文章图片
文章图片
截面分析
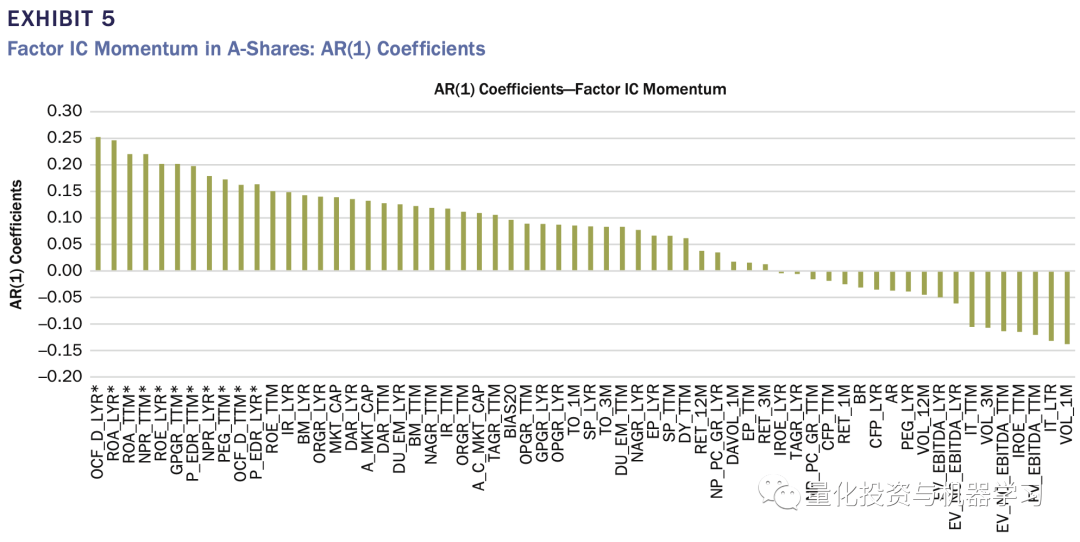
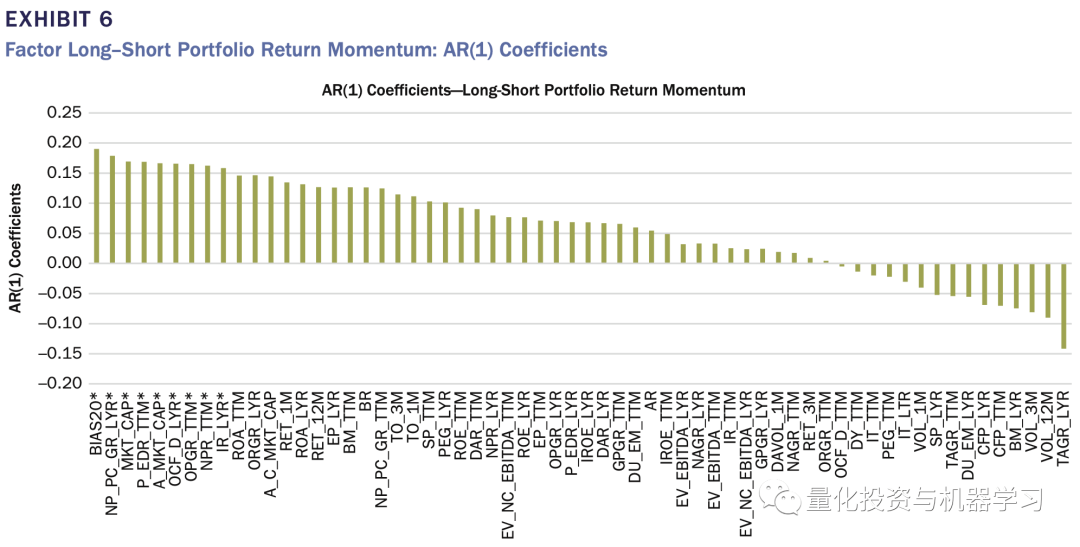
虽然每个因子在时间序列预测能力方面表现出很大的差异 , 但对于整个研究期间的每个因子大类(风格) , 在大多数月份 , 每组内都存在有效因子(表7) 。
面板数据分析
在一段强劲的表现之后 , 因子的有效性会衰减或完全消失(Vopati et al.2020) 。 这是由于因子拥挤造成的 。 因子拥挤度可以通过一个月的因子横截面重要性与历史重要性滚动平均值的相对值来评估 。 由于因子库包含具有相似特征的因子 , 因此在测量因子拥挤度时可以将它们分组到不同的聚类中 。
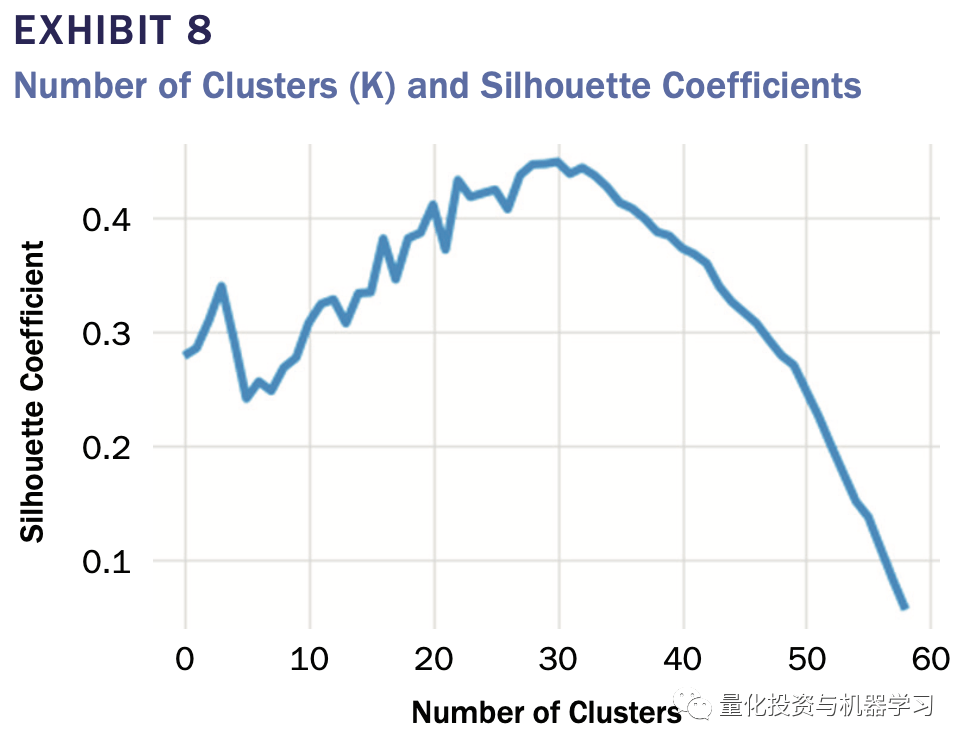
作者使用K-means , 基于62个因子的IC序列 , 对它们进行聚类 。 K的数量取决于轮廓系数(silhouette) 。 silhouette系数是聚类效果好坏的一种评价方式 。 值越大 , 说明聚类效果越好 。 如图8 , 说明K等于30时聚类效果最好 。
文章图片
对于聚类在t时刻的重要性 , 用以下公式计算 。 也就是该时刻 , 所有聚类内因子IC的均值 。
而因子k在t时刻的相对重要性(相对于过去12个月)等于:
其中 ,
我们发现因子的相对价值能够捕捉到因子的过度拥挤 。 研究期间 , 因子有76.5%可能的损失预测能力(单向因子的IC < 0.05或双向因子|IC | < 0.05 ) 。
通过以上的测试 , 对因子模型的构建得出了以下几个启发:
- 因子IC表现出的不稳定性 , 说明静态的因子模型可能效果不会很好;
- 一阶自回归测试结果说明因子筛选时可以考虑因子动量
- 许多AR(1)为正 , 但不显著 , 这种情况下 , 可以在每个因子分类中加入一个动态因子筛选器 。
- 尽管单因子不稳定 , 但每组中总有有效的因子 , 说明在模型要考虑每组中因子的分散性 。
- 因子很有可能由于因子拥挤而衰减 , 说明因子拥挤可以用在因子权重配比中 。

文章图片
因子模型和组合优化
基于以上发现 , 我们构建了一个动态多因子模型(Model 1) , 除此之外还构建了三个用于对比的模型(Model2-Model4) 。 下面分别介绍一下这4个模型:
Model1 动态多因子模型
模型的整体流程如图10所示 , 具体说明如下:
1、因子预测能力过滤 , 考虑到因子动量效应 , t-1时刻 , 在每个因子组内选择一个预测效果最好的因子(基于t-1时刻的因子Rank IC) 。
2、预测能力持续性过滤(Predictive power persistency filtering) , 根据36个月滚动数据计算一阶马尔可夫链转移概率 。 对于一个因子 , 预测能力持续性过滤的条件是:正向因子 大于 1/3;负向因子 大于1/3;双向因子 或 大于1/3 。 每一组的因子选择逻辑如下:
- 如果这一步没选出因子 , 则返回上一步 , 选择这组IC最高的4个因子直接进入下一步 。
- 如果这一步选出因子 , 再在这组剩下的因子中 , 选择一个IC最高的 , 此时这组有两个因子进入下一步 。
基于因子月度Rank IC值 , 把因子分为三个状态:1. 较强正向预测能力(IC>=0.05)2. 较差预测能力(|IC|<=0.05)3. 较强负向预测能力(IC<=-0.05) 。 也就是说 , 给定这三种状态 , 任何一个因子的IC时间序列都可以转变为类似[1,1,2,2,1,1,2,3,3...]的状态序列 。 可以使用较长时间的历史数据得到状态序列 , 并由此计算因子预测能力的转移概率 。 用p_i,j表示从状态i转移到j的概率 , p_1,1表示从状态1(较强正向预测能力)变到还是状态1的概率 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。