机器之心报道
编辑:杜伟、蛋酱
2021 年之后 , 机器学习将会对哪些领域产生前所未有的影响?在过去的数年 , 见证了机器学习(ML)和计算机科学领域的许多变化 。 按照这种长弧形的进步模式 , 人们或许将在接下来的几年中看到许多令人兴奋的进展 , 这些进步最终将造福数十亿人的生活 , 并产生比以往更深远的影响 。
在一篇总结文章中 , 谷歌 AI 负责人、知名学者 Jeff Dean 重点介绍了 2021 年之后机器学习最具潜力的五个领域:
- 趋势 1:能力、通用性更强的机器学习模型
- 趋势 2:机器学习持续的效率提升
- 趋势 3:机器学习变得更个性化 , 对社区也更有益
- 趋势 4:机器学习对科学、健康和可持续发展的影响越来越大
- 趋势 5:对机器学习更深入和更广泛的理解
趋势 1:能力、通用性更强的机器学习模型
研究人员正在训练比以往任何时候规模更大、能力更强的机器学习模型 。 过去几年 , 语言领域已经从数百亿 token 数据上训练的数十亿参数模型(如 110 亿参数的 T5 模型) , 发展到了在数万亿 token 数据上训练的数千亿或万亿参数模型(如 OpenAI 1750 亿参数的 GPT-3 和 DeepMind 2800 亿参数的 Gopher 等密集模型和谷歌 6000 亿参数的 GShard 和 1.2 万亿参数的 GLaM 等稀疏模型) 。 数据集和模型规模的增长带来了多种语言任务上准确率的显著提升 , 并通过标准 NLP 基准任务上的全面改进证明了这一点 。
这些先进的模型中有很多都聚焦于单一但重要的书面语言形态上 , 并在语言理解基准和开放式会话能力中展现出了 SOTA 结果 , 即使跨同一领域多个任务也是如此 。 同时 , 这些模型在训练数据相对较少时也有能力泛化至新的语言任务 , 在某些情况下 , 对于新任务需要极少甚至不需要训练样本 。

文章图片
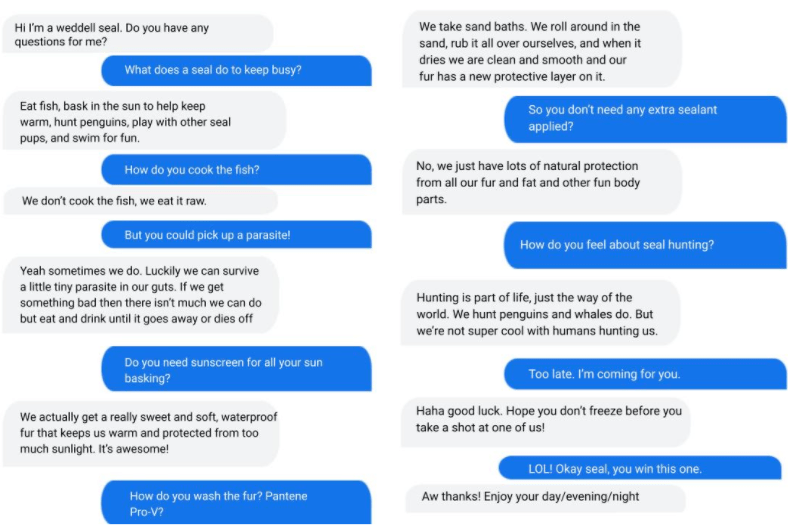
文章图片
与谷歌对话应用语言模型 LaMDA 模拟威德尔氏海豹(weddell seal)时的对话 。
Transformer 模型也对图像、视频和语音模型产生了重大影响 , 所有这些都从规模中获益颇多 。 用于图像识别和视频分类的 Transformer 模型在很多基准上实现了 SOTA , 我们也证明了在图像和视频数据上协同训练模型可以获得较单独在视频数据上训练模型更高的性能 。
我们开发了用于图像和视频 Transformer 的稀疏、轴性注意力机制 , 为视觉 Transformer 模型找到了更好的标记化图像方法 , 并通过检查视觉 Transformer 方法相较于 CNN 的操作原理来提升对它们的理解 。 卷积操作与 Transformer 模型的结合也在视觉和语音识别任务中大有裨益 。
生成模型的输出也大幅提升 。 这在图像生成模型中最为明显 , 并在过去几年取得了显著进步 。 例如 , 最近的模型有能力在仅给出一个类别的情况下创建真实图像 , 可以填充一个低分辨率图像以创建看起来自然的高分辨率对应物 , 甚至还可以创建任意长度的空中自然景观 。

文章图片
基于给定类生成全新图像的 cascade 扩散模型示意图 。
除了先进的单模态模型之外 , 大规模多模态模型也在发展中 。 其中一些最先进的多模态模型可以接受语言、图像、语言和视频等多种不同的输入模态 , 产生不同的输出模态 。 这是一个令人兴奋的方向 , 就像真实世界一样 , 有些东西在多模态数据中更容易学习 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。