选自arXiv
作者:Yi Tay等
机器之心编译
编辑:陈萍
谷歌提出基于 Transformer 的可微文本检索索引 , 明显优于双编码器模型等强大基线 , 并且还具有强大的泛化能力 , 在零样本设置中优于 BM25 基线 。信息检索 (Information Retrieval, IR) 从互联网诞生之日起 , 便有着不可撼动的地位 。 如何从海量数据中找到用户需要的信息是当前研究的热点 。 目前比较流行的 IR 方法是先检索后排序(retrieve-then-rank)策略 。 在检索算法中 , 比较常用的是基于反向索引或最近邻搜索 , 其中基于对比学习的双编码器 (dual encoders , DE) 是目前性能最优的模型 。
近日 , 谷歌研究院在论文《Transformer Memory as a Differentiable Search Index》中提出了一种替代架构 , 研究者采用序列到序列 (seq2seq) 学习系统 。 该研究证明使用单个 Transformer 即可完成信息检索 , 其中有关语料库的所有信息都编码在模型的参数中 。
该研究引入了可微搜索索引(Differentiable Search Index , DSI) , 这是一种学习文本到文本新范式 。 DSI 模型将字符串查询直接映射到相关文档;换句话说 , DSI 模型只使用自身参数直接回答查询 , 极大地简化了整个检索过程 。
此外 , 本文还研究了如何表示文档及其标识符的变化、训练过程的变化以及模型和语料库大小之间的相互作用 。 实验表明 , 在适当的设计选择下 , DSI 明显优于双编码器模型等强大基线 , 并且 DSI 还具有强大的泛化能力 , 在零样本设置中优于 BM25 基线 。

文章图片
论文链接:https://arxiv.org/pdf/2202.06991.pdf
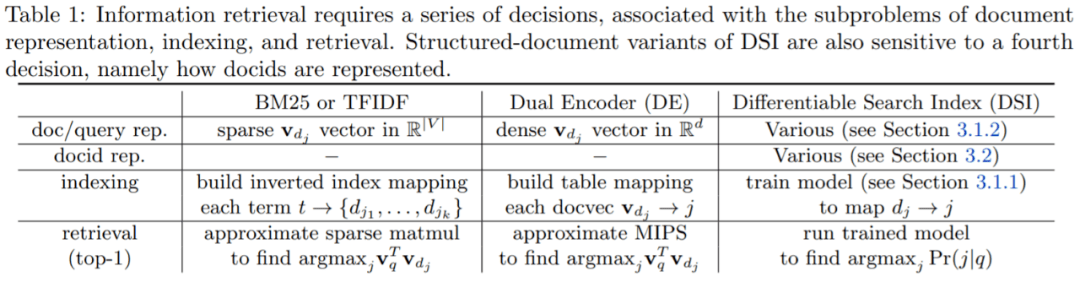
DSI 体系架构与 DE 比较:
文章图片
论文一作、谷歌高级研究员 Yi Tay 表示:在这个新范式中 , 检索的所有内容都映射到易于理解的 ML 任务上 。 索引是模型训练的一种特殊情况 , 不再依赖外部不可微的 MIPS 操作进行检索 。 这使得统一模型更容易 。

文章图片
可微搜索索引
DSI 背后的核心思想是在单个神经模型中完全参数化传统的多阶段先检索后排序 pipeline 。 为此 , DSI 模型必须支持两种基本操作模式:
- 索引:DSI 模型应该学会将每个文档内容 d_j 与其对应的 docid j ( 文档标识符 :document identifiers , docid)相关联 。 本文采用一种简单的序列到序列方法 , 将文档 token 作为输入并生成标识符作为输出;
- 检索:给定输入查询 , DSI 模型应返回候选 docid 排序列表 。 本文是通过自回归生成实现的 。
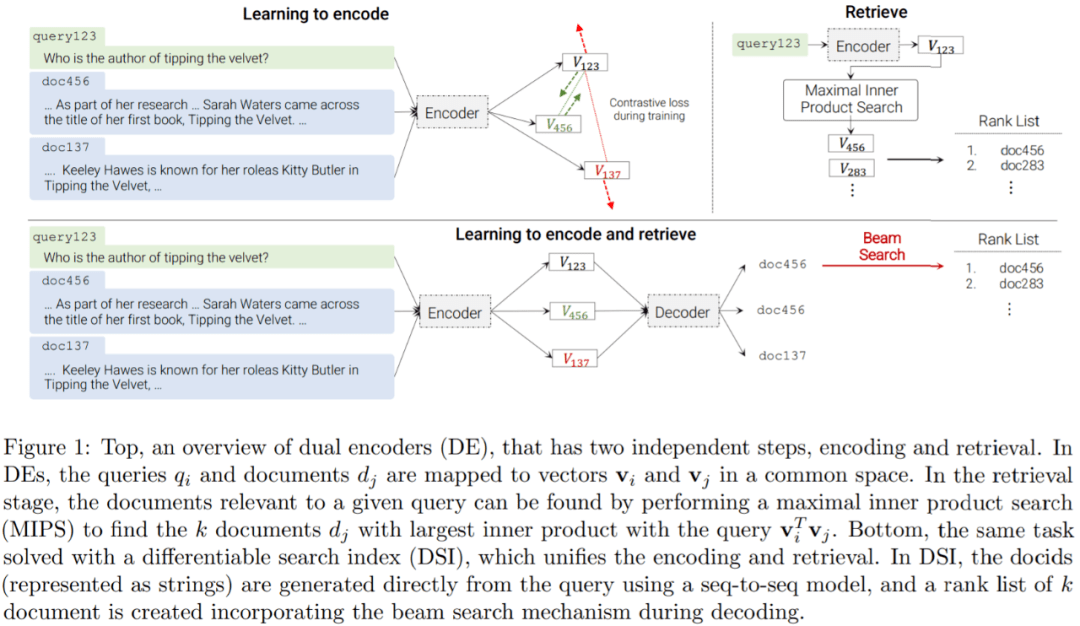
文章图片
双编码器 (DE) 的概述 , 它有两个独立的步骤 , 编码和检索 。
索引策略
Inputs2Target:研究者将其构建为 doc_tokens → docid 的 seq2seq 任务 , 此方式能够以直接输入到目标的方式将 docid 绑定到文档 token 。
Targets2Inputs:从标识符生成文档 token , 即 docid → doc token 。 直观来讲 , 这相当于训练一个以 docid 为条件的自回归语言模型 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。