文章图片
创建类任务
对于创建类任务 , 研究者以知识对话为例:

文章图片
现在已经用信息对齐运算符定义了这么多评估指标 , 下一步来看这个运算符是怎样实现的 。
信息对齐的三种实现方法
研究者把信息对齐当作一个预测问题建模 , 提出了三种基于预训练模型(Pretrained Language Models)的实现方法 , 普遍采用自监督学习 。 模型准确度可以通过与人工标注比较来评价 。
词向量召回(Embedding Matching)
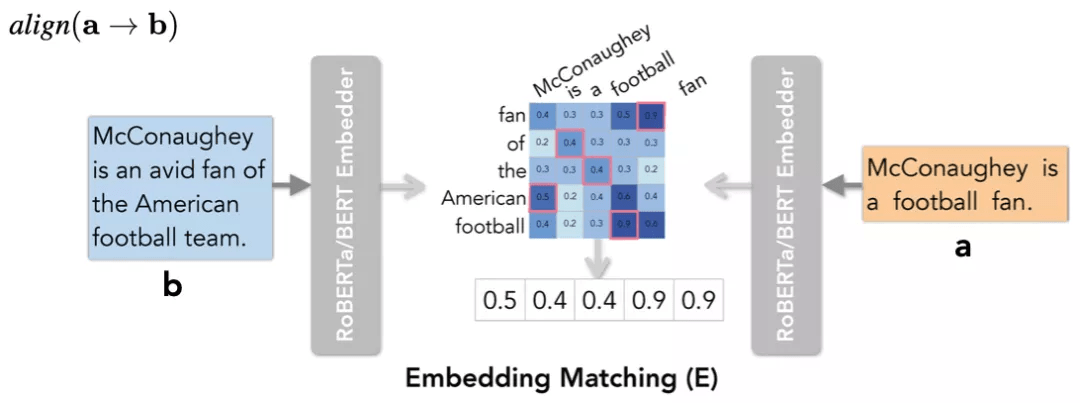
文章图片
判别模型(Discriminative Model)
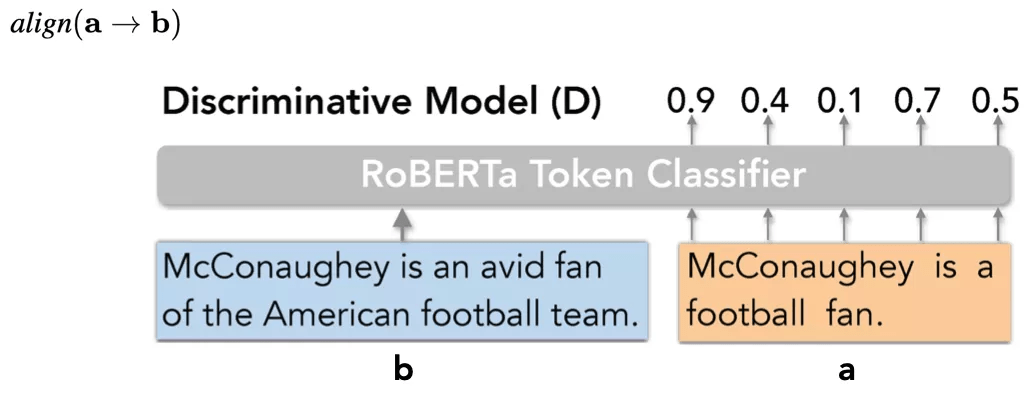
文章图片
回归模型(Aggregated Regression)
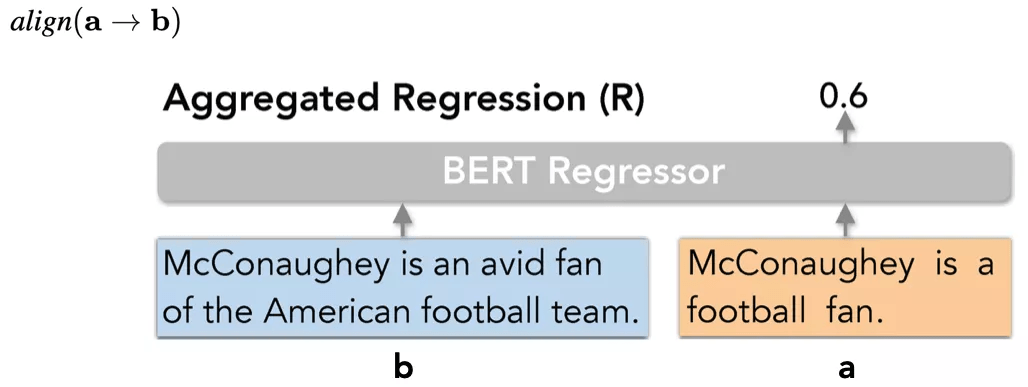
文章图片
实验结果
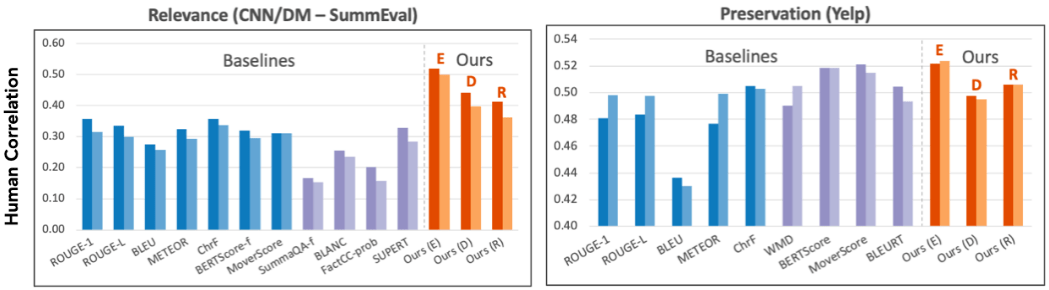
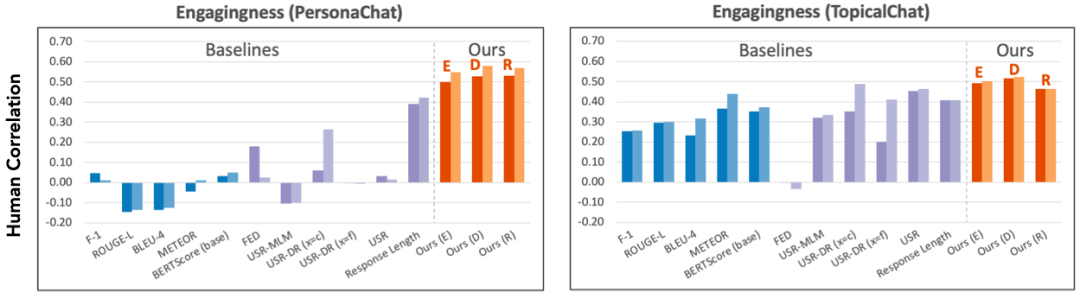
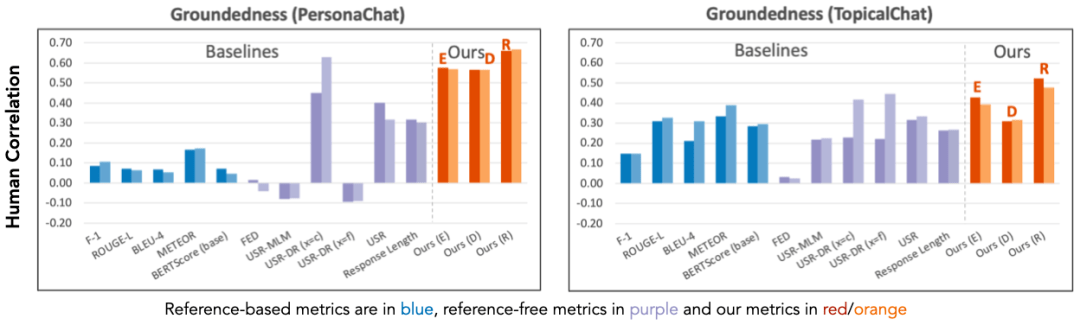
实验结果表明 , 研究者的统一设计的评价指标 , 与人工评分的相似度 , 超过之前的针对任务特别设计的指标 , 最高超过现有指标57.30% 。 另外 , 研究者发现 , 对齐模型预测准确度越好 , 他们的指标就越接近人的评价 。
超过现有指标最多57.30%
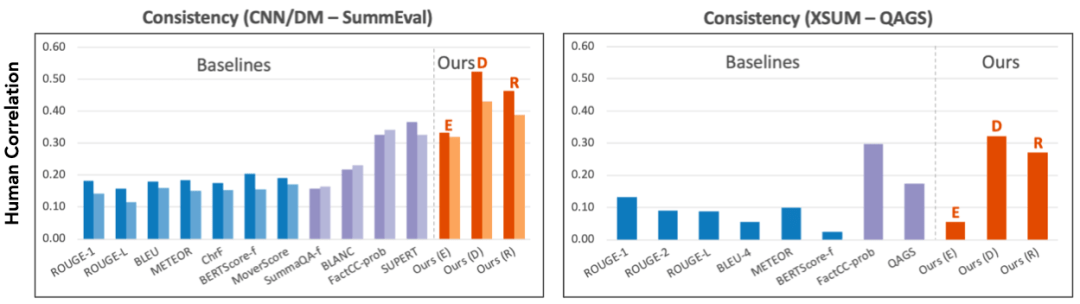
文章图片
文章图片
文章图片
文章图片
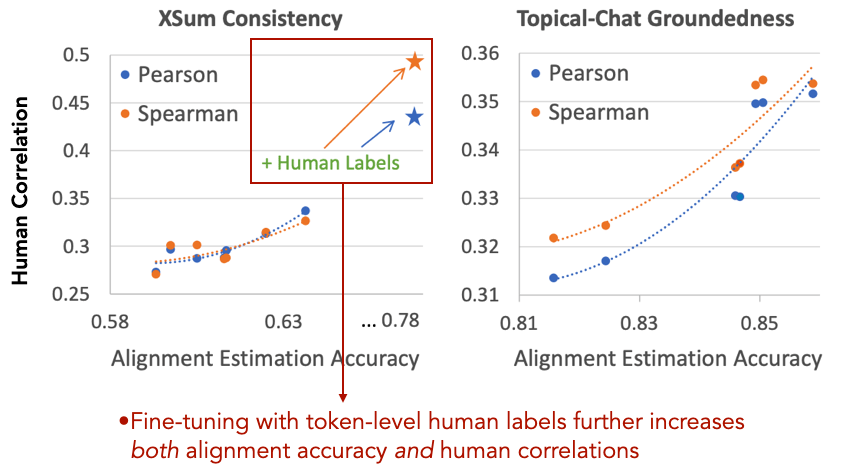
对齐模型准确度与人工评分相似度有直接关系
研究者的对齐模型普遍使用自监督学习 , 但使用人工标注训练可以有效提升准确度和以此实现的评价指标 。 与人工评分的相似度如下图所示:
文章图片
这说明了:只要能够改善对齐预测模型 , 就能改善一大批评价指标 。 我们可以把对齐预测作为一个单独的任务 , 这个任务的进步直接提升评价语言生成的准确度 。
这项工作开启了可组合(Composable)的文本评价流程 。 像软件工程一样 , 研究者表示可以把这个系统分为若干模块 , 这些模块可以独立地改进、规模化、和诊断 , 未来期待有更多的探索 。
封面来源:https://soa.cmu.edu/
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。