 。
文章图片
团队除了在 WikiSQL/Spider/CoSQL 三个学术界数据集取得 SOTA 效果之外 , 也构建了该领域中文的单轮、多轮、生成的数据集 , 并且将相关技术应用于阿里云智能客服的表格问答模块 , 从产研结合的角度推动该领域的发展 。
研究动机
预训练表格模型最终的目标是为了提升下游 Text-to-SQL 任务的效果 , 如下图所示 , 在自然语言和表格的 schema 之间 , 存在这一个复杂的语义交互结构(Schema Linking) , 对于该结构的识别和建模已经成为 Semantic Parsing 任务中的重要瓶颈 。 然而 , 业界已有的表格预训练模型没有显式建模自然语言问题和表格数据之间的语义交互结构 。

文章图片
因此 , 团队提出了基于模式依存的表格预训练模型 , 为了提升模型对于不同表格模式下的鲁棒性 , 还进一步提出了基于模式知识扰动的表格预训练模型;此外 , 为了减轻数据噪音对模型的影响 , 团队还提出了基于课程学习的表格预训练模型 。
首个中文表格预训练模型SDCUP
基于模式依存的表格预训练
对于预训练表格模型来说 , 最关键的问题在于找到自然语言问题和模式之间的关联 , 又称模式链接问题 。 所以在预训练模型的训练目标中应该显式地引入这种模式链接结构 , 如图所示 , 团队引入了模式依存的方法 , 通过模型来预测问题中的哪些词应该和模式中的哪些项进行链接 , 并且这种链接关系对应 SQL 中的什么关键词 。 通过这种显示的关系建模 , 能够得到更好的问题和模式表征 , 从而提升下游 TableQA 模型的性能 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。