
文章图片
如图 10 所示 , 在初始训练和微调方面 , DAP 的扩展性能明显优于 TP 。

文章图片
扩展结果如图 11 所示 。 我们可以看到 , 在接下来的几个平行里 , 基本上是线性规模的 。 微调训练的扩展效率达到 90.1%。
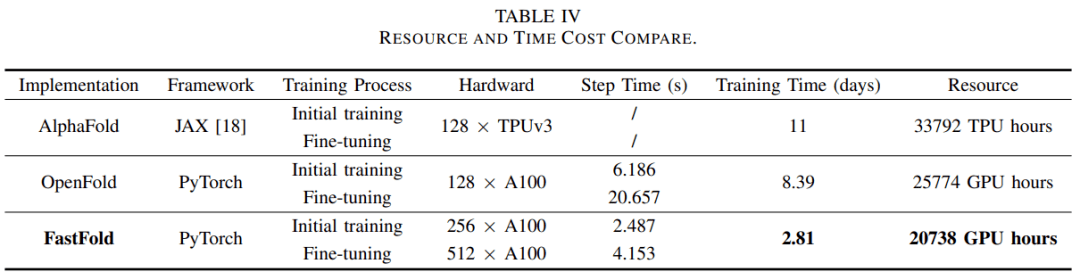
根据训练效果的评估结果 , 可以推算出 AlphaFold 的总体时间和经济成本 。 表 IV 列出并比较了 AlphaFold、 OpenFold 和 FastFold 三种实现的时间和经济成本 。 由于没有公开的训练代码 , 所以 AlphaFold 的数据来源于官方文件 。
文章图片
考虑到时间和经济成本 , 研究者选用了 256 个 A100 进行初始训练 , 然后在微调阶段扩展到 512 个 A100 。
基于这种设置 , FastFold 可以将训练时间减少到 2.81 天 。 与需要 11 天训练的 AlphaFold 相比 , 训练的时间成本减少了 3.91 倍 。 与 OpenFold 相比 , 训练的时间成本降低了 2.98 倍 , 经济成本降低了 20%。
在微调阶段 , FastFold 在 512 × A100 的设置下实现了 6.02 PetaFLOPs 的计算速度 。 由于时间和经济成本的显著降低 , FastFold 使得蛋白质结构预测模型的训练速度更快、成本更低 , 这将推动相关模型的研究和开发效率 , 并促进基于 Evoformer 的蛋白质结构预测模型的开发 。
C. 端到端推理性能
【512块A100,AlphaFold训练时间压缩至67小时:尤洋团队FastFold上线】针对短序列、长序列和超长序列 , 研究者对比了 FastFold、OpenFold、AlphaFold 的推理性能 。 所有推理实验均在由 8 个 NVIDIA A100(带有 NVLink)组成的 GPU 服务器上完成 。
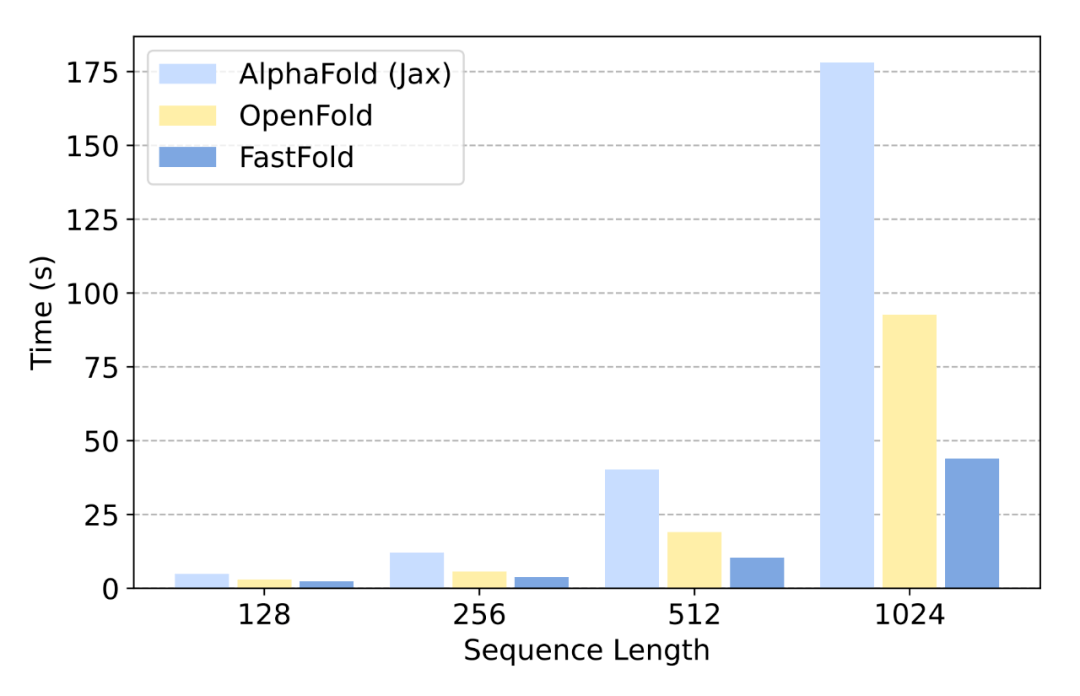
对于短序列 , 典型的氨基酸序列长度不超过 1k , 单个模型推理需要几秒钟到大约一分钟 。 在这个序列范围内 , 视频内存消耗相对较小 , 分布式推理的效率较低 。
研究者在 1 个 GPU 上比较了三种实现的推理延迟 , 结果如图 12 所示:
文章图片
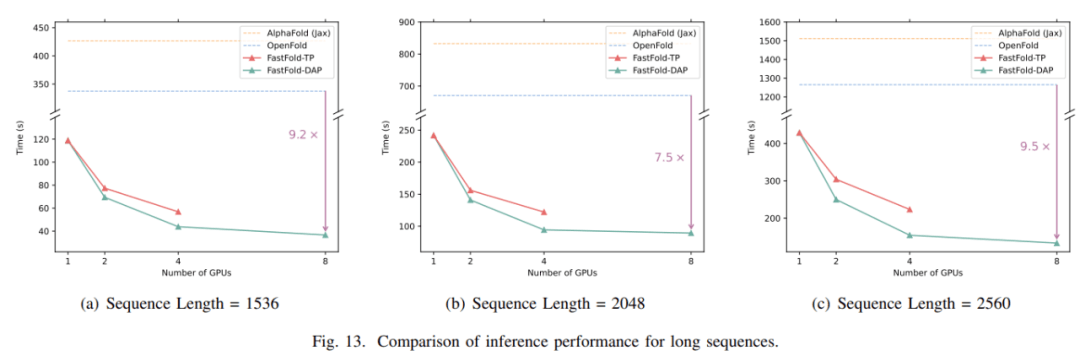
对于长度为 1k 到 2.5 k 的氨基酸序列的长序列推断 , 直接推理会遇到内存容量问题 , 推理时间达到几分钟甚至几十分钟 。 对于 FastFold , 采用分布式推理方法可以减少内存容量的需求 , 显著缩短推理时间 。 如图 13 所示 , 当使用分布式推理时 , FastFold 比 OpenFold 减少推理时间 7.5~9.5 倍, 比 AlphaFold 减少推理时间 9.3~11.6 倍。
文章图片
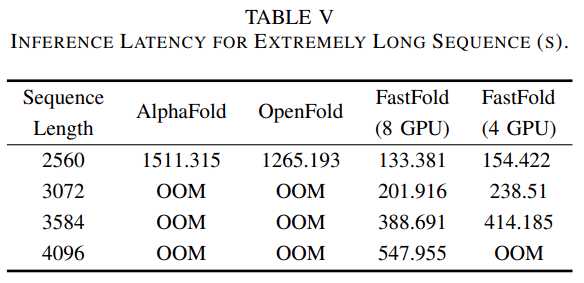
如表 3 所示 , 对于 AlphaFold 和 OpenFold , 当序列长度达到 3k 之上时 , 都会遇到内存不足 (OOM) 问题 。 然而 , 对于 FastFold , 由于分布式推理方法 , 它可以利用 GPU 更多的计算和内存来完成极长的序列推理 。 此外 , 对于长度高达 4k 的序列 , FastFold 的推理延迟 在 10 分钟之内 。
文章图片
作者介绍

文章图片
本文的作者之一尤洋现为新加坡国立大学计算机系任助理教授 。 2020 年 , 尤洋在加州大学伯克利分校计算机系获得博士学位 。
尤洋的主要研究方向是高性能计算与机器学习的交叉领域 , 当前研究重点为大规模深度学习训练算法的分布式优化 。 他曾其以一作作者的身份发表研究论文《Large Batch Optimization for Deep Learning :Training BERT in 76 Minutes》 , 提出了一种 LAMB 优化器(Layer-wise Adaptive Moments optimizer for Batch training) , 将超大模型 BERT 的预训练时间由 3 天缩短到了 76 分钟 , 刷新世界记录 。 到目前为止 , LAMB 仍为机器学习领域的主流优化器 , 成果被 Google、Facebook、腾讯等科技巨头在实际中使用 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。