但是 , 大家逐渐认识到数据本身就是资产 , 除了能够指导现有业务的发展之外 , 数据还可以给企业提供更多的创新 , 甚至商业模式的变革 。 所以你会发现 , 虽然数据目前只是决策中的辅助手段 , 但数字化决策这件事是势在必行的 。 必须说一句:前途是光明的 , 但道路绝对是曲折的 。
从“可选项”到“必选项”
古往今来 , 某个事物的出现和发展一定要兼具天时、地利、人和 。 互联网的大规模发展是因为个人电脑的普及;移动互联网的大规模发展是因为智能手机的普及;云计算的大规模发展是因为芯片、存储器、机器、网络等硬件的普及;大数据的大规模发展是因为计算、存储等资源的普及;人工智能的大规模发展是伴随着算力、数据、算法的普及 。
那么企业数字化转型呢?当然也不会例外 , 它也有自身的“天时、地利、人和” 。
企业数字化的“天时”说白了就是大数据和人工智能这两大技术的发展 , 看懂了它们的发展历程 , 也就明白了“天时” 。
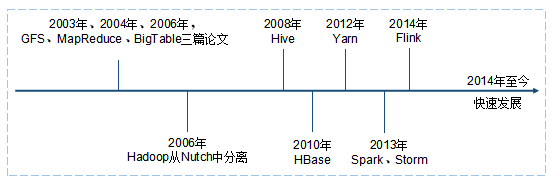
请看图2的时间轴 , 2003年、2004年、2006年 , 谷歌分别输出了GFS、MapReduce、BigTable三篇论文 , 被称为大数据的三驾马车 , 也不负众望地成为大数据的奠基之作 。 Hadoop就是在三驾马车的启发下诞生的 。 Hadoop具有以下三个特点 。
文章图片
图2 大数据发展史
- Hadoop参照GFS打造出HDFS , 它是一个运行在普通机器上的、可供大规模存储和访问的分布式文件系统 , 是大数据存储的基石 。 使得大数据这件事情变得可行 , 在硬件成本上可控 , 在软件技术上可实现 。
- Hadoop参照MapReduce打造出Hadoop MapReduce , 它是大数据分布式计算的一种方式 , 将大数据的计算任务先分解到多台普通机器上 , 然后进行合并得到计算结果 。 它是大数据计算的基石 , 使得大数据计算变得可行 , 在硬件成本上可控 , 在软件技术上可实现 。
- Hadoop参照BigTable打造出HBase , 它是对底层的大规模存储和计算去进行使用的一个大表 , 毕竟表格是更符合人的需求的一种存在 , 可以认为它是NoSQL数据库的基石 。
这厢大数据日新月异 , 那边人工智能也不甘示弱 。
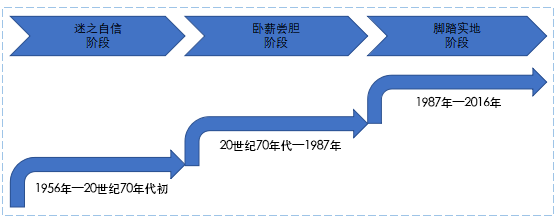
众所周知 , 人工智能缘于1956年达特茅斯大会 , 发展至今也有五十多年了 , 可以说是经历了三起三落(见图3) 。
文章图片
图3 人工智能发展史
第一阶段 , 从20世纪50年代到20世纪60年代是第一个高潮期 , 主要是以逻辑学为主导的定理证明 。 然而 , 由于计算能力的不足 , 以及当时人工智能本身并不具备学习能力 , 20世纪70年代迎来了人工智能的第一个低谷期 , 各种压力和经费问题也接踵而至 , 人工智能的前景也顿时蒙上了一层阴影 。
第二阶段 , 好在总有那么一小部分不按常理出牌的人继续坚持研究 , 大概蛰伏了10年 , 终于在1980年 , 卡内基·梅隆大学的第一套专家系统XCON诞生了 。 XCON系统每年到底能为企业节省多少成本一直是个谜(最高的有四千万美元 , 最低的也有几百万美元) , XCON专家系统经历了近10年的黄金期 , 也是人工智能的第二个高潮期 。 然而 , 随着第五代计算机的幻灭 , 人工智能走进了第二个寒冬 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。