文章图片
动态轴并行
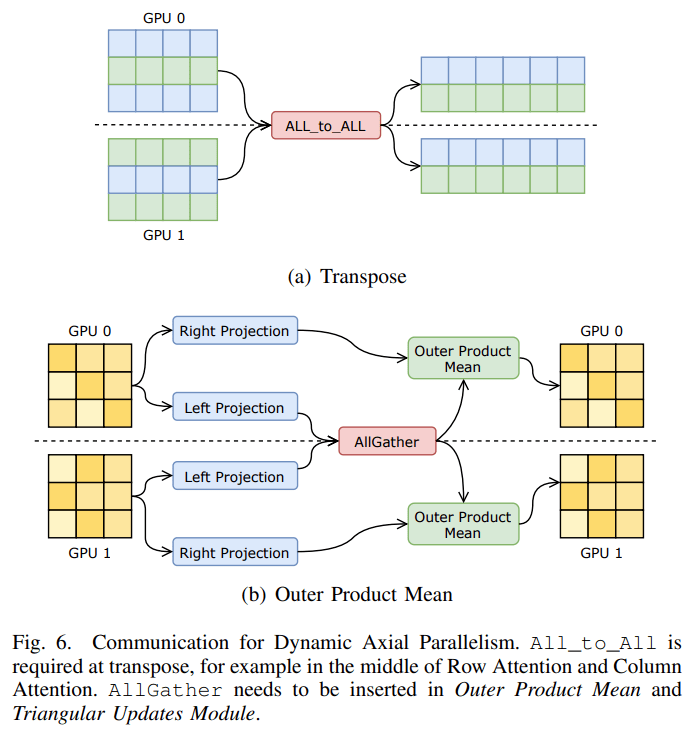
在并行策略方面 , 该研究根据 AlphaFold 的计算特征创新性地提出了动态轴并行策略 , 在 AlphaFold 的特征的序列方向上进行数据划分 , 并使用 All_to_All 进行通信 。 动态轴并行(DAP)在扩展效率方面优于当前的标准张量并行(Tensor Parallelism) , DAP 具有以下几个优势:
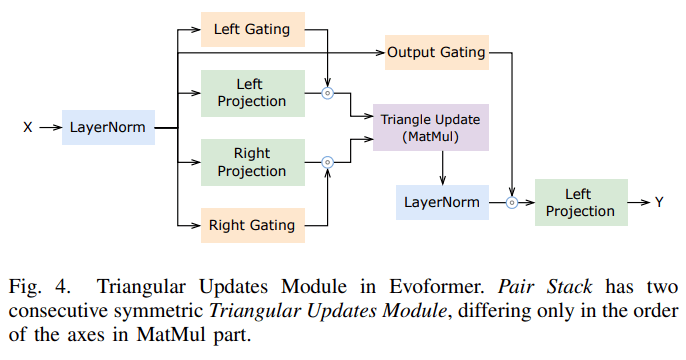
- 支持 Evoformer 中的所有计算模块;
- 所需的通信量比张量并行小得多;
- 显存消耗比张量并行低;
- 给通信优化提供了更多的空间 , 如计算通信重叠 。
文章图片
通信优化
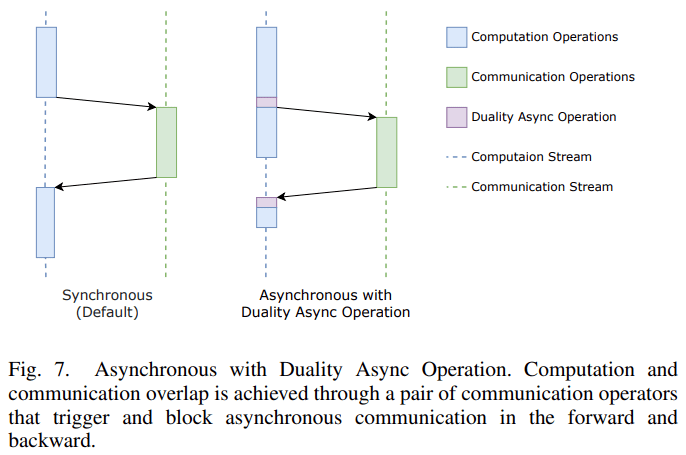
在通信方面 , 该研究提出了由一对通信算子组成的对偶异步算子(Duality Async Operation) 。
这种新方法在模型前向传播的过程中 , 前一个通信算子触发异步通信 , 然后在计算流上进行一些没有依赖性的计算 , 然后后一个通信算子阻塞 , 直到通信完成;在反向传播的过程中 , 后一个算子将触发异步通信 , 前一个算子阻塞通信 。
利用对偶异步算子可以很容易地在 PyTorch 这样的动态框架上实现前向传播和反向传播中的计算和通信遮叠 。
文章图片
评估
研究者首先评估了 Evoformer 内 核的性能改进 , 然后对端到端训练和推理性能进行了评估 。 所有的实验都在 NVIDIA Tesla A100 平台上进行 。 基线是 AlphaFold 的官方实现和另一个 OpenFold 开源 PyTorch 实现 。 官方实现的 AlphaFold 只有推理部分 , 而 OpenFold 则是根据原始 AlphaFold 论文复制训练和推理的 。
A. Evoformer 性能
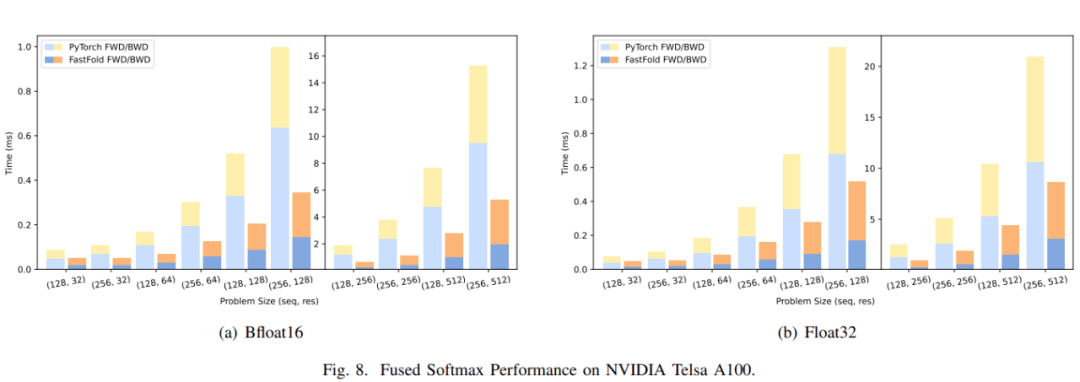
图 8(a)和图 9(a)分别展示了 Fused Softmax 和 LayerNorm 的性能比较 。
对于 Fused Softmax , 研究者比较了 PyTorch 原生内核和 FastFold 优化内核的性能 。 注意力输入序列的长度是 x , 注意力的隐藏大小是 y 。 从图 8(a)可以看出 , FastFold 内核的性能可以提高 1.77~3.32 倍。
文章图片
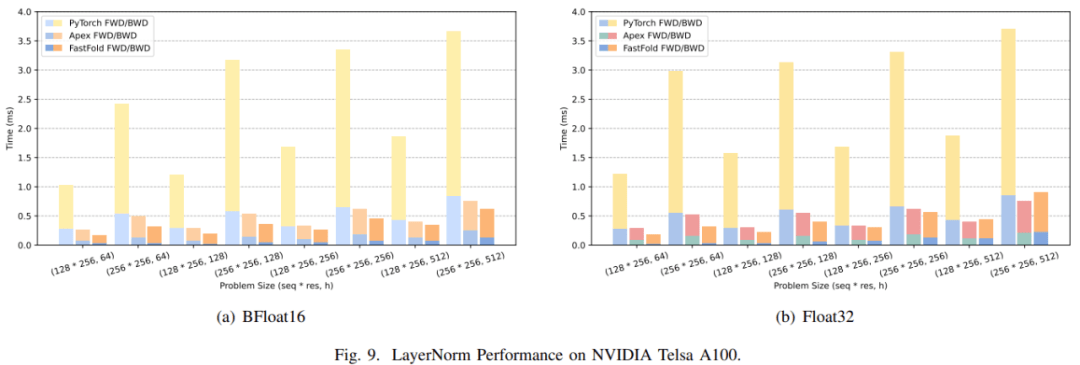
对于 LayerNorm , 研究者不仅比较了 PyTorch 原生内核 , 还比较了 NVIDIA Apex 中高度优化的 LayerNorm 内核 。 如图 9(a), FastFold 的性能比 PyTorch 和 Apex 分别提高了 5.53~8.65 倍 和 1.20~1.62 倍。 由于对有限范围的特别优化 , 相比于高度优化的 Apex LayerNorm , FastFold 也实现了良好的性能改进 。
文章图片
B. 端到端训练性能
在端到端训练表现的评估中 , 研究者使用官方 AlphaFold 文件中的训练参数进行了尽可能多的测试 。 这样可以更好地比较不同的方法或实现在实际的训练场景中的工作方式 。 所有的训练实验都是在 128 节点的 GPU 超级计算机上进行的 。 在超级计算机中 , 每个节点包括 4 台 NVIDIA Tesla A100 , 并且有 NVIDIA NVLink 用于 GPU 互连 。
由于张量并行更多地依赖于设备之间的高速互连来进行通信 , 在训练期间 , 模型并行通常用于节点以及训练期间节点之间的数据并行 。 研究者分别在模型并行和数据并行两个级别测试了模型的训练性能 , 结果如图 10 和图 11 所示 。 在模型并行性方面 , 论文比较了张量并行和动态轴并行两种并行方法在初始训练和微调两种训练设置下的 scalability 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。