通过训练新的 tokenizer 或使用可用的预训练语言模型中的词汇来扩充语言知识;
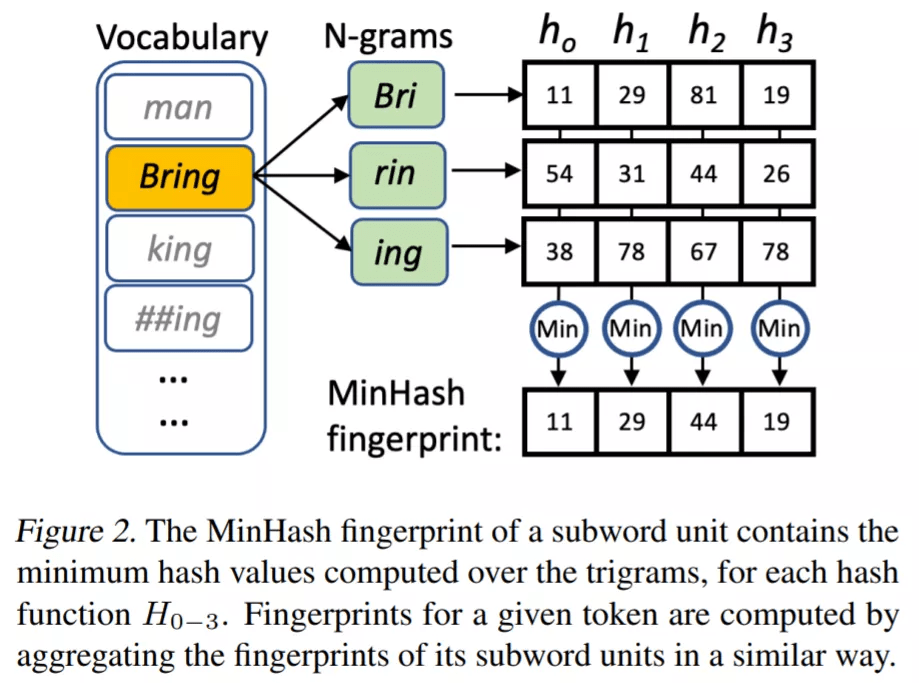
每个子词单元的表征可以被缓存以降低推理成本 。
文章图片
投影层通过复用词汇表 V 的单个子词单元的 fingerprint 来计算每个输入 token t 的 MinHash fingerprint F^t 。 fingerprint F ∈ N^n 是由 n 个正整数组成的数组(F_0 到 F_(n-1) ), 使用 n 个不同的哈希函数 h_0(x) 到 h_n-1(x) 将字符串映射成正整数来进行计算 。
MLP-Mixer
MLP-Mixer 是一个简单的架构 , 仅由 mixer 块组成 , 每个块有两个多层感知器 (MLP) , 以换位操作(transposition operation)进行交错 。 第一个 MLP 输出的换位给到第二个 MLP , 然后对序列维度进行操作 , 从而有效地混合了 token 之间的信息 。 此外 , MLP-Mixer 遵循了最初的架构设计 , 使用了跳跃连接、层标准化和 GELU 非线性 。
在该方法中 , 投影层产生的矩阵 C∈R^(2w+1)m×s 将通过一个瓶颈层 , 即一个线性层 , 该线性层输出矩阵 B∈R^b×s , 其中 B 为瓶颈大小 , s 为最大序列长度 。 这个矩阵 B 是 MLP-Mixer 模型的输入 , 它反过来产生与 B 相同维度的输出表征 O∈R^(b×s) 。 在输出 O 之上应用分类头以生成实际预测 。 在语义解析的情况下 , 这个分类头是应用于每个 token 的线性层 , 而对于分类任务 , 该方法使用注意力池化 。
实验
在评估模型的最终性能之前 , 该研究彻底分析了所提架构 。 本节的实验是在英文 MTOP 的验证集上进行的 , 报告的指标是最佳 epoch 的精确匹配准确率(exact match accuracy) 。 该研究使用具有 2 层的 pNLP-Mixer 作为基础模型 , 瓶颈和隐藏大小为 256 , 输入序列长度为 64 , token 特征大小固定为 1024 , 窗口大小为 1 , 并训练 80 个 epoch , 学习率为 5e ^-4 、batch 大小为 256 。
投影比较
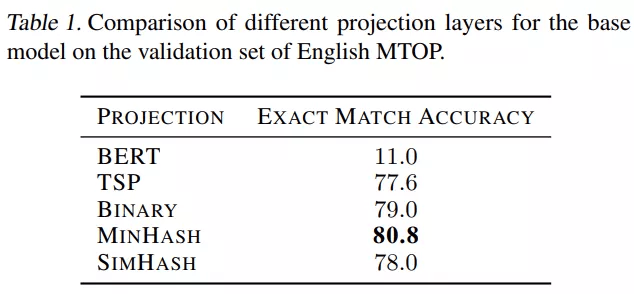
【CV之后,纯MLP架构又来搞NLP了,性能媲美预训练大模型】首先 , 该研究比较了不同特征提取策略对性能的影响 , 包括:
- BERT 嵌入
- 二进制
- TSP
- MinHash
- SimHash
文章图片
模型比较
已有结果表明 , MinHash 投影提供了强大的语言表征 。 下一个问题是 MLP-Mixer 是否是处理这种表征的最佳架构 。 为了研究这一点 , 该研究首先考虑一个基线 , 其中 MLP-Mixer 被移除 , 瓶颈层的输出直接传递给分类头 。 在这里 , 研究者考虑两个不同的投影层 , 一个窗口大小为 1 , 另一个窗口大小为 4 。 该研究将 MLP-Mixer 与其他两种架构进行比较 , 方法是保持相同的投影、瓶颈层和分类头 , 并用 LSTM 和具有相似数量参数的 transformer 编码器专门替换 MLP-Mixer 。
表 2 表明简单地移除 MLP-Mixer 并仅依赖投影会导致性能显着下降 。 特别是 , 使用窗口大小为 1 的投影将参数数量减少到 820K , 但代价是性能下降超过 15 个点 。 另一方面 , 大型投影层导致参数数量翻倍 , 而精确匹配准确率仅达到 76.5% , 即比 MLP-Mixer 低 4.3% 。 从替代模型来看 , LSTM 的性能明显低于 MLP-Mixer , 但使用 180 万个参数 , 即多出 50% , 精确匹配准确率较低(73.9%) 。 Transformer 模型的参数数量与 MLPMixer (1.2M) 大致相同 , 得分低 1.4% 。 最后一个结果是显着的:对于相同数量的参数 , MLPMixer 优于 transformer , 同时具有线性复杂性依赖于输入长度 , 而不是二次 。 总体而言 , 该评估表明 MLP-Mixer 是一种用于处理投影输出的重量效率高的架构 , 即它比具有较少参数的替代方案具有更高的性能 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。