文章图片
架构研究
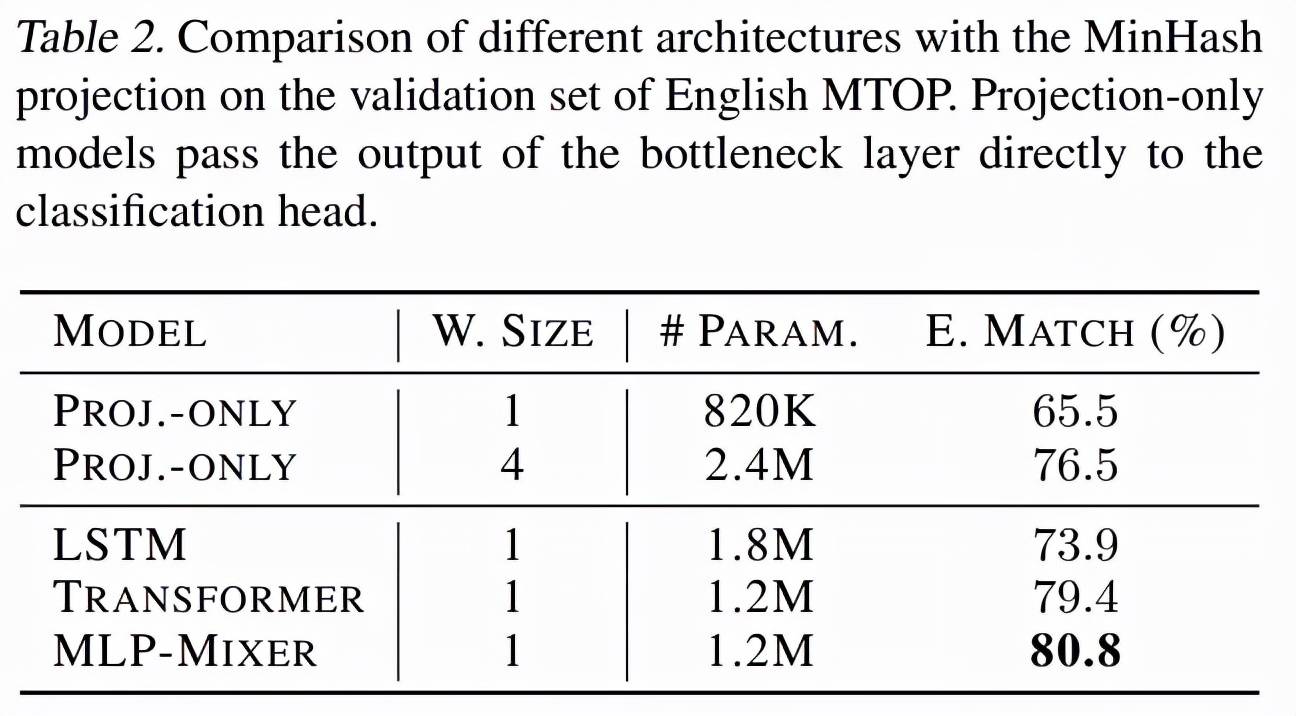
该研究对 pNLP-Mixer 模型进行了广泛的架构探索 , 以确定不同超参数对下游性能的影响 , 研究范围包括投影超参数和 MLP-Mixer 超参数 。 对于投影 , 研究包括 token 特征大小、哈希数和窗口大小;而 MLP-Mixer 研究了瓶颈大小(bottleneck size)和层数 。 使用的学习率为 5e^?4 , batch 大小为 256 , 隐藏大小为 256 。 表 3 报告了每个配置的精确匹配准确率和参数数量 。
文章图片
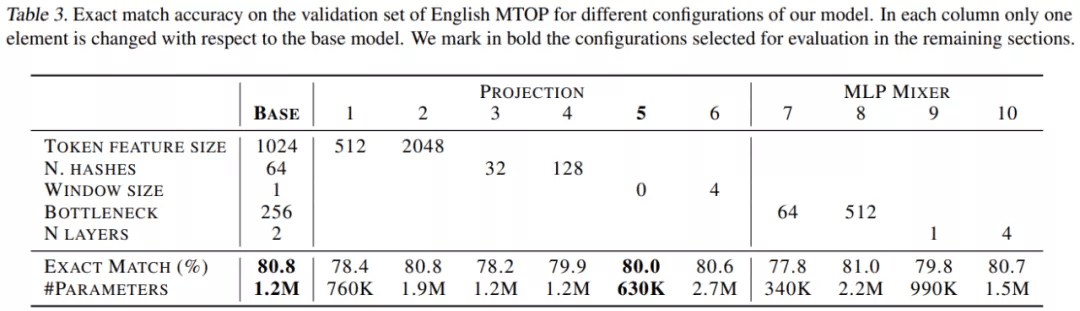
考虑到 MLP mixer , 将瓶颈大小(bottleneck sizes)增加到 512 会略微提高性能 , 而当使用 4 层时 , 它会达到与 2 层相似的值 。 然而 , 这些超参数并不独立于投影层:较大的投影可能需要较大的 MLP-Mixer 来处理所有的信息 。 因此 , 表 4 研究了投影大小和 MLP-Mixer 之间的关系 。
实验报告了两个较大模型和两个较小模型的结果 , 由结果可得较大的模型具有更大的特征和瓶颈大小 , 实验还表明 4 层达到了所有研究模型的最佳性能 。 另一方面 , 其中一个小型模型仅用 200K 参数就达到了 76.9% 的精确匹配 。
文章图片
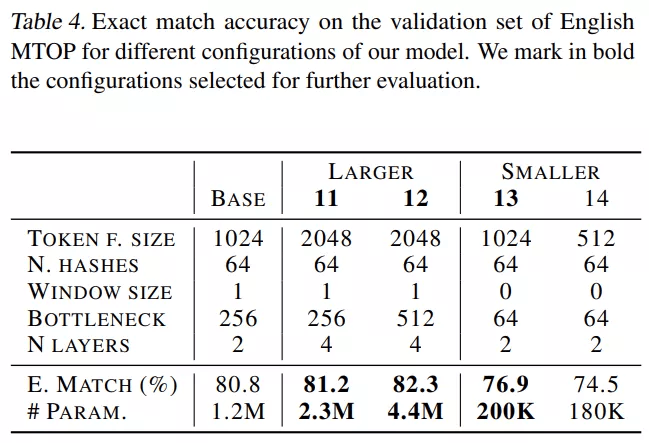
表 5 结果表明 , 大型语言模型 XLM-R 和 mBERT 获得了最高分 。 值得注意的是 , 从较小的替代方案来看 , pNLPMixer X-LARGE 只有 4.4M 参数 ,mBERT 参数量达 170M , 平均精确匹配准确率仅比 mBERT 和 XLM-R 低 2 和 3 个点 。 LARGE 模型具有与 pQRNN 相似的大小 , 比 pQRNN 精确匹配准确率高近 3% , 比精馏后的 pQRNN 高 0.8% 。
文章图片
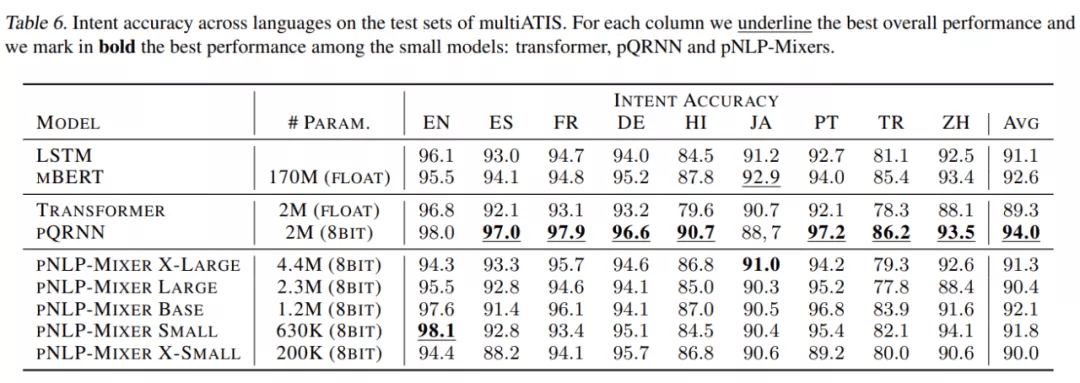
表 6 是在 multiATIS 数据集上的评估结果 。 在这里 , pQRNN 获得了最高的 intent 准确率 , 甚至比 mBERT 高出 1.8% 。 在 pNLP-Mixer 系列中 , 我们看到更大的尺寸并不对应更好的性能;由于 ATIS 查询中使用的词汇相对统一和简单 , 因此表达能力更强的模型不一定更好 。 事实上 , BASE 模型在 pNLP-Mixers 中达到最高分 , 达到 92.1% , 仅比只有 1.2M 参数的 mBERT 低 0.5% , 但参数只有 pQRNN 参数的 60% 。 较小的 pNLP-Mixer 模型 SMALL 和 X-SMALL 分别获得了 91.8% 和 90.0% 的竞争性能 , 而参数都非常小 。
文章图片
长序列实验
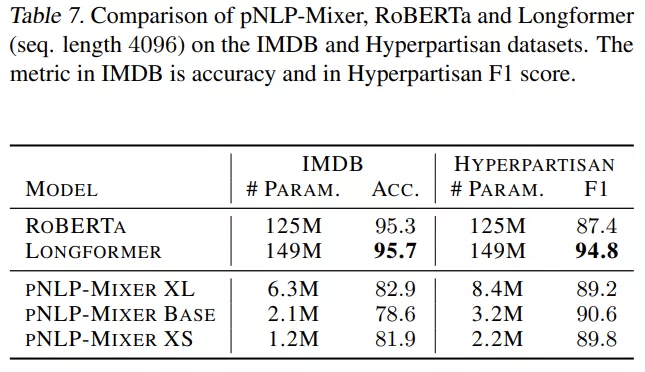
表 7 显示 , 在 IMDB 中 , RoBERTa 和 Longformer 的性能明显优于 pNLP-Mixer , Longformer 的准确率达到 95.7% , 而最好的 pNLP-Mixer 只有 82.9% 。 然而 , 在 Hyperpartisan 任务中 , Longformer 仍然是最好的模型 , 而 pNLP-Mixers 的表现优于 RoBERTa ,BASE 模型达到 90.6 F1 , 即高出 3.2 分 。
文章图片
微型 pNLP-Mixer 模型的参数分别是 Longformer 和 RoBERTa 参数的 1/ 120 倍和 1/ 100, 在 Hyperpartisan 任务中获得了具有竞争力(甚至优于 RoBERTa)的结果 , 而无需任何预训练或超参数调整 。 然而 , pNLP-Mixer 在 IMDB 上的性能较低 。 总而言之 , 这个结果提出了一个问题 , 即具有预训练的大型 pNLP-Mixer 是否可以成为大型 Transformer 模型的轻量级替代品 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。