双向:其在同一个联合训练设置中训练 Inputs2Targets 和 targets2input 。 附加一个 prefix token 以允许模型知道任务正在哪个方向执行 。
表示 Docids 用于检索
基于 seq2seq 的 DSI 模型中的检索是通过解码给定输入查询 docid 来完成的 。 如何有效地解码很大程度上取决于模型中 docid 的表示方式 。 在本节中 , 研究者探讨了表示 docid 的多种可能方式以及如何处理解码 。
非结构化原子标识符(Atomic Identifiers):表示文档最简单的方法是为每个文档分配一个任意的(并且可能是随机的)唯一整数标识符 , 该研究将这些标识符称为非结构化原子标识符 。 研究者要想使用这些标识符 , 一个明显的解码方式是学习标识符上的概率分布 。 在这种情况下 , 模型被训练为每个唯一的 docid (|Ndocuments|) 发出一个 logit 。 为了适应这种情况 , 该研究将标准语言模型的输出词汇表扩展如下:

文章图片
简单的结构化字符串标识符:该研究还考虑了另一种方法 , 将非结构化标识符 (即任意唯一整数) 视为可标记的(tokenizable)字符串 , 将其称为简单的结构化标识符 。 在此标识符下 , 检索是通过依次解码一个 docid 字符串来完成的 。 解码时 , 使用 beam search 来获得最佳 docid 。 但是 , 使用这种策略不容易获得 top-k 排名 。 不过 , 研究者可以彻底梳理整个 docid 空间 , 并获得给定查询的每个 docid 的可能性 。
语义结构化标识符:其目标是自动创建满足以下属性的标识符:(1) docid 应该捕获一些语义信息 , (2) docid 的结构应该是在每一个解码 step 之后有效地减少搜索空间 。 给定一个需要索引的语料库 , 所有文档都聚集成 10 个簇 。 每个文档分配有一个标识符 , 其簇的编号从 0 到 9 。 下表为这个进程的伪代码:

文章图片
实验结果
所有 DSI 模型均使用标准预训练 T5 模型配置进行初始化 。 配置名称和对应的模型参数数量为:Base (0.2B)、Large (0.8B)、XL (3B) 和 XXL (11B) 。 该研究用实验验证了上述各种策略的效果 。
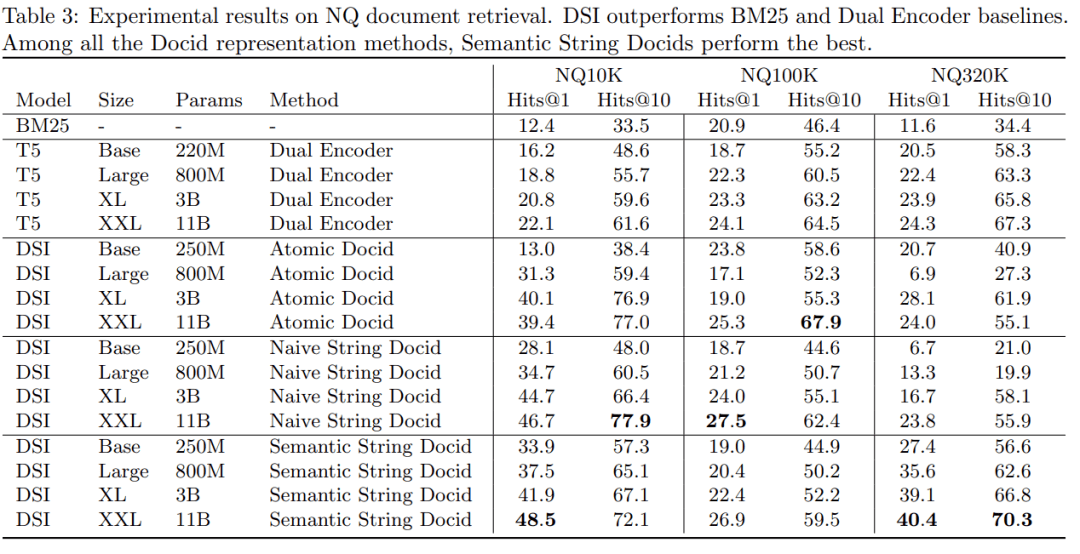
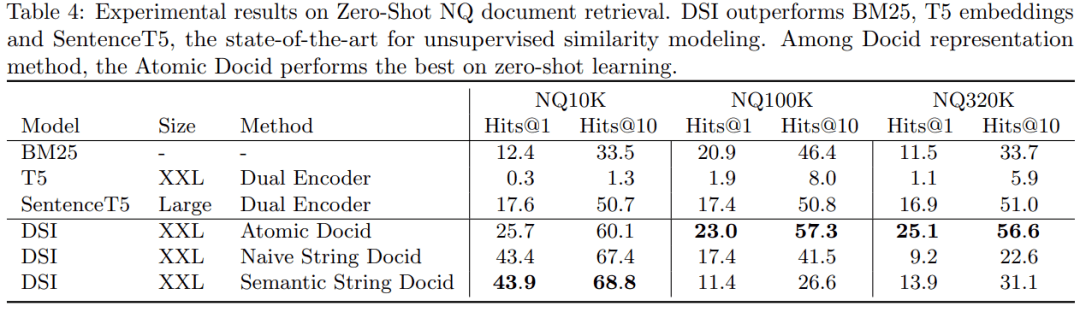
下表 3 给出了经过微调的 NQ10K、NQ100K 和 NQ320K 的检索结果 , 表 4 给出了零样本检索结果 。 对于零样本检索 , 模型仅针对索引任务而不是检索任务进行训练 , 因此模型看不到标记查询 → docid 数据点 。
文章图片
文章图片
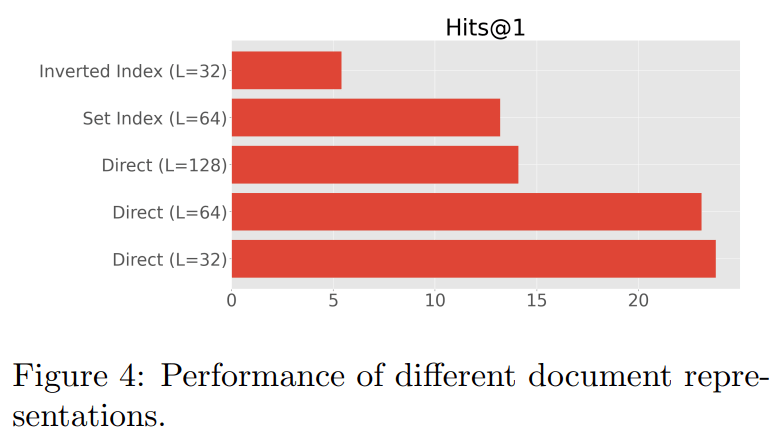
下图 4 给出了 NQ320K 上的结果 。 总的来说 , 研究者发现直接索引方法效果最好 , 并且由于 docid 反复暴露于不同的 token , 因此很难训练倒排索引( inverted index)方法 。 他们还发现 , 较短的文档长度似乎在性能大幅下降超过 64 个 token 时效果很好 , 这表明当存在大量文档 token 时 , 可能更难优化或有效记忆 。 最后 , 研究者还发现对文档 token 应用集合处理或停用词预处理没有额外的优势 。
文章图片
下图 3 绘制了三种方法的缩放表现(以对数尺度计) , 它们分别是 DE、具有 naive ID 的 DSI 和具有语义 ID 的 DSI 。 其中 , DSI (naive) 可以从 base 到 XXL 的尺度变化中获益 , 并且似乎仍有改进的空间 。 同时 , DSI (语义) 在开始时与 DE base 具有同等竞争力 , 但会随尺度增加表现得更好 。 DE 模型在较小的参数化时基本处于稳定状态 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。