解决Transformer训练难题,微软研究院把Transformer干到了1000层( 三 )
文章图片
其中 , α是一个常数 , G_l(x_l , θ_l)是参数为θ_l的第l个Transformer子层(即注意力或前馈网络)的函数 。 DeepNet还将残差内部的权重θ_l扩展了β 。
接着 , 研究者提供了对DeepNet模型更新预期大小(expected magnitude)的估计 。
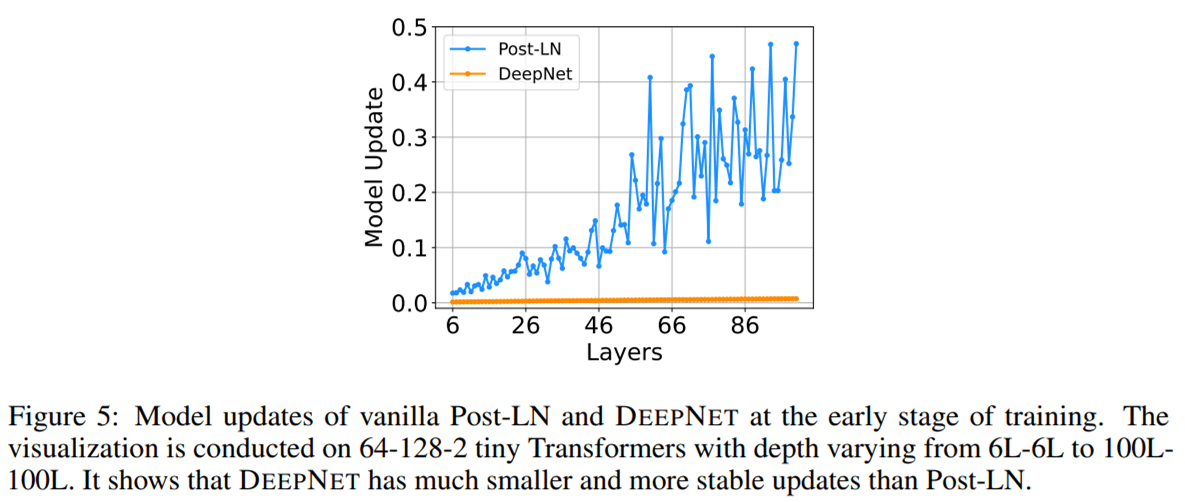
他们可视化了IWSLT-14 De-En翻译数据集上 , Post-LN和DeepNet在早期训练阶段的模型更新情况 , 如下图5所示 。 可以看到 , 相较于Post-LN , DeepNet的模型更新几乎保持恒定 。
文章图片
最后 , 研究者提供理论分析 , 以表明 DeepNet的更新受到了 DEEPNORM 的常数限制 。 具体地 , 他们展示了 DeepNet的预期模型更新受到了适当参数α 和 β的常数限制 。 研究者的分析基于 SGD 更新 , 并通过实证证明对 Adam 优化器效果很好 。
研究者提供了对编码器-解码器架构的分析 , 它能够以相同的方式自然地扩展到仅编码器和仅解码器的模型 。 具体如下图所示 , 他们将模型更新的目标设定如下:
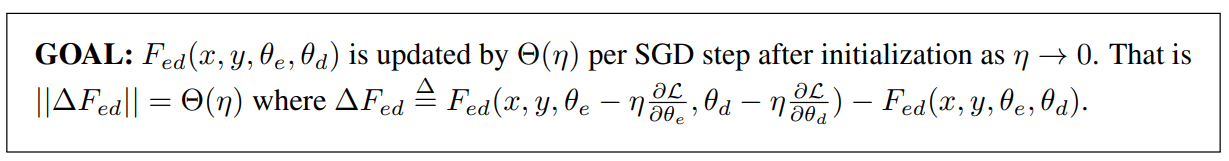
文章图片
仅编码器(例如 BERT)和仅解码器(例如 GPT)架构的推导能够以相同的方式进行 。 研究者将步骤总结如下:

文章图片
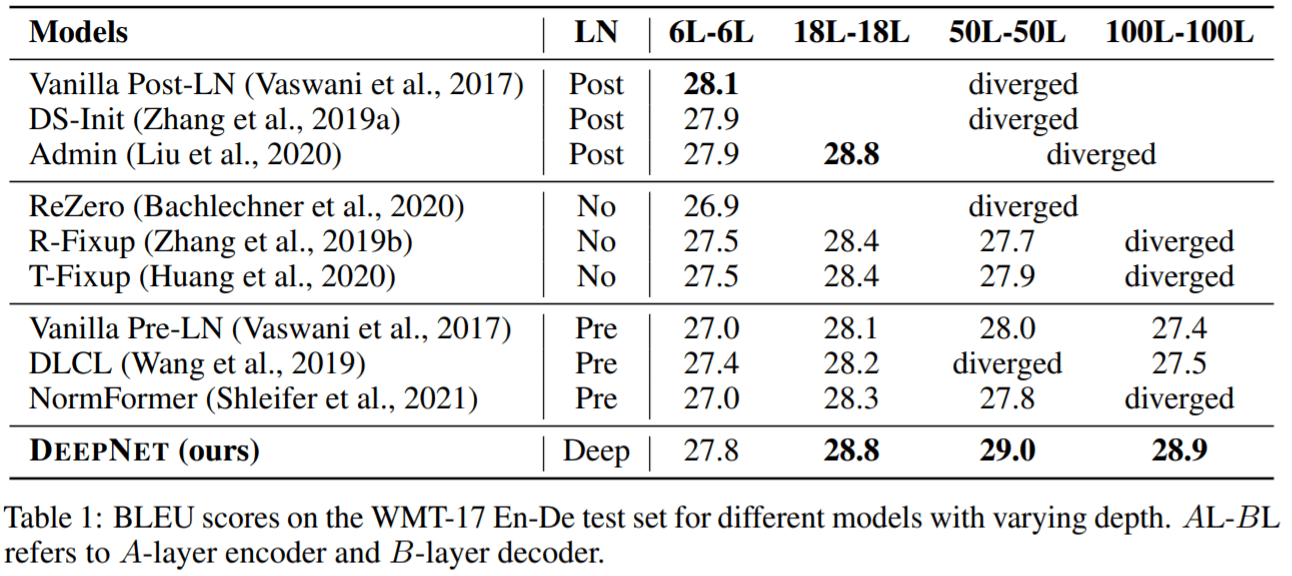
神经机器翻译 该研究验证了DeepNet 在流行的机器翻译基准上的有效性 , 包括 IWSLT-14 德语-英语 (De-En) 数据集和 WMT-17 英语-德语 (En-De) 数据集 。 该研究将DeepNet 与多个SOTA深度 Transformer 模型进行比较 , 包括 DLCL 、NormFormer 、ReZero 、R- Fixup 、T-Fixup 、DS-init 和 Admin 。
表 1 报告了 WMT-17 En-De 翻译数据集上的基线和DeepNet 的结果:
文章图片
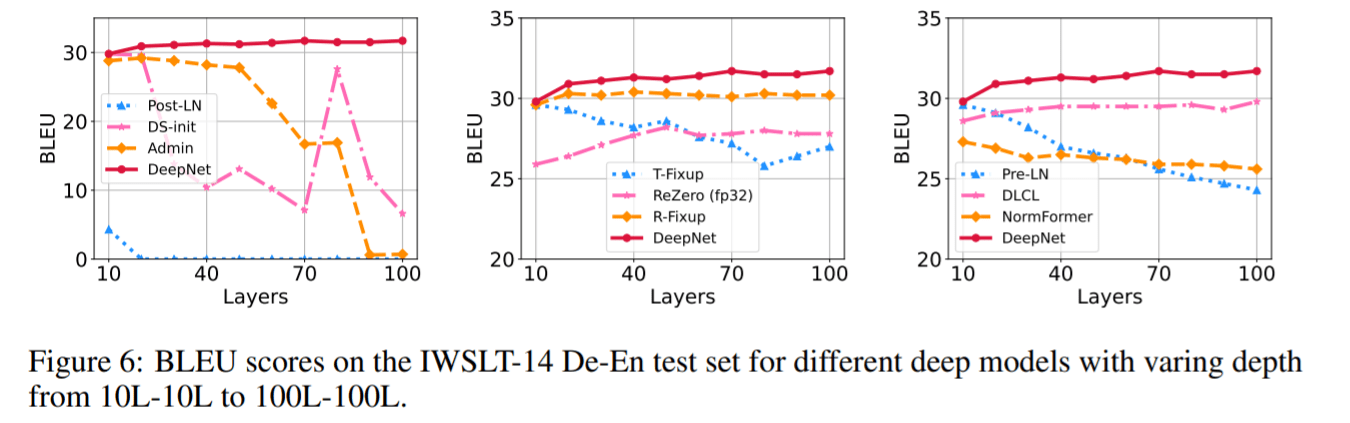
图 6 显示了 IWSLT-14 数据集的结果
文章图片
图 7 报告了 WMT-17 验证集的损失曲线
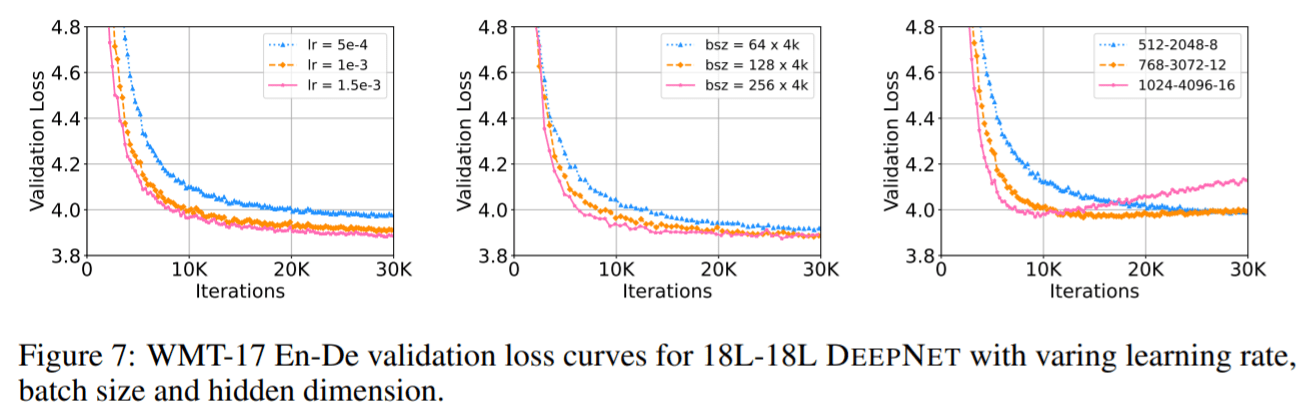
文章图片
大规模多语言神经机器翻译 该研究首先使用 OPUS-100 语料库来评估模型 。 OPUS100 是一个以英语为中心的多语言语料库 , 涵盖 100 种语言 , 是从 OPUS 集合中随机抽取的 。 该研究将 DeepNet 扩展到 1,000 层 , 该模型有一个 500 层的编码器、 500 层的解码器、512 个隐藏大小、8 个注意力头和 2,048 维度的前馈层 。
表2总结了 DeepNet 和基线的结果 。 结果表明 , 增加网络深度可以显着提高 NMT 的翻译质量:48 层的模型比 12 层的模型平均获得 3.2 点的提高 。DeepNet 可以成功地将深度扩展到 1,000 层 , 比基线提高4.4 BLEU 。 值得注意的是 , DeepNet 只训练了 4 个 epoch , 并且在计算预算更多的情况下 , 性能可以进一步提高 。
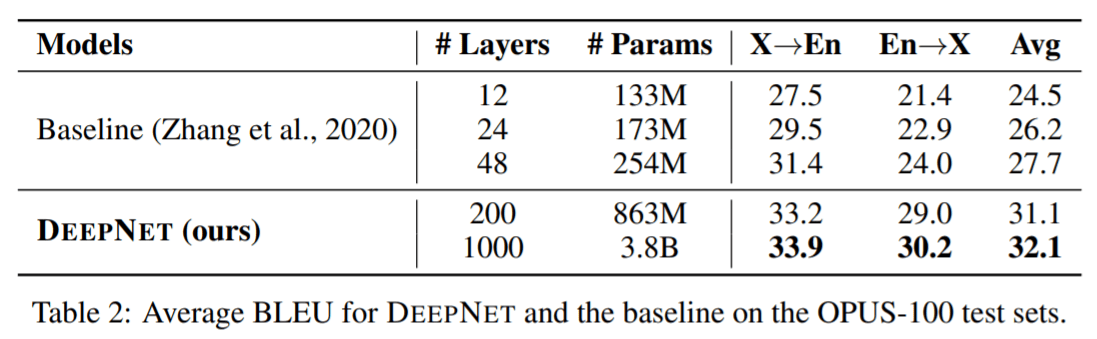
文章图片
深度扩展规律:该研究在OPUS100数据集上训练具有{12,20,100,200,1000}层的DeepNet , 图8显示了深度扩展曲线 。 与双语NMT相比 , 多语NMT从扩展模型深度受益更多 。 可以观察到多语 NMT 的 BLEU 值呈对数增长 , 规律可以写成:L(d) = A log(d) + B , 其中d是深度 , A, B是关于其他超参数的常数 。
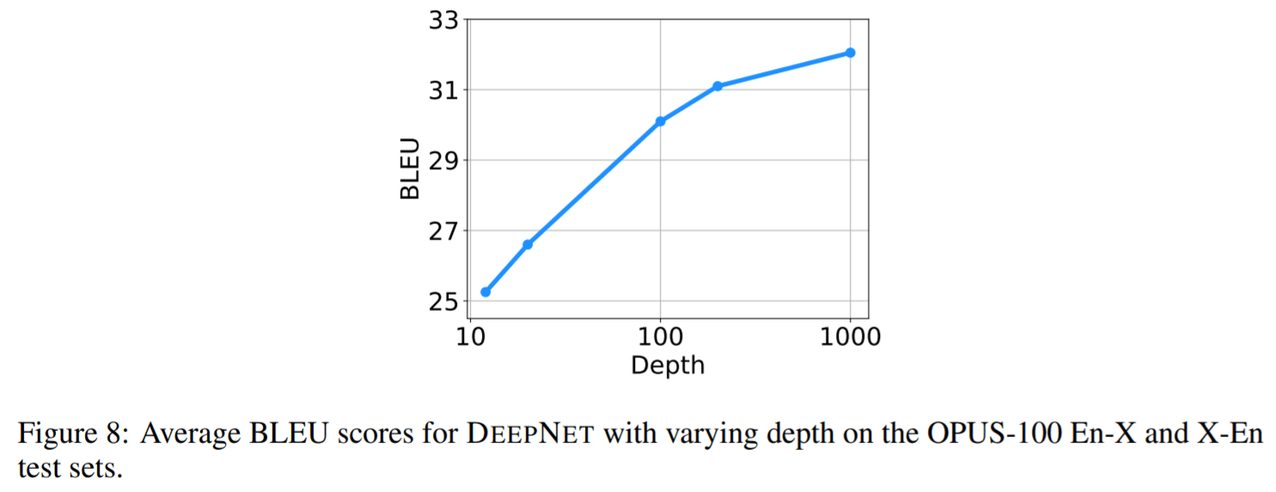
文章图片
更多数据和语言说明:为了探索DeepNet在多语NMT上的局限性 , 该研究随后使用Schwenk等人提出的CCMatrix扩展训练数据 。 此外 , 该研究还扩展了CCAligned 、OPUS 和Tatoeba的数据 , 以涵盖Flores101评估集的所有语言 。 最终的数据由102种语言、1932个方向和12B对句子组成 。 利用这些数据 , 该研究用100层编码器、100层解码器、1024个隐藏维度、16个头、4096个前馈层中间维度对DeepNet进行训练 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。