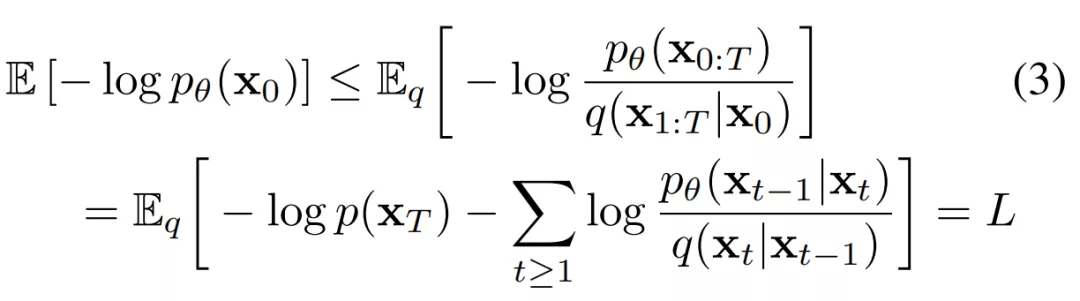
文章图片
根据 Jonathan Ho 等人在论文《Denoising Diffusion Probabilistic Models》中的扩展 , 损失(loss)可以进一步分解为如下公式 (4) 所示:

文章图片
在 Jonathan Ho 等人的这篇论文中 , 他们认为参数化模型的最佳方法是对添加到当前中间图像 x_t 的累积噪声?_0 预测 。 如下公式 (5) 所示 , 研究者对预测的平均值 μ_θ(x_t, t)进行参数化表示 。
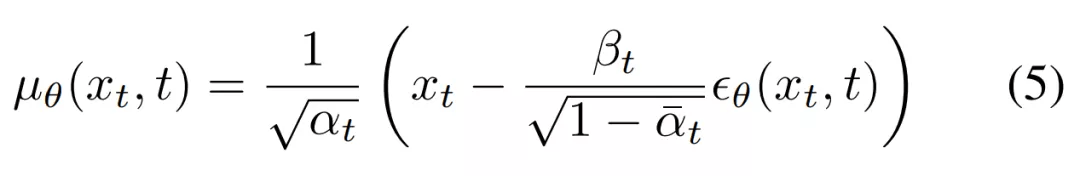
文章图片
为了训练 DDPM , 研究者需要一个样本 x_t 以及相应的用于将 x_0 转换为 x_t 的噪声 。 最后 , 他们可以对公式 (1) 进行重写 , 作为一个单步执行 , 具体如下公式 (7) 所示
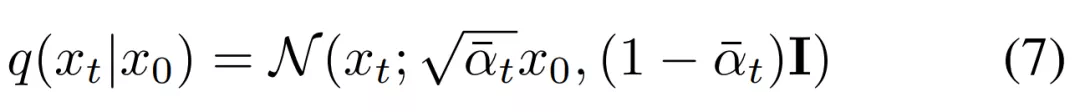
文章图片
方法
已知区域的条件作用
图像修复的目标是 , 通过将掩码区域用作条件 , 预测一个图像的缺失像素 。 如前所述 , 研究者在本文中使用了一个训练过的非条件去噪扩散概率模型 。
由于前向过程通过添加的高斯噪声的马尔可夫链(Markov Chain)来定义 , 研究者可通过定义 (7) 在任意点上采样中间图像 x_t 。 这使得他们在任意时间步 t 采样已知区域 m⊙x_t 。 因此 , 通过公式 (2) 处理未知区域和公式 (7) 处理已知区域 , 研究者得到了如下所示的反转步(reverse step)的表达式 。
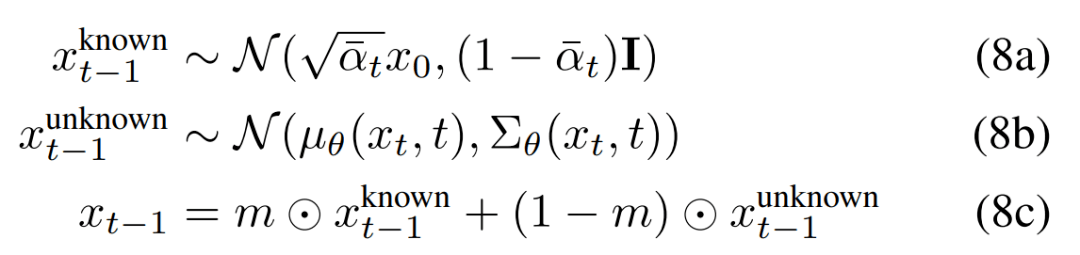
文章图片
因此 , 研究者使用给定图像 m⊙x_0 中的已知像素对
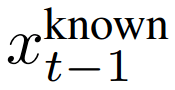
文章图片
进行采样 , 同时在给定上次迭代 x_t 时 ,

文章图片
从模型中采样 。
如下为使用 RePaint 方法进行图像修复的算法 1:

文章图片
RePaint 方法的概览如下图 2 所示

文章图片
重采样
当直接应用上述方法时 , 研究者观察到:只有内容类型(content type)与已知区域匹配 。 比如 , 在下图 3 中 , 当 n 为 1 时 , 图像修复的区域是与原始输入图像狗狗的皮毛相匹配的皮毛纹理 。 尽管图像修复的区域与邻近区域的纹理相匹配 , 但在语义上显然是不正确的 。 因此 , 虽然 DDPM 利用了已知区域的上下文 , 但它并没有很好地协调图像的其他部分 。

文章图片
由于 DDPM 被训练生成一个位于数据分布中的图像 , 它自然地想要生成一致性的结构 。 在研究者的重采样方法中 , 他们利用 DDPM 的这种特性来协调模型的输入 。
实验结果
实验采用 V100 GPU , 在 CelebA-HQ 和 Imagenet 数据集上进行了实验 。 表 1 中报告了定量结果 , 图 4 和图 5 中报告了视觉结果 。
比较方法:该研究将 RePaint 与几种 SOTA 性能的基于自回归或基于 GAN 的方法进行比较 。 自回归方法包括 DSI 和 ICT , GAN 方法包括 DeepFillv2、AOT 和 LaMa 。
宽和窄蒙版(Wide and Narrow masks):为了在标准图像修复场景中验证 RePaint , 该研究使用 LaMa 设置宽和窄蒙版 。 在 CelebA-HQ 和 ImageNet 中 , 对于 Wide 和 Narrow 设置 , RePaint 以 95% 的显着性裕度(margin)优于所有其他方法 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。