贝叶斯方法拥有一群狂热的从业者 , 他们宣扬它优于更流行的经典统计方法 。 在某些情况下 , 贝叶斯模型特别有用:仅点估计是不够的 , 不确定性的估计很重要;当数据有限或高度缺失时;并且当您了解要在模型中明确包含的数据生成过程时 。 贝叶斯模型的实用性受到以下事实的限制:对于许多问题 , 点估计已经足够好 , 人们只是默认使用非贝叶斯方法 。 更重要的是 , 有一些方法可以量化传统 ML 的不确定性(它们只是很少使用) 。 通常 , 将 ML 算法简单地应用于数据会更容易 , 而不必考虑数据生成机制和先验 。 贝叶斯模型在计算上也很昂贵 , 并且如果理论进步产生更好的采样和近似方法 , 那么它会具有更高的实用性 。
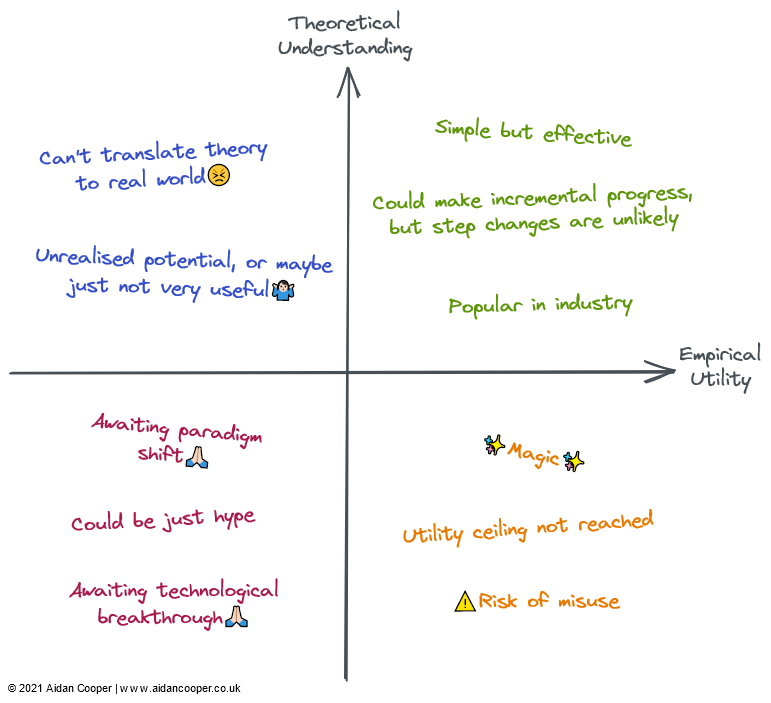
右下象限:低理解 , 高效用
与大多数领域的进展相反 , 深度学习取得了一些惊人的成功 , 尽管理论方面被证明从根本上难以取得进展 。 深度学习体现了一种鲜为人知的方法的许多特征:模型不稳定、难以可靠地构建、基于弱启发式进行配置以及产生不可预测的结果 。 诸如随机种子 “调整” 之类的可疑做法非常普遍 , 而且工作模型的机制也很难解释 。 然而 , 深度学习继续推进并在计算机视觉和自然语言处理等领域达到超人的性能水平 , 开辟了一个充满其他难以理解的任务的世界 , 如自动驾驶 。
假设 , 通用 AI 将占据右下角 , 因为根据定义 , 超级智能超出了人类的理解范围 , 可以用于解决任何问题 。 目前 , 它仅作为思想实验包含在内 。
文章图片
每个象限的定性描述 。 字段可以通过其对应区域中的部分或全部描述来描述
左上象限:高理解 , 低效用
大多数形式的因果推理不是机器学习 , 但有时是 , 并且总是对预测模型感兴趣 。 因果关系可以分为随机对照试验 (RCT) 与更复杂的因果推理方法 , 后者试图从观察数据中测量因果关系 。 RCT 在理论上很简单并给出严格的结果 , 但在现实世界中进行通常既昂贵又不切实际——如果不是不可能的话——因此效用有限 。 因果推理方法本质上是模仿 RCT , 而无需做任何事情 , 这使得它们的执行难度大大降低 , 但有许多限制和陷阱可能使结果无效 。 总体而言 , 因果关系仍然是一个令人沮丧的追求 , 其中当前的方法通常不能满足我们想要提出的问题 , 除非这些问题可以通过随机对照试验进行探索 , 或者它们恰好适合某些框架(例如 , 作为 “自然实验” 的偶然结果) 。
联邦学习(FL)是一个很酷的概念 , 却很少受到关注 - 可能是因为它最引人注目的应用程序需要分发到大量智能手机设备 , 因此 FL 只有两个参与者才能真正研究:Apple 和谷歌 。 FL 存在其他用例 , 例如汇集专有数据集 , 但协调这些举措存在政治和后勤挑战 , 限制了它们在实践中的效用 。 尽管如此 , 对于听起来像是一个奇特的概念(大致概括为:“将模型引入数据 , 而不是将数据引入模型”) , FL 是有效的 , 并且在键盘文本预测和个性化新闻推荐等领域有切实的成功案例. FL 背后的基本理论和技术似乎足以让 FL 得到更广泛的应用 。
强化学习(RL)在国际象棋、围棋、扑克和 DotA 等游戏中达到了前所未有的能力水平 。 但在视频游戏和模拟环境之外 , 强化学习还没有令人信服地转化为现实世界的应用程序 。 机器人技术本应成为 RL 的下一个前沿领域 , 但这并没有实现——现实似乎比高度受限的玩具环境更具挑战性 。 也就是说 , 到目前为止 , RL 的成就是鼓舞人心的 , 真正喜欢国际象棋的人可能会认为它的效用应该更高 。 我希望看到 RL 在将其置于矩阵右侧之前实现其一些潜在的实际应用 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。