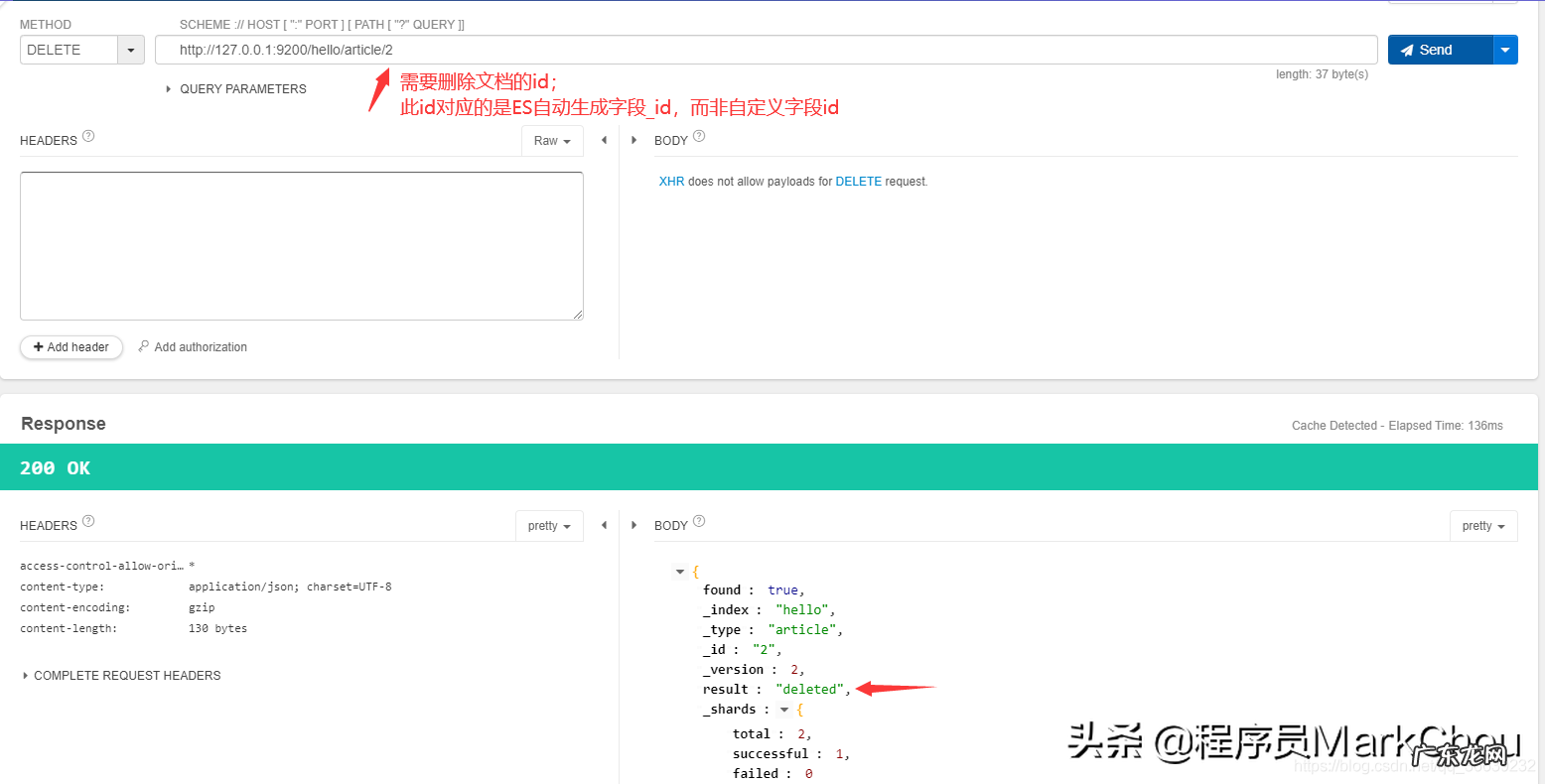
7)删除文档document---DELETE请求URL:
DELETE http://127.0.0.1:9200/hello/article/2
文章插图
8)查询文档document-----GET查询文档有三种方式:
- 根据id查询;
- 根据关键词查询
- 根据输入的内容先分词,再查询
GET http://127.0.0.1:9200/hello/article/1
文章插图
ii.根据关键字查询-term查询请求URL:
POST http://127.0.0.1:9200/hello/article/_search请求体:{"query": {"term": {"title": "搜"}}}
文章插图
iii.查询文档-querystring查询请求URL:
POSThttp://127.0.0.1:9200/hello/article/_search请求体:{"query": {"query_string": {"default_field": "title","query": "搜索服务器"}}}指定: 在哪个字段上进行查询; 要查询的内容是什么;它会把查询内容先进行分词,再进行查询

文章插图
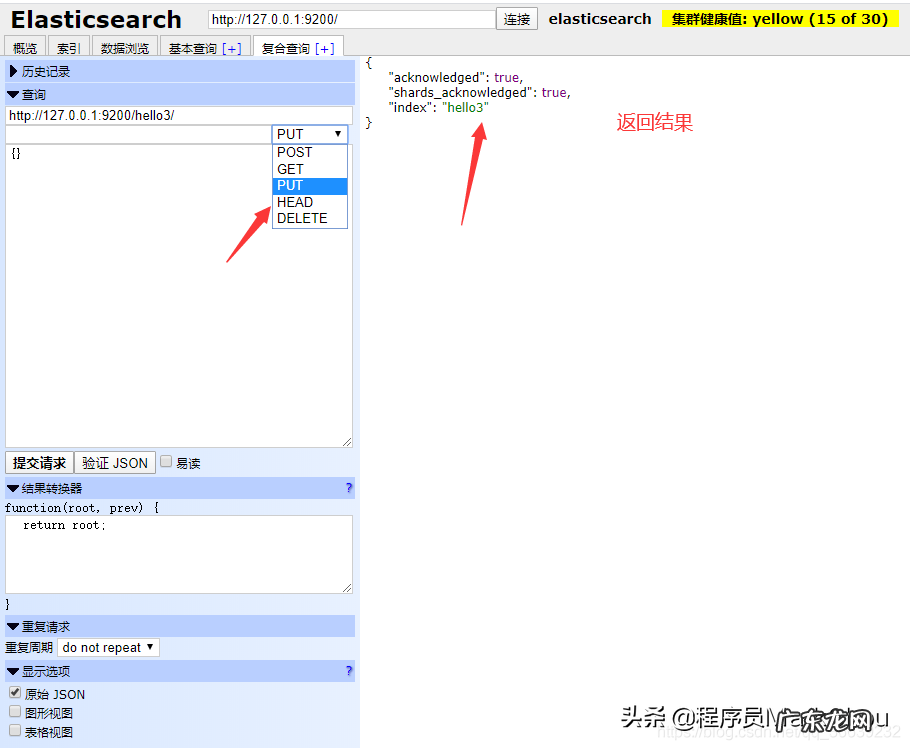
4.3使用elasticsearch-head进行es客户端操作在elasticsearch-head中集成了http请求的工具,可以提供复查查询:
文章插图
5.IK分词器和Elasticsearch集成使用上述分词器使用的是标准分词器,其对中文分词不是很友好,例如对我是程序员进行分词得到:
GET http://127.0.0.1:9200/_analyze?analyzer=standard&pretty=true&text=我是程序员"tokens":[{"token": "我", "start_offset": 0, "end_offset": 1, "type": "",…},{"token": "是", "start_offset": 1, "end_offset": 2, "type": "",…},{"token": "程", "start_offset": 2, "end_offset": 3, "type": "",…},{"token": "序", "start_offset": 3, "end_offset": 4, "type": "",…},{"token": "员", "start_offset": 4, "end_offset": 5, "type": "",…}] 我们希望达到的分词是:我、是、程序、程序员 。支持中文的分词器有很多,word分词器,庖丁解牛,Ansj分词器,下面注意说IK分词器的使用 。
5.1IK分词器的安装1)下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
2)解压,将解压后的elasticsearch文件夹拷贝到elasticsearch-5.6.8\plugins下,并重命名文件夹为analysis-ik (其他名字也可以,目的是不要重名)
3)重新启动ElasticSearch,即可加载IK分词器

文章插图
5.2IK分词器测试【gre作文教程 grep教程】IK提供两种分词ik_smart和ik_max_word
其中ik_smart为最少切分,ik_max_word为最细粒度划分 。
下面测试一下:
- 最小切分:在浏览器输入地址:
GEThttp://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=我是程序员返回结果:"tokens":[{"token": "我", "start_offset": 0, "end_offset": 1, "type": "CN_CHAR",…},{"token": "是", "start_offset": 1, "end_offset": 2, "type": "CN_CHAR",…},{"token": "程序员", "start_offset": 2, "end_offset": 5, "type": "CN_WORD",…}]- 最新切分:在浏览器输入地址:
GEThttp://127.0.0.1:9200/_analyze?analyzer=ik_max_word&pretty=true&text=我是程序员返回结果:"tokens":[{"token": "我", "start_offset": 0, "end_offset": 1, "type": "CN_CHAR",…},{"token": "是", "start_offset": 1, "end_offset": 2, "type": "CN_CHAR",…},{"token": "程序员", "start_offset": 2, "end_offset": 5, "type": "CN_WORD",…},{"token": "程序", "start_offset": 2, "end_offset": 4, "type": "CN_WORD",…},{"token": "员", "start_offset": 4, "end_offset": 5, "type": "CN_CHAR",…}]
- 五一一件有趣的事作文400字 五一的作文400字左右
- 如何磨刀视频教程 怎么磨刀教程
- 我的开学第一课作文 我的开学第一课
- 英语作文myhobby怎么写
- 极品gre红宝书是什么 gre红宝书是什么
- 2020年gre考试取消怎么退款
- 反恐精英cs1.6电脑下载教程 反恐精英cs1.6
- 读书的快乐演讲稿600字作文 读书的快乐演讲稿怎么写
- 化妆步骤的先后顺序「新手学化妆详细教程」
- 高中英语作文模板 英语作文模板
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。