通过机器快捷判定舆情事件的初步情况 , 能够为人的综合判断和设计应对方案提供一个好的路线图 , 以便于舆情苗头出现之际快速发现信号、舆情发酵过程中检验应对有效性 , 以及在后期科学评判处置效果 。
情感分析又被称为情感倾向性分析或意见挖掘 , 是从用户意见中提取信息的过程 。 文本情感分析则致力于将单词、句子、段落和篇章映射到一组相对应的情感类别上 , 继而得到一个可用于划分情感状态的心理学模型 。
文本情感分析是舆情事件研判过程中的关键一步 。 当我们基于机器现成的舆情事件情感占比结果 , 研判舆情态势、针对性的采取相应策略时 , 也需要停下来想一想 , 舆情情感被测量的背后机理是什么?
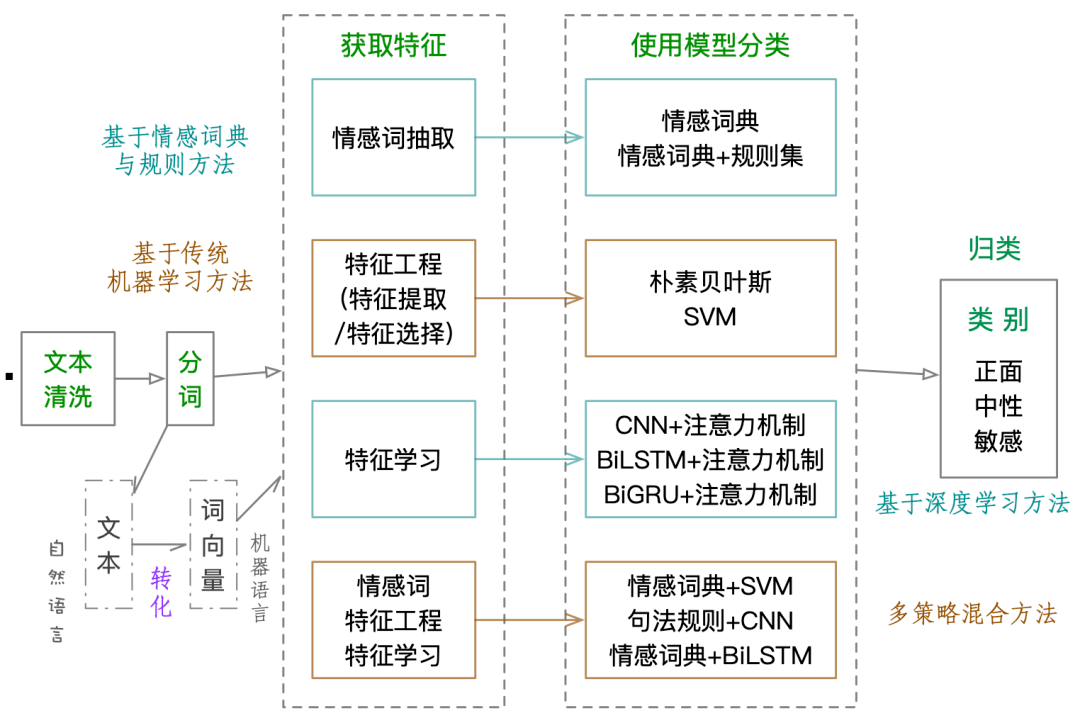
总体而言 , 文本情感分析通常要经过以下几个过程: 一是文本清洗 。 筛除与文本无关的噪声数据 。二是对文本进行分词处理 。 目的是将文本分为单独的词 , 然后转换为词向量 , 也就是将自然语言转化为机器语言 , 随即使用模型处理数据 。三是获取特征 。 从这一步开始有四种不同的方法 , 分别是基于情感词典与规则的方法、传统机器学习方法、深度学习方法、多策略混合方法 。四是使用模型分类 。 利用四种方法特有的模型对词、句、篇章蕴含的情感进行分析和预测其类别 。五是根据预测结果 , 把文本分到相应的类别中 。
文章图片
图:文本情感分析通用过程及使用方法
Step 01
文本清洗
在文本清洗阶段 , 首先对文本数据进行去停用词、去除换行符等清洗工作 , 统一英文数据、集中英文字母的大小写 , 并将数据序列化 。 这个过程由专门的成熟工具完成 。
Step 02
分词
由于计算机不能够直接理解人类的自然语言 , 对自然语言进行建模是让计算机能够运用自然语言进行计算的第一步 。 在自然语言处理任务中 , 首先需要考虑词如何在计算机中表示 。 研究自然语言的时候 , 都是需要把大量文本划分为最小知识单元 , 也就是把文章、段落、句子都划分为词 。
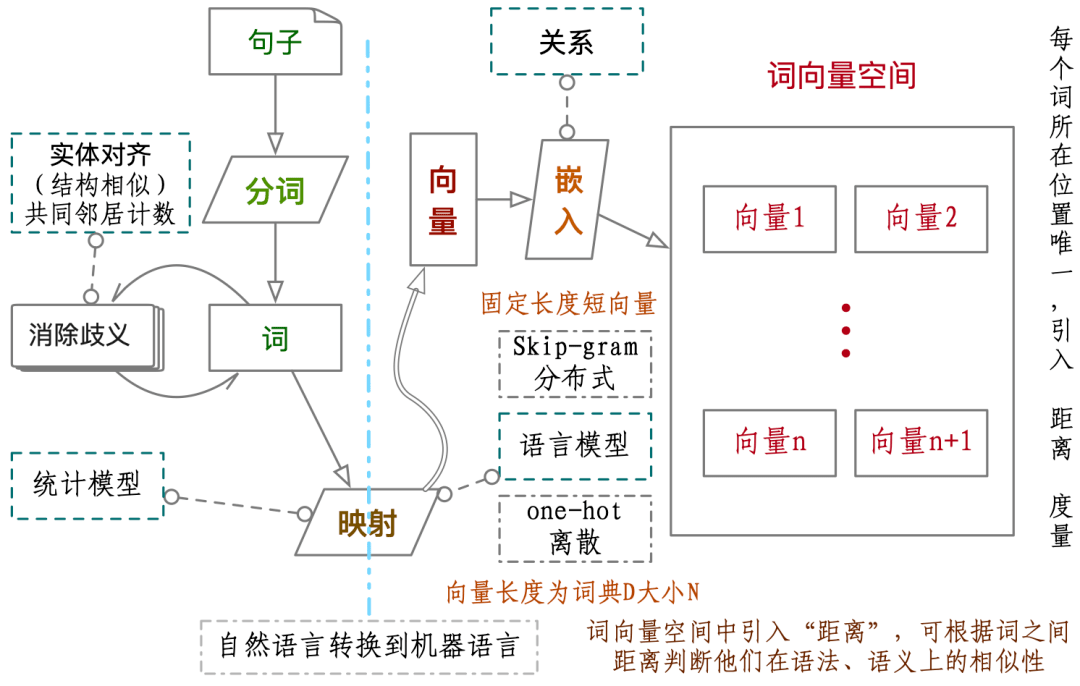
分词算法的原理是基于词典进行扫描 , 生成有向无环图;然后是根据词频进行最大化的切分与组合;最后使用基于汉字成词能力的HMM模型提取新词(该模型主要使用了Viterbi算法)完成对中文文本的词法分析 。 精确模式、全模式和搜索引擎模式是三种分词模式 。 精确模式就是将词最准确的划分出来 , 没有多余的词 , 这种分词方法最适用于对文本进行一些分析操作 。 分词原理及过程见下图 。
文章图片
图:词映射到词向量空间过程
Step 03
获取特征
特征是一个对于问题建模有意义的属性 , 可以表达更多的跟问题上下文有关的内容 。
基于情感词典与规则的方法获取特征 , 需要抽取出情感词 , 即从文本中自动识别出情感词来 。 如基于有限状态机(FiniteStateMachine , FSM)的匹配方法 。 情感元素抽取过程分三个步骤 。第一步 , 情感元素匹配 , 主要是将经过预处理的评论语料映射到特征词和否定副词的列表中 , 这些列表根据在元素评论中出现的顺序进行排序 。第二步 , 情感元素抽取 , 将列表数据作为FSM的输入 , 根据上下文和情感词寻找特征意见(Feature-Opinion , F-O)对 , 并确定每对F-O对的情感极性 。第三步 , 情感元素过滤 , 利用规则筛选出正确的F-O对 。
机器学习中提升效率和获得更好结果高度依赖于数据预处理 , 同时整个学习过程70%工作量也在此 , 数据预处理包括清洗、转换、规约三个部分 , 其中的规约是一个降维过程 , 在机器学习中通过特征工程实现 。 特征工程包括特征提取和特征选择两类 , 前者是保留所有特征但区别对待 , 如因子分析;后者是只留下最有效的特征 , 如矩阵的奇异值分解、Filter、Wrapper、Embedded等 。 是一个人工+机器共同实现的方法 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。