数小时前刚出炉的论文《DeepNet: Scaling Transformers to 1,000 Layers》 , 来自微软研究院 。
该研究直接把Transformer深度提升到1000层!
下面让我们看下这篇研究说了什么 。
近年来 , 大规模 Transformer模型出现了这样一种趋势:随着模型参数从数百万增加至数十亿甚至数万亿 , 性能相应地实现了显著提升 。 大规模模型在一系列任务上都取得了SOTA性能 , 并在小样本和零样本学习设置下展现出了令人瞩目的能力 。 如下图1所示 , 尽管参数量已经很大了 , 但Transformer模型的深度(depth)却受到了训练不稳定的限制 。
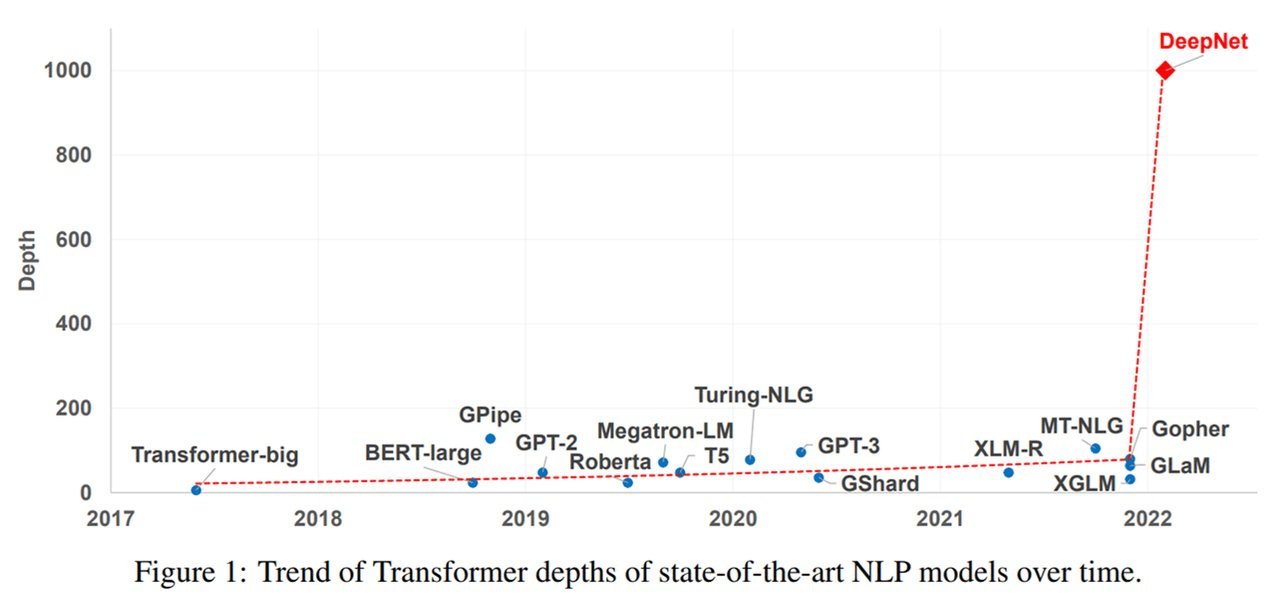
文章图片
Nguyen和Salazar (2019)发现 , 基于post-norm连接(Post-LN) , pre-norm 残差连接(Pre-LN)能够提升 Transformer的稳定性 。 但是 , Pre-LN在底层的梯度往往大于顶层 , 因而导致与 Post-LN相比性能下降 。 为了缓解这一问题 , 研究人员一直努力通过更好的初始化或更好的架构来改进深度Transformer的优化 。 这些方法可以使多达数百层的Transformer模型实现稳定化 , 然而以往的方法没有能够成功地扩展至1000层 。
微软研究院在一篇新论文《DeepNet: Scaling Transformers to 1,000 Layers》中终于将Transformer的深度扩展到了1000层 。

文章图片
论文地址:
https://arxiv.org/pdf/2203.00555.pdf
研究者的目标是提升 Transformer 模型的训练稳定性 , 并将模型深度进行数量级的扩展 。 为此 , 他们研究了不稳定优化的原因 , 并且发现爆炸式模型更新是造成不稳定的罪魁祸首 。 基于这些观察 , 研究者在残差连接处引入了一个新的归一化函数 —— DEEPNORM , 它在将模型更新限制为常数时具有理论上的合理性 。 这一方法简单但高效 , 只需要改变几行代码即可 。 最终 , 该方法提升了Transformer模型的稳定性 , 并实现了将模型深度扩展到了1000多层 。
此外 , 实验结果表明 , DEEPNORM 能够将 Post-LN 的良好性能和Pre-LN的稳定训练高效结合起来 。 研究者提出的方法可以成为Transformers的首选替代方案 , 不仅适用于极其深(多于1000层)的模型 , 也适用于现有大规模模型 。 值得指出的是 , 在大规模多语言机器翻译基准上 , 文中 32 亿参数量的 200 层模型(DeepNet)比120亿参数量的48层SOTA模型(即 Facebook AI的M2M模型)实现了 5% 的BLEU值提升 。
DEEPNORM方法 如下图2所示 , 使用 PostLN 实现基于 Transformer 的方法很简单 。 与 Post-LN 相比 , DEEPNORM 在执行层归一化之前up-scale了残差连接 。

文章图片
(图注)图2:(a) DEEPNORM 的伪代码 , 例如可以用其他标准初始化代替 Xavier 初始化 (Glorot and Bengio, 2010), 其中α是一个常数 。 (b) 不同架构的 DEEPNORM 参数(N 层编码器 , M 层解码器) 。
此外 , 该研究还在初始化期间down-scale了参数 。 值得注意的是 , 该研究只扩展了前馈网络的权重 , 以及注意力层的值投影和输出投影 。 此外 , 残差连接和初始化的规模取决于图2中不同的架构 。
深度Transformer的不稳定性 该研究分析了深度Transformer不稳定的原因 。
首先 , 研究者观察发现:更好的初始化方法可以让 Transformer 的训练更稳定 。 之前的工作(Zhang et al., 2019a; Huang et al., 2020; Xu et al., 2021)也证实了这一点 。
因此 , 研究者分析了有无适当初始化的 Post-LN 的训练过程 。 通过更好的初始化 , 在执行 Xavier 初始化后通过
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。