解决Transformer训练难题,微软研究院把Transformer干到了1000层( 二 )

文章图片
down-scale第l层的权重 。 例如 , 第l层 FFN 的输出投影
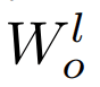
文章图片
被初始化为
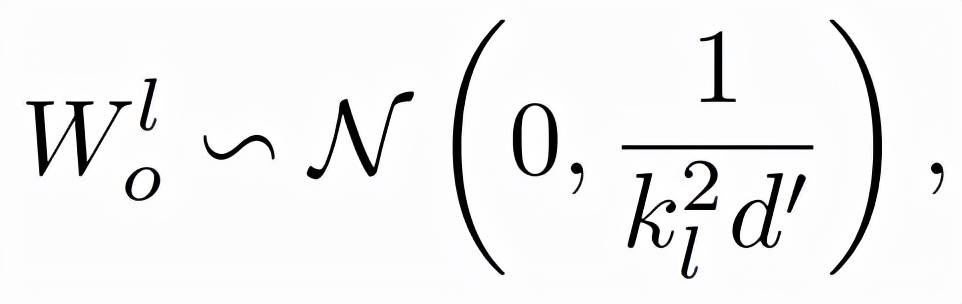
文章图片
其中d’是输入和输出维度的平均值 。 研究者将此模型命名为 Post-LN-init 。 请注意 , 与之前的工作(Zhang et al., 2019a)不同 ,Post-LN-init是缩窄了较低层的扩展而不是较高层 。 研究者相信这种方法有助于将梯度扩展的影响与模型更新区分开来 。 此外 , Post-LN-init 与 Post-LN 具有相同的架构 , 从而消除了架构的影响 。
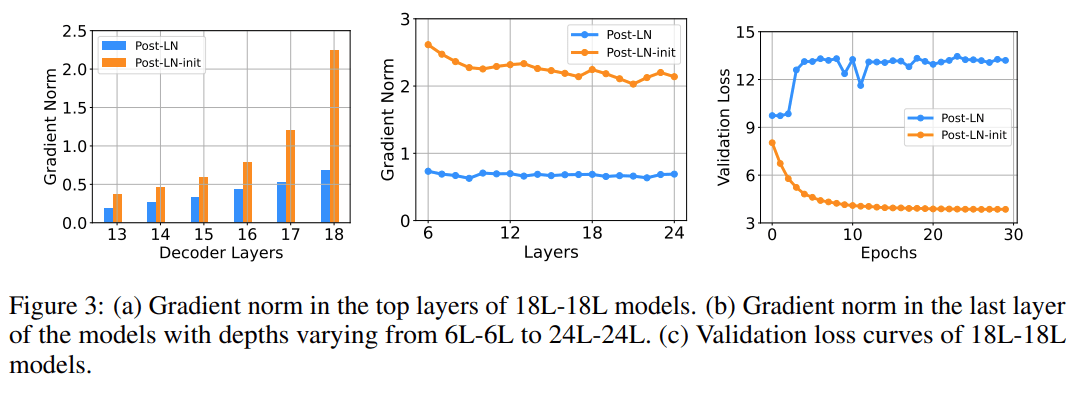
该研究在 IWSLT-14 De-En 机器翻译数据集上训练了 18L-18L Post-LN 和 18L-18L Post-LN-init 。 图 3 可视化了它们的梯度和验证损失曲线 。 如图 3(c) 所示 , Post-LN-init 收敛 , 而 Post-LN 没有 。Post-LN-init 在最后几层中具有更大的梯度范数 , 尽管其权重已按比例缩小 。 此外 , 研究者可视化最后一个解码器层的梯度范数 , 模型深度从 6L-6L 到 24L-24L 。
下图 3 显示 , 无论模型深度如何 , 最后一层 Post-LN-init 的梯度范数仍远大于 Post-LN 的梯度范数 。 得出的结论是 , 深层梯度爆炸不应该是 Post-LN 不稳定的根本原因 , 而模型更新的扩展往往可以解释这一点 。
文章图片
然后研究者证明 Post-LN 的不稳定性来自一系列问题 , 包括梯度消失以及太大的模型更新 。 如图 4(a) 所示 , 他们首先可视化模型更新的范数 ||ΔF||在训练的早期阶段:
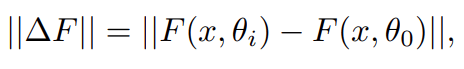
文章图片
其中x和θ_i分别代表输入和第i次更新后的模型参数 。 Post-LN在训练一开始就有爆炸式的更新 , 然后很快就几乎没有更新了 。 这表明该模型已陷入虚假的局部最优 。
warm-up和更好的初始化都有助于缓解这个问题 , 使模型能够顺利更新 。 当更新爆炸时 , LN 的输入会变大(见图 4(b) 和图 4(c)) 。 根据Xiong等人(2020)的理论分析 , 通过 LN 的梯度大小与其输入的大小成反比:
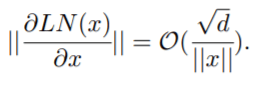
文章图片
相比于没有warm-up或正确初始化的情况 , 图 4(b) 和图 4(c) 表明 ||x||的明显大于
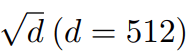
文章图片
。 这解释了 Post-LN 训练中出现的梯度消失问题(见图 4(d)) 。
最重要的是 , 不稳定性始于训练开始时的大型模型更新 。 它使模型陷入糟糕的局部最优状态 , 这反过来又增加了每个 LN 的输入量 。 随着训练的继续 , 通过 LN 的梯度变得越来越小 , 从而导致严重的梯度消失 , 使得难以摆脱局部最优 , 并进一步破坏了优化的稳定性 。 相反 , Post-LN-init 的更新相对较小 , 对 LN 的输入是稳定的 。 这减轻了梯度消失的问题 , 使优化更加稳定 。
DeepNet:极深的Transformer模型 研究者首先介绍了极深的Transformer模型——DeepNet , 该模型可以通过缓解爆炸式模型更新问题来稳定优化过程 。
DeepNet基于Transformer架构 。 与原版Transformer相比 , DeepNet在每个子层使用了新方法DEEPNORM , 而不是以往的Post-LN 。 DEEPNORM的公式如下所示 。
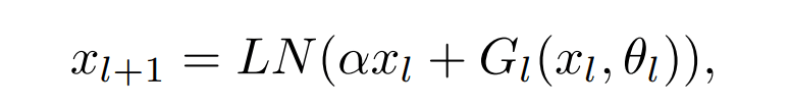
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。