其他
传统的贝叶斯优化每轮只能推荐一个超参数配置 , 因此设计并行推荐方法是一个值得考虑的问题 。 我们尝试了系统中实现的并行贝叶斯方法 , 包括 "median_imputation" 中位数插补法 , 即使用历史观察结果的中位数 , 填补并行 batch 中推荐配置的性能 , 重新训练代理模型并得到下一个并行推荐配置 , 以及 "local_penalization" 局部惩罚法 , 对并行已推荐配置在采集函数上施加局部惩罚 , 这两种方法的目的都是提高对超参数空间的探索性 。 不过经过测试 , 在本次比赛问题上这些方法的效果不佳 , 最终我们采用多次优化采集函数并去重的方式执行并行推荐 , 达到了较好的性能 。
此外 , 为增大贝叶斯优化的探索性 , 保证算法收敛 , 我们设置每次推荐时使用随机搜索的概率为 0.1 。
代码实现
初赛代码仅需调用 OpenBox 系统中的并行贝叶斯优化器 SyncBatchAdvisor , 即可实现上述功能:
from openbox import SyncBatchAdvisor
self.advisor = SyncBatchAdvisor(
config_space=self.config_space,
batch_size=5,
batch_strategy='reoptimization',
initial_trials=10,
init_strategy='random_explore_first',
rand_prob=0.1,
surrogate_type='gp',
acq_type='ei',
acq_optimizer_type='random_scipy',
task_id='thpo',
random_state=47,

文章图片
代码以图示为准
每轮执行推荐时 , 调用 advisor 的 get_suggestions 接口:
def suggest(self, suggestion_history, n_suggestions):
history_container = self.parse_suggestion_history(suggestion_history)
next_configs = self.advisor.get_suggestions(n_suggestions, history_container)
next_suggestions = [self.convert_config_to_parameter(conf) for conf in next_configs]
return next_suggestions

文章图片
代码以图示为准
决赛算法介绍
赛题理解
决赛问题在初赛的基础上 , 对每个超参数配置提供 14 轮的多精度验证结果 , 供算法提前对性能可能不佳的配置验证过程执行早停 。 同时 , 总体优化预算时间减半 , 最多只能全量验证 50 个超参数配置 , 因此问题难度大大增加 。 如何设计好的早停算法 , 如何利用多精度验证数据是优化器设计的关键 。
我们对本地公开的两个数据集进行了探索 , 发现了一些有趣的性质:
- 对于任意超参数配置 , 其第 14 轮的奖励均值位于前 13 轮置信区间内的概率为 95% 。
- 对于任意超参数配置 , 其前 13 轮中任意一轮的均值比第 14 轮均值大的概率为 50% 。
- 对于任意超参数配置 , 其 14 轮的置信区间是不断减小的 , 但均值曲线是任意波动的 。
- 在所有超参数配置之间 , 部分验证(1-13 轮)和全量验证(14 轮)均值大小关系一致的概率大于 95% 。
- 在空间中最终性能前 1% 的超参数配置之间 , 这种一致性大约在 50% 到 70% 之间 。
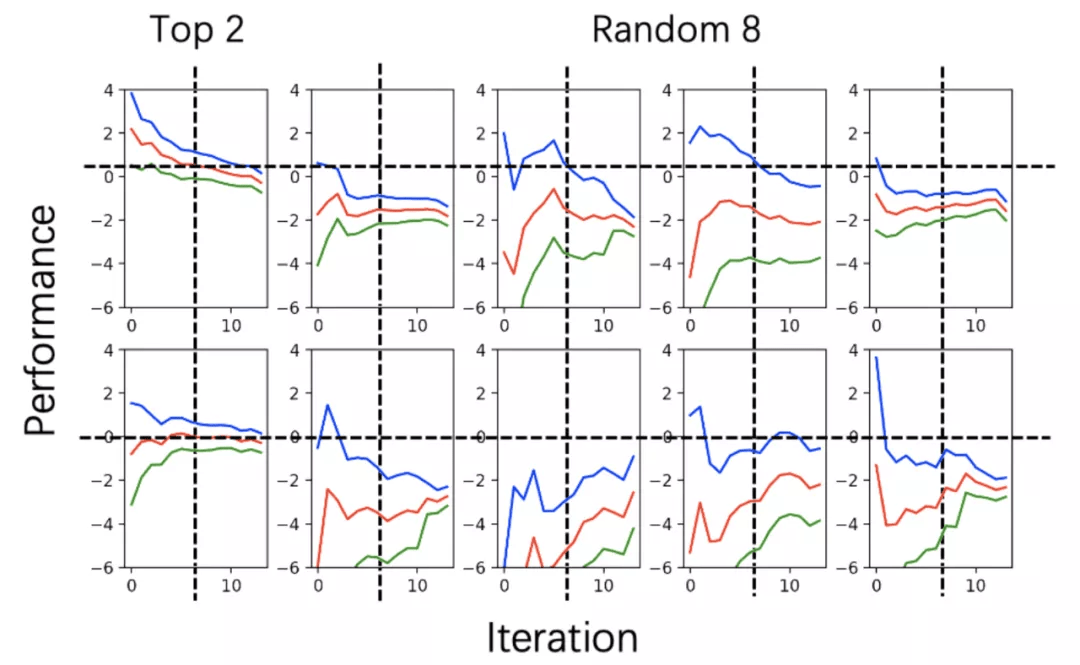
文章图片
图:data-30 搜索空间中 2 个最好配置和 8 个随机配置的奖励 - 轮数曲线 , 包含置信上界(蓝色)、均值(红色)、置信下界(绿色)曲线 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。