知其然 , 知其所以然 。
>>>>
机器学习领域近年的发展非常迅速 , 然而我们对机器学习理论的理解还很有限 , 有些模型的实验效果甚至超出了我们对基础理论的理解 。
目前 , 领域内越来越多的研究者开始重视和反思这个问题 。 近日 , 一位名为 Aidan Cooper 的数据科学家撰写了一篇博客 , 梳理了模型的实验结果和基础理论之间的关系 。 以下是博客原文:
机器学习领域中 , 有些模型非常有效 , 但我们并不能完全确定其原因 。 相反 , 一些相对容易理解的研究领域则在实践中适用性有限 。 本文基于机器学习的效用和理论理解 , 探讨各个子领域的进展 。
这里的「实验效用」是一种综合考量 , 它考虑了一种方法的适用性广度、实施的难易程度 , 以及最重要的因素 , 即现实世界中的有用程度 。 有些方法不仅实用性高 , 适用范围也很广;而有些方法虽然很强大 , 但仅限于特定的领域 。 可靠、可预测且没有重大缺陷的方法则被认为具有更高的效用 。
所谓理论理解 , 就是要考虑模型方法的可解释性 , 即输入与输出之间是什么关系 , 怎样才能获得预期的结果 , 这种方法的内部机制是什么 , 并考量方法涉及文献的深度和完整性 。
理论理解程度低的方法在实现时通常会采用启发式方法或大量试错法;理论理解程度高的方法往往具有公式化的实现 , 具有强大的理论基础和可预测的结果 。 较简单的方法(例如线性回归)具有较低的理论上限 , 而更复杂的方法(例如深度学习)具有更高的理论上限 。 当谈到一个领域内文献的深度和完整性时 , 则根据该领域假设的理论上限来评估该领域 , 这在一定程度上依赖于直觉 。
我们可以将效用矩阵构造为四个象限 , 坐标轴的交点代表一个假设的参考领域 , 具有平均理解和平均效用 。 这种方法使得我们能够根据各领域所在的象限以定性的方式解释它们 , 如下图所示 , 给定象限中的领域可能具有部分或全部该象限对应的特征 。
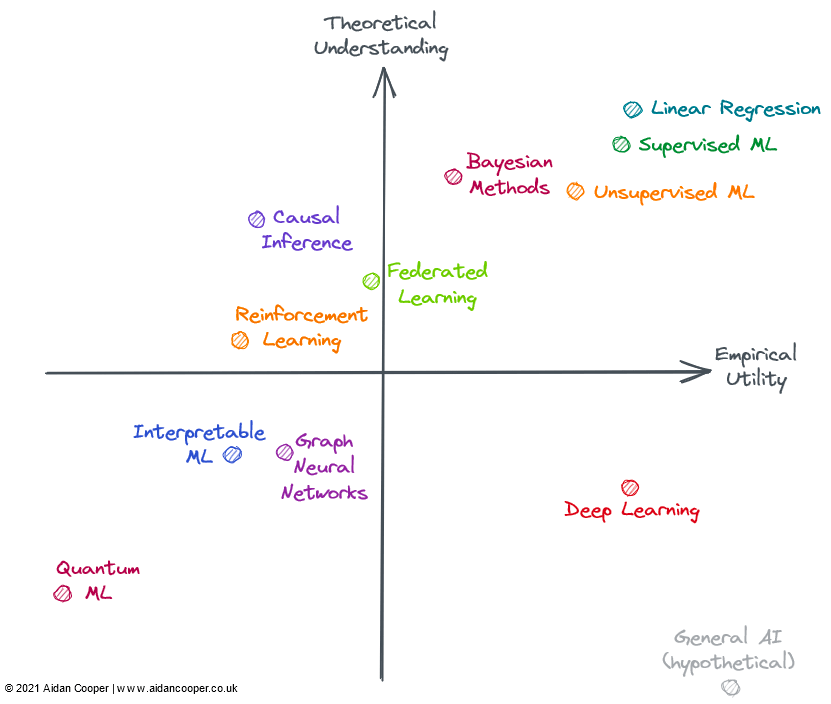
文章图片
一般来说 , 我们期望效用和理解是松散相关的 , 使得理论理解程度高的方法比理解程度低的更有用 。 这意味着大多数领域应位于左下象限或右上象限 。 远离左下 - 右上对角线的领域代表着例外情况 。 通常 , 实际效用应落后于理论 , 因为将新生的研究理论转化为实际应用需要时间 。 因此 , 该对角线应该位于原点上方 , 而不是直接穿过它 。
2022 年的机器学习领域
并非上图所有领域都完全包含在机器学习 (ML) 中 , 但它们都可以应用于 ML 的语境中或与之密切相关 。 许多被评估的领域是重叠的 , 并且无法清晰地描述:强化学习、联邦学习和图 ML 的高级方法通常基于深度学习 。 因此 , 我考虑了它们理论与实际效用的非深度学习方面 。
右上象限:高理解、高效用
线性回归是一种简单、易于理解且高效的方法 。 虽然经常被低估和忽视 。, 但它的使用广度和透彻的理论基础让其处于图中右上角的位置 。
传统的机器学习已经发展为一个高度理论理解和实用的领域 。 复杂的 ML 算法 , 例如梯度提升决策树(GBDT) , 已被证明在一些复杂的预测任务中通常优于线性回归 。 大数据问题无疑就是这种情况 。 可以说 , 对过参数化模型的理论理解仍然存在漏洞 , 但实现机器学习是一个精细的方法论过程 , 只要做得好 , 模型在行业内也能可靠地运行 。
然而 , 额外的复杂性和灵活性确实会导致出现一些错误 , 这就是为什么我将机器学习放在线性回归的左侧 。 一般来说 , 有监督的 机器学习比它的无监督 * 对应物更精细 , 更有影响力 , 但两种方法都有效地解决了不同的问题空间 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。