根据任务输入(X)和输出(Y)文本中 , 信息量的关系 , 研究者认为可以把语言生成任务分为三大类:压缩、转换和创建 , 分别对应输入大于、等于和小于输出 。 每一类任务的目标都有区别 , 也对输出文本提出了各自的要求 。 我们可以通过对新任务对分类 , 对「评价什么」有所启发 。
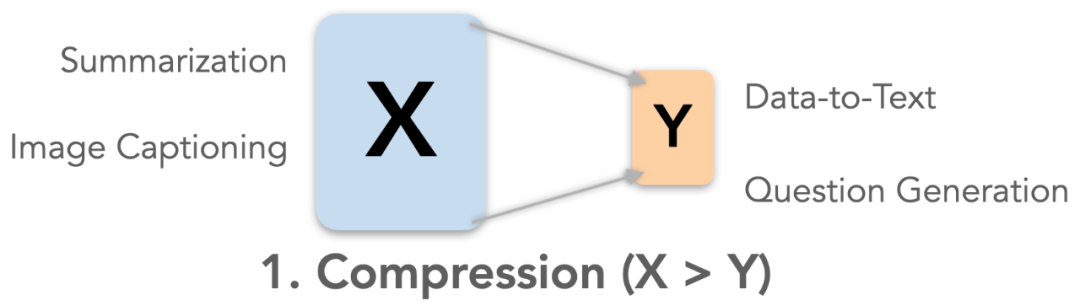
压缩类任务(Compression)
文章图片
- 目标:把输入信息中重要的部分 , 呈现在输出中
- 举例:摘要生成(Summarization)、图像描述(Image Captioning)、结构文本生成(Data-to-Text)和问题生成(Question Generation)
- 评价重点:1)输出信息要完全来自输入;2)输出信息应该是输入中的重要信息
文章图片
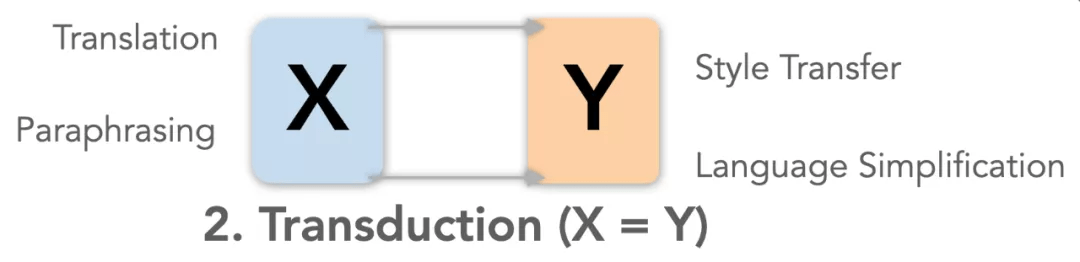
- 目标:把输入信息中的某一方面转换 , 其他保持不变
- 举例:机器翻译(Translation)、文本复述(Paraphrasing)、文本风格迁移(Style Transfer)和文本简化(Language Simplification)
- 评价重点:输出要尽量完整地保留输入的信息
文章图片
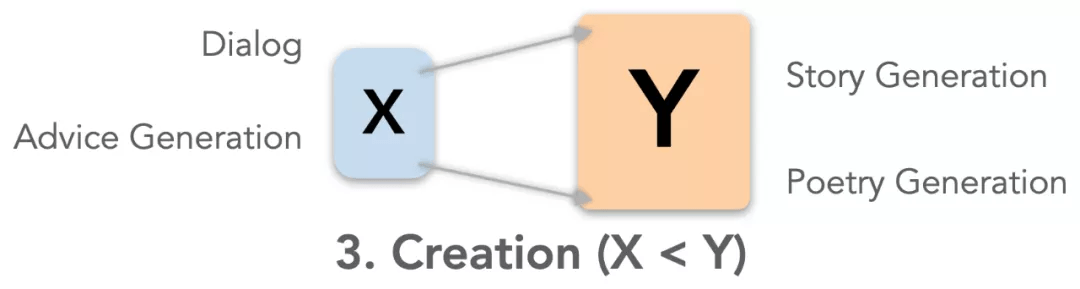
- 目标:基于输入和外部信息 , 输出新的信息
- 举例:机器对话(Dialog)、建议生成(Advice Generation)、故事生成(Story Generation)和诗歌生成(Poetry Generation)
- 评价重点:1)输出要充分回应输入;2)输出要正确地使用外部信息
如何评价:信息对齐
为了测量如上所述的重合度 , 研究者引入了「信息对齐」这个运算符 , 这样就统一了所有生成任务的评价方式 。
信息对齐是说 , 对于文字A和任何数据B , 可以对于A的每个词都算出一个置信度 , 这个词的信息有没有在B中反映出来 。 具体的数学形式为如下所示的向量:
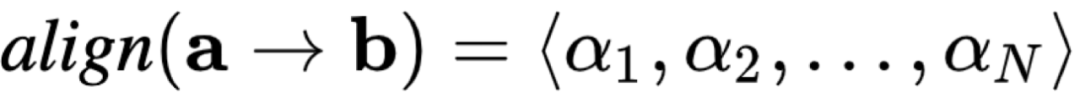
文章图片
在实际中 , 这个数据B不一定要是文字 , 也可以是任何模态的数据 , 只要有一个模型(Alignment Model)能算出这个对齐的置信度 。 A、B、模型和对齐向量的关系如下图所示:
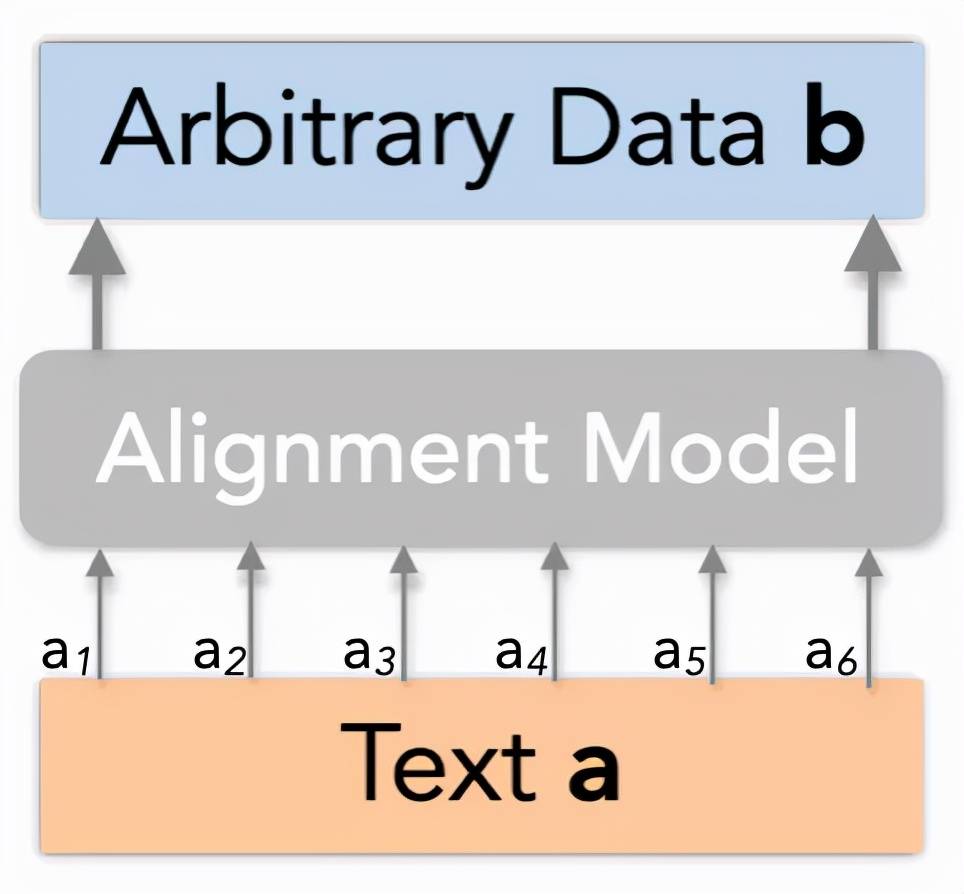
文章图片
下面 , 研究者展示了如何统一地用信息对齐这个算符 , 来定义各种语言生成任务的评价指标 。
用信息对齐统一设计评价指标
压缩类任务
对于压缩类任务 , 研究者以摘要生成作为一个例子:
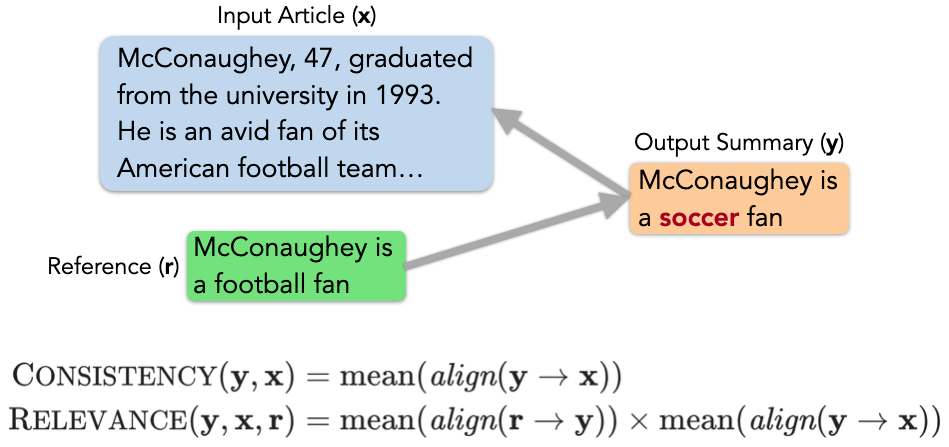
文章图片
转换类任务
对于转换类任务 , 研究者以文本风格迁移为例:
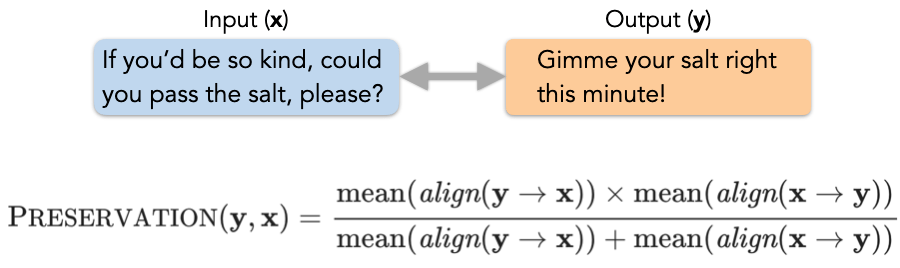
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。