我们已经看到 , 一方面 , 我们在自己的 ASR 系统中可以显著提高无序语音的语音识别质量 , 另一方面 , 使用 ML 帮助重建有语言障碍的人的声音 , 使他们能够用自己的声音进行交流 。 支持机器学习的智能手机 , 将帮助人们更好地研究新出现的皮肤状况或帮助视力有限的人慢跑 。 这些机会提供了一个光明的未来 , 不容忽视 。
文章图片
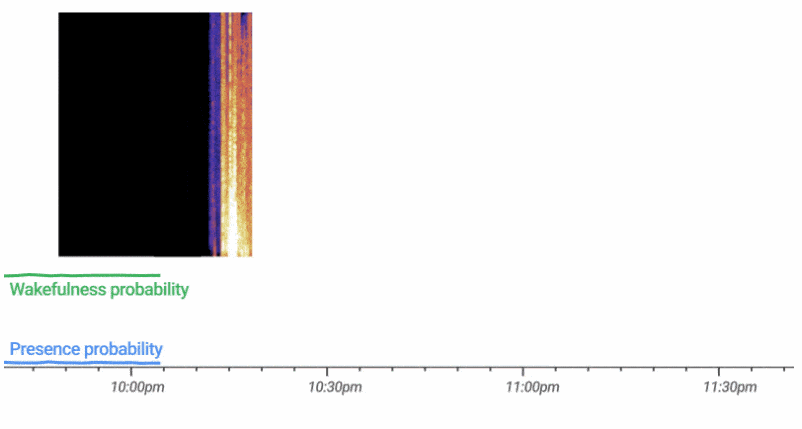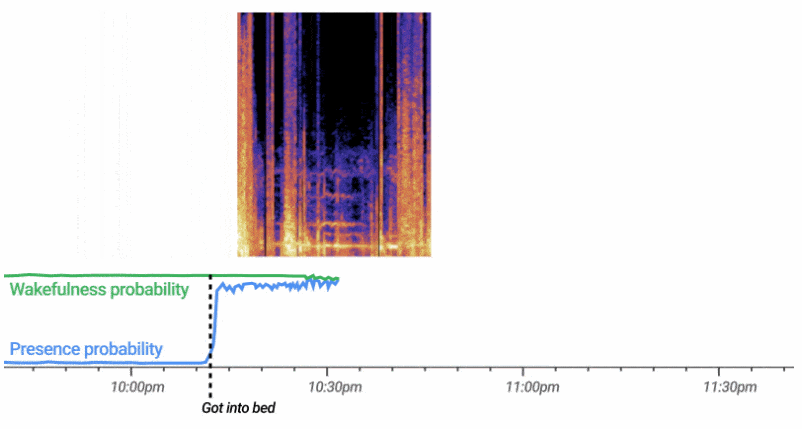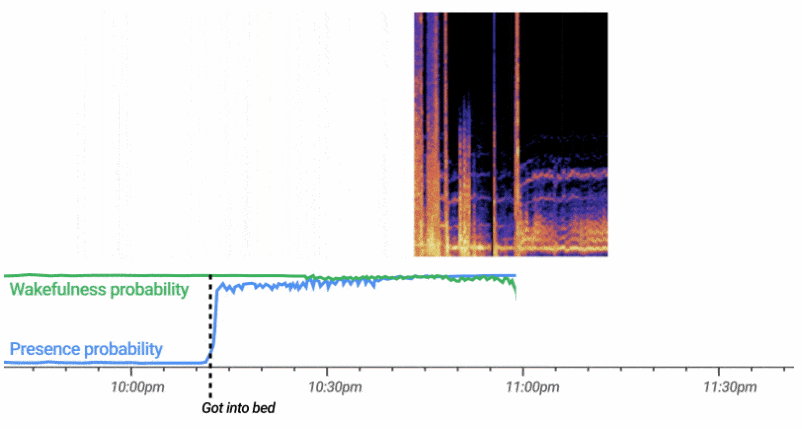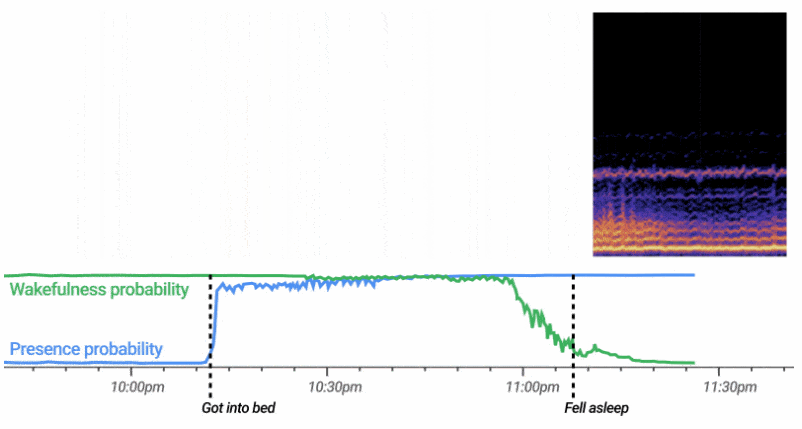
用于非接触式睡眠感应的自定义 ML 模型有效地处理连续的 3D 雷达张量流(总结一系列距离、频率和时间的活动) , 以自动计算用户存在和清醒(清醒或睡着)的可能性的概率 。
气候危机的机器学习应用
另一个最重要的领域是气候变化 , 这对人类来说是一个极其紧迫的威胁 。 我们需要共同努力 , 扭转有害排放的曲线 , 确保一个安全和繁荣的未来 。 关于不同选择对气候影响的信息 , 可以帮助我们以多种不同方式应对这一挑战 。

文章图片
借助环保路线 , Google 地图将显示最快的路线和最省油的路线 , 用户可以选择最适合的路线 。
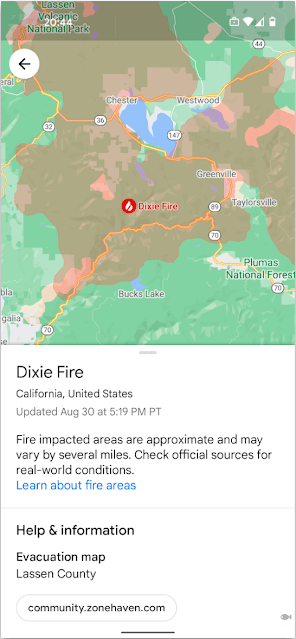
文章图片
Google 地图中的野火层可在紧急情况下为人们提供重要的最新信息 。
趋势 5:对机器学习更深入和更广泛的理解
随着 ML 在技术产品和社会中更广泛地使用 , 我们必须继续开发新技术以确保公平公正地应用它 , 造福于所有人 , 而不只是其中一部分 。
一个重点领域是基于在线产品中用户活动的推荐系统 。 由于这些推荐系统通常由多个不同的组件组成 , 因此了解它们的公平性通常需要深入了解各个组件以及各个组件组合在一起时的行为方式 。
与推荐系统一样 , 上下文在机器翻译中很重要 。 由于大多数机器翻译系统都是孤立地翻译单个句子 , 没有额外的上下文 , 它们通常会加强与性别、年龄或其他领域相关的偏见 。 为了解决其中一些问题 , 谷歌在减少翻译系统中的性别偏见方面进行了长期的研究 。
部署机器学习模型的另一个常见问题是分布偏移:如果用于训练模型的数据的统计分布与作为输入的模型的数据的统计分布不同 , 则模型的行为有时可能是不可预测的 。
数据收集和数据集管理也是一个重要的领域 , 因为用于训练机器学习模型的数据可能是下游应用程序中偏见和公平问题的潜在来源 。 分析机器学习中的此类数据级联有助于识别机器学习项目生命周期中可能对结果产生重大影响的许多地方 。 这项关于数据级联的研究在针对机器学习开发人员和设计人员的修订版 PAIR Guidebook 中为数据收集和评估提供了证据支持的指南 。
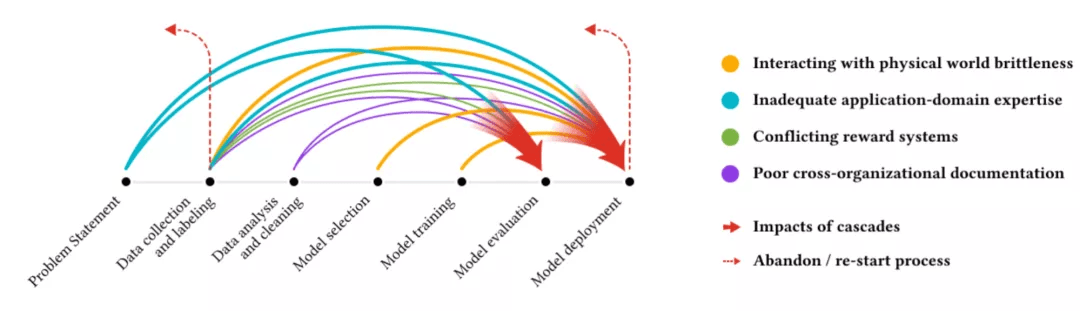
文章图片
不同颜色的箭头表示各种类型的数据级联 , 每个级联通常起源于上游 , 在机器学习开发过程中复合 , 并在下游表现出来 。
创建更具包容性和更少偏见的公共数据集是帮助改善每个人的机器学习领域的重要方法 。
2016 年 , 谷歌发布了 Open Images 数据集 , 该数据集包含约 900 万张图像 , 标注了涵盖数千个对象类别的图像标签和 600 个类别的边界框注释 。 去年 , 谷歌在 Open Images Extended 集合中引入了更具包容性的人物注释 (MIAP) 数据集 。 该集合包含更完整的针对人类层次结构的边界框注释 , 并且每个注释都标有与公平相关的属性 , 包括感知的性别表示和感知的年龄范围 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。