·宽表的结构维护麻烦 , 遇到维度数据变更的情况需要重跑宽表
·宽表需要根据业务预先定义 , 宽表可能无法满足临时新增的查询业务
StarRocks:通过星型模型适应维度变更
可以说 , 拼宽表的形式是以牺牲灵活性为代价 , 将join的操作前置 , 来加速业务的查询 。 但在一些灵活度要求较高的场景 , 比如订单的状态需要频繁改变 , 或者说业务人员的自助BI分析 , 宽表往往无法满足我们的需求 。 此时我们还需要使用更为灵活的星型或者雪花模型进行建模 。 对于星型/雪花模型的兼容度上 , StarRocks的支撑要比ClickHouse好很多 。
在StarRocks中提供了三种不同类型的join:
·当小表与大表关联时 , 可以使用boardcast join , 小表会以广播的形式加载到不同节点的内存中
·当大表与大表关联式 , 可以使用shuffle join , 两张表值相同的数据会shuffle到相同的机器上
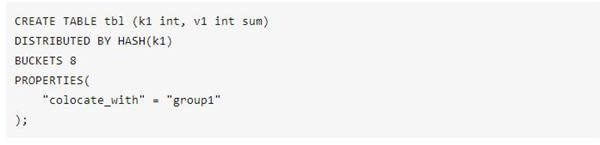
·为了避免shuffle带来的网络与I/O的开销 , 也可以在创建表示就将需要关联的数据存储在同一个colocation group中 , 使用colocation join
文章图片
目前大部分的MPP架构计算引擎 , 都采用基于规则的优化器(RBO) 。 为了更好的选择join的类型 , StarRocks提供了基于代价的优化器(CBO) 。 用户在开发业务SQL的时候 , 不需要考虑驱动表与被驱动表的顺序 , 也不需要考虑应该使用哪一种join的类型 , CBO会基于采集到的表的metric , 自动的进行查询重写 , 优化join的顺序与类型 。
高并发支撑
ClickHouse对高并发的支撑
为了更深维度的挖掘数据的价值 , 就需要引入更多的分析师从不同的维度进行数据勘察 。 更多的使用者同时也带来了更高的QPS要求 。 对于互联网 , 金融等行业 , 几万员工 , 几十万员工很常见 , 高峰时期并发量在几千也并不少见 。 随着互联网化和场景化的趋势 , 业务逐渐向以用户为中心转型 , 分析的重点也从原有的宏观分析变成了用户维度的细粒度分析 。 传统的MPP数据库由于所有的节点都要参与运算 , 所以一个集群的并发能力与一个节点的并发能力相差无几 。 如果一定要提高并发量 , 可以考虑增加副本数的方式 , 但同时也增加了RPC的交互 , 对性能和物理成本的影响巨大 。
在ClickHouse中 , 我们一般不建议做高并发的业务查询 , 对于三副本的集群 , 通常会将QPS控制在100以下 。 ClickHouse对高并发的业务并不友好 , 即使一个查询 , 也会用服务器一半的CPU去查询 。 一般来说 , 没有什么有效的手段可以直接提高ClickHouse的并发量 , 只能考虑通过将结果集写入MySQL中增加查询的并发度 。
StarRocks对高并发的支撑
相较于ClickHouse , StarRocks可以支撑数千用户同时进行分析查询 , 在部分场景下 , 高并发能力能够达到万级 。 StarRocks在数据存储层 , 采用先分区再分桶的策略 , 增加了数据的指向性 , 利用前缀索引可以快读对数据进行过滤和查找 , 减少磁盘的I/O操作 , 提升查询性能 。
在建表的时候 , 分区分桶应该尽可能的覆盖到所带的查询语句 , 这样可以有效的利用分区分桶剪裁的功能 , 尽可能的减少数据的扫描量 。 此外 , StarRocks也提供了MOLAP库的预聚合能力 。 对于一些复杂的分析类查询 , 可以通过创建物化视图进行预先聚合 , 原有几十亿的基表 , 可以通过预聚合RollUp操作变成几百或者几千行的表 , 查询时延迟会有显著下降 , 并发也会有显著提升 。
数据的高频变更
ClickHouse中的数据更新
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。