研究者描述了如何使用局部注意力和全局注意力来高效地近似 GAU 的注意力 。
每个块的局部注意力 。 局部二次注意力独立地应用于每个长度为 C 的块以生成部分预门控状态(pre-gating state) 。

文章图片
跨块(across chunks)的全局注意力 。 一个全局线性注意力机制被部署来捕获跨块的长程交互 。
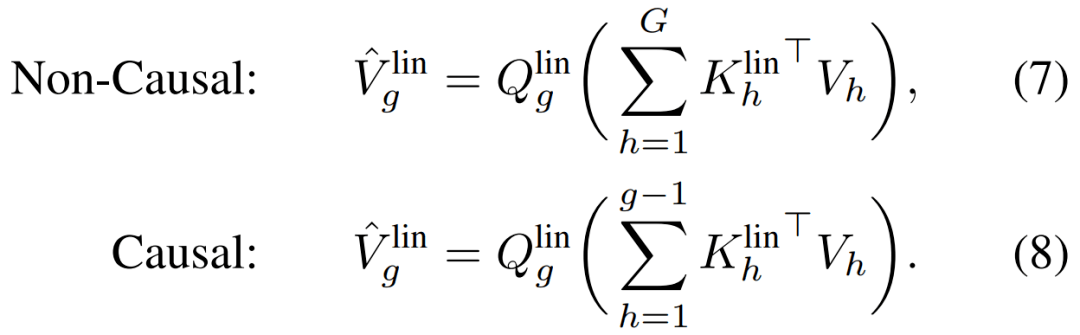
文章图片
下图为混合块注意力的伪代码 。

文章图片
实验结果
为了证明模型的效率和泛化能力 , 该研究在多个大规模数据集上对模型进行了评估 。
双向语言建模
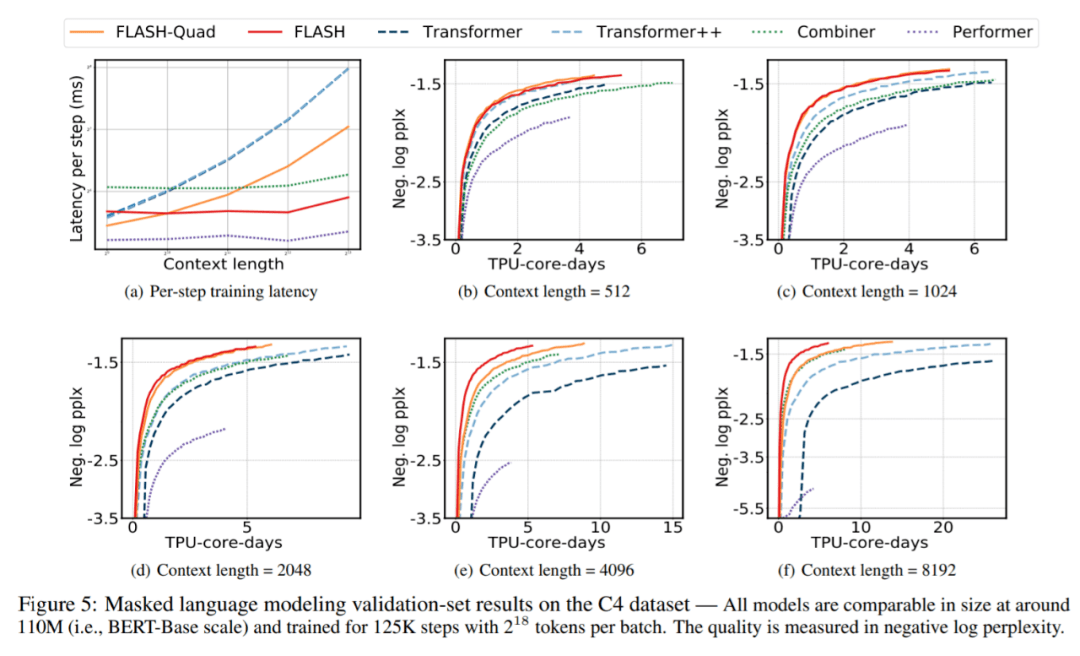
该研究在 C4 数据集上预训练和评估所有模型(Raffel 等人 , 2020) , 图 5(a) 显示了所有模型在不同上下文长度下每个训练 step 的延迟 。
在所有六个模型中 , 随着上下文长度的增加 , Combiner、Performer 和 FLASH 的延迟大致保持不变 , 这证明了上下文长度的线性复杂性 。 对于所有上下文长度 , FLASH-Quad 始终比 Transformer 和 Transformer++ 快 。 特别是 , 当上下文长度增加到 8192 时 , FLASH-Quad 的速度是 Transformer++ 的 2 倍 。
更重要的是 , 如图 5(b)-5(f) 所示 , 对于从 512 到 8192 的所有序列长度 , Google AI 的模型总是在相同的计算资源下达到最好的质量(即最低的困惑度) 。 特别是 , 如果目标是在 125K step 匹配 Transformer++ 的最终困惑度 , FLASH- Quad 和 FLASH 可以分别减少 1.1×-2.5× 和 1.0×-4.8× 的训练成本 。 值得一提的是 , FLASH 是唯一一个与其二次复杂度对应物实现竞争性困惑度的线性复杂度模型 。
文章图片
自回归语言建模
从图 6(a) 可以看出 , 在二次复杂度和线性复杂度模型中 , FLASH- quad 和 FLASH 的延迟最小 。 在图 6(b)-6(f) 中 , Google AI 比较了在 Wiki40-B 上所有模型在增加上下文长度时的质量和训练成本之间的权衡 。 与 MLM 任务类似 , Google AI 的模型在在质量和训练速度方面优于所有其他模型 。
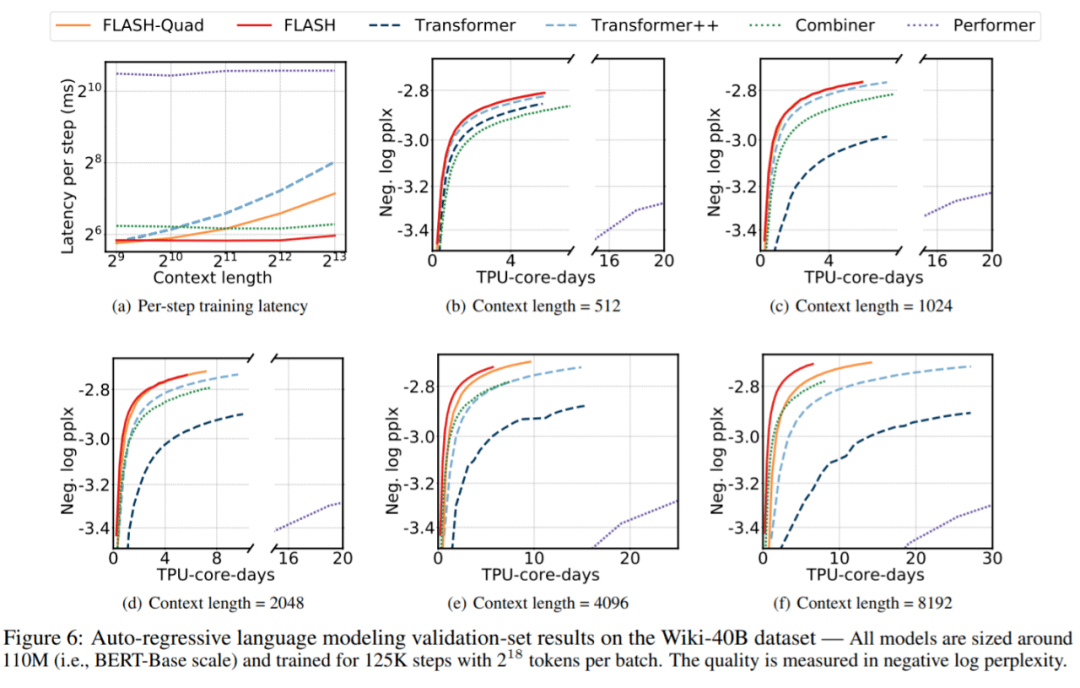
文章图片
Google AI 还在 PG-19 数据集上进行了实验 , 结果如表 3 所示 。 与 Wiki-40B 相比 , 在 PG-19 上 , FLASH 在困惑度和训练时间上比 Transformer + 获得了更显著的改善 。 例如 , 在上下文长度为 8K 的情况下 , FLASH-Quad 和 FLASH 只需 55K 和 55K step 即可达到 Transformer+ 的最终困惑度(125K step) , 分别产生 5.23 倍和 12.12 倍的加速 。
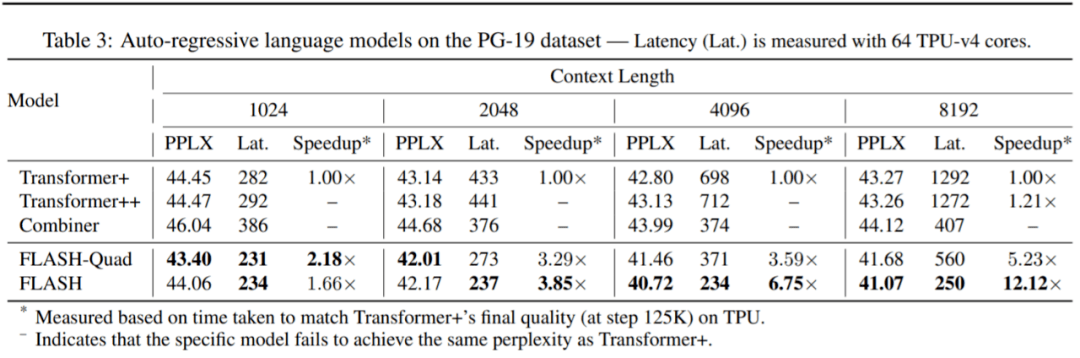
文章图片
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。