在这项工作中 , 研究者通过从一个语言模型中采样动作来解决无限动作空间问题 。 语言模型能够生成策略调用以及通常需要作为参数的原始数学术语 。 对于自博弈的缺乏 , 他们观察到 , 自博弈在两人游戏中的关键作用是提供一个无监督的课程(curriculum) 。 因此 , 他们建议用一套不同难度的辅助问题命题(不需要证明)来代替这种无监督的课程 。 他们的实验结果表明 , 当这些辅助问题的难度变化足够大时 , 他们的训练程序就能够解决一系列越来越难的问题 , 最终推广到他们所关心的问题集 。
虽然这些结果非常令人兴奋 , 因为它们证明了深度学习模型在与形式系统交互时能够进行重要的数学推理 , 但在竞赛中 , 该证明器离最佳学生表现还差得很远 。 研究者表示 , 他们希望自己的工作将推动这一领域的研究 , 特别是针对 IMO 的研究 , 并希望他们提出的 statement curriculum learning 方法能够加快自动推理的研究进展 。
小结
两家机构最新的研究成果已经介绍完毕 , 网上已经零零散散地出现了关于效果的评价:
文章图片
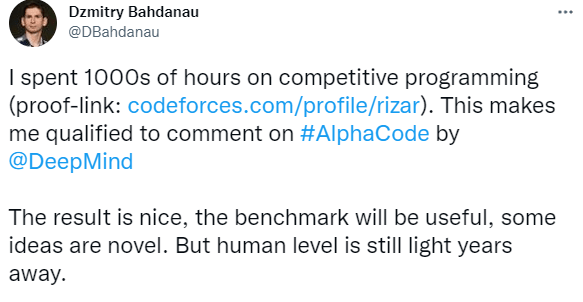
如有 AI 研究科学家发系列长推表示 , AlphaCode 达到人类水平还需要几年时间 , 它在 codeforce 上的排名是有限制的 , 如许多参与者是高中生或大学生;还有就是 AlphaCode 生成的绝大多数程序都是错误的 , 正是使用示例测试进行过滤才使得 AlphaCode 实际解决了某些问题 。
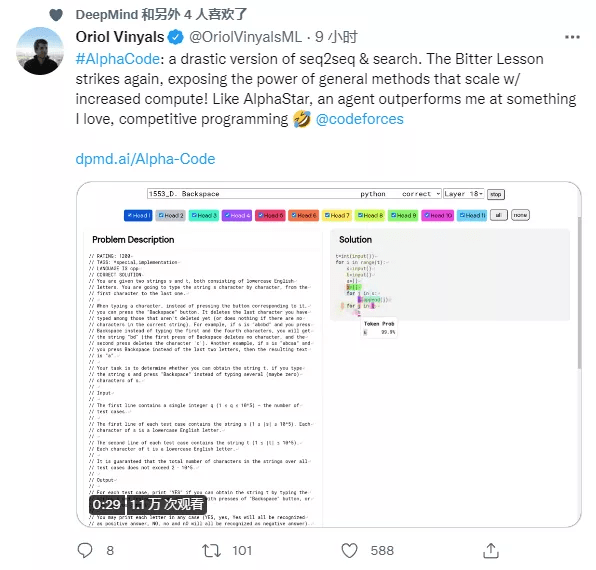
也有研究人员表示 , 这像是 AlphaStar 大力出奇迹的结果 。
文章图片
国内的 AI 从业者们可以趁假期研究下这两项研究 , 发表自己的看法 。
参考链接:https://openai.com/blog/formal-math/?continueFlag=6cc759bbfb87d518f6d6948bcf276707
https://deepmind.com/blog/article/Competitive-programming-with-AlphaCode?continueFlag=b34ed7683541bab09a68d7ab1d608057
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。