文章图片
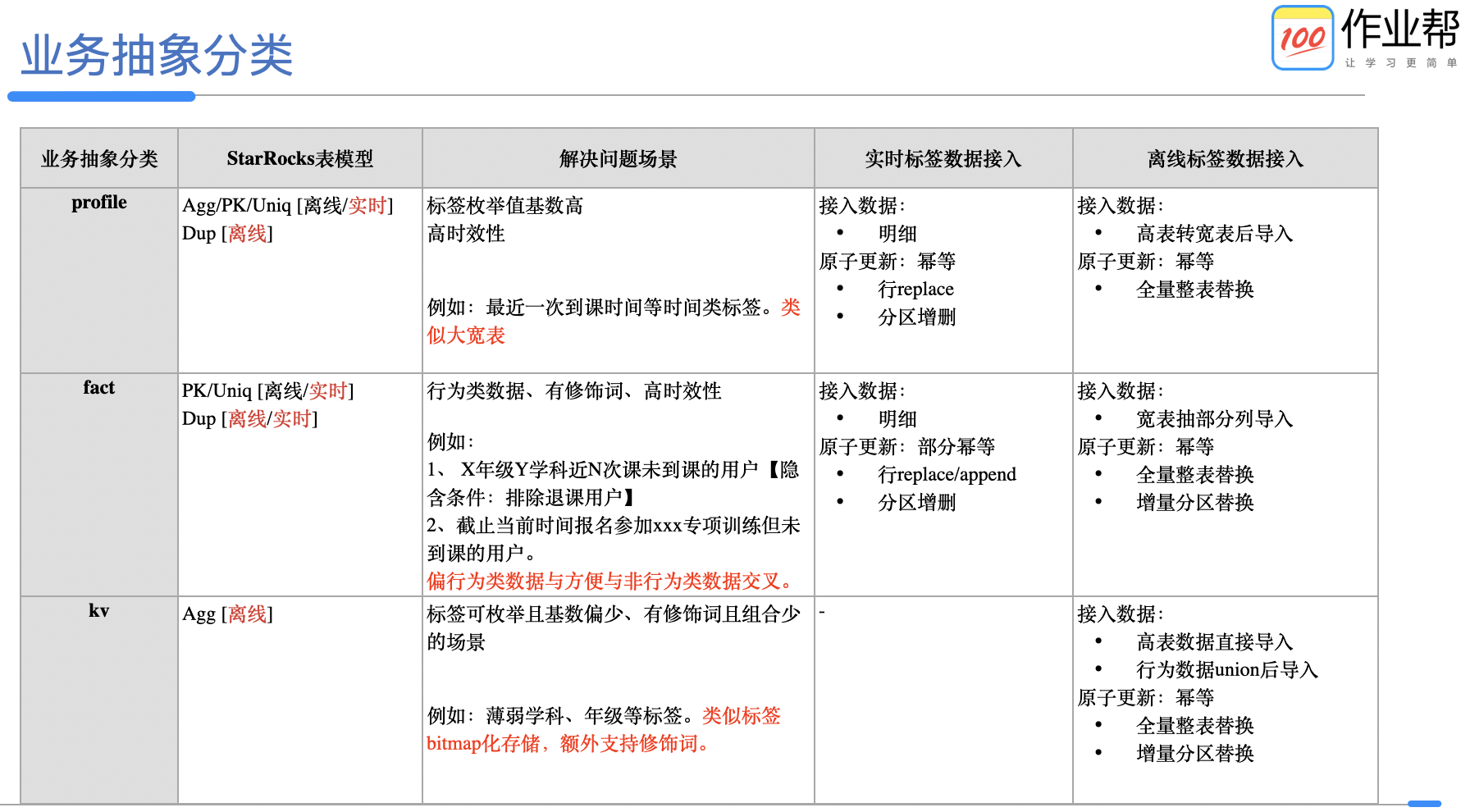
2、画像服务
画像服务核心能力有两个 。 第一个人群圈选能力 , 特点为内部系统 qps 不高 , 秒级返回 。 第二个单用户 id 规则判定能力 , 特点为 qps 很高 , 10 毫秒级返回 。 第二个不在本系统设计范围内 , 只说人群圈选部分 , 大体执行过程如下:
- 请求 DSL 参数解析及校验:将人群圈选 DSL 按标签拆分为多个独立的表达式和组合关系 , 然后根据标签配置信息补充隐含条件 , 同时校验每个表达式的合理性 。
- 查询逻辑优化:标签同表存储时合并表达式 , 减少单表达式数据返回量加速查询速度 。
- 表达式转 SQL:根据抽象类型对应的查询模板 , 将优化合并后的表达式分别转化为多个子查询 , 然后结合组合关系形成整条 SQL。
- 执行 SQL 圈选人群 。

文章图片
性能测试
(1)Profile + Agg 测试
实时场景未采用 PK 主要因为不支持 REPLACE_IF_NOT_NULL 和局部列更新 , 标签间入库解耦需要此能力 。 性能测试如下:
测试所用集群:32C 96G 1TSSD * 5台 , 3个FE , 5个BE , 5个Broker 。1.19.5版本
表数据:2.58亿行 , 3个指标列 , 单副本约1.7G , AGGREGATE KEY(`guid`), DISTRIBUTED BY HASH(`guid`) , 数据分布均匀 。
1.profile_b5表 bucket 5 共5个tablet 每个tablet 365M
2.profile_b20表 bucket 20 共20个tablet 每个tablet 95M
3.profile_b5_p5kw表 bucket 5 共30个tablet 每个tablet 67M
1)profile_b5_p5kw表中adpos_id、unit_id加bitmap索引 。
2)profile_b5_p5kw表按PARTITION BY RANGE(`guid`) 每5kw一个分区 。
测试数据说明:
Fragment 1有5个instance , 下边均采用ip为211的instance相关数据 。
Fragment 0有1个instance , 直接引用结果 。
数据均为多次查询后取相对合理且耗时较少的profile信息
此测试前已有认知:
离线标签采用profile+dup模型测试bitmap_union(to_bitmap(guid))性能,单BE 1个instance 1500W/s , to_bitmap耗时是bitmap_union耗时的2倍左右 , 两个算子耗时主要由guid数量决定 。
bitmap_union算子耗时与单个tablet内guid集中度有关 , guid取值范围越集中性能越好 , 建表时采用Range guid分区 , 步调1000W , bucket为1 。
复制代码
文章图片
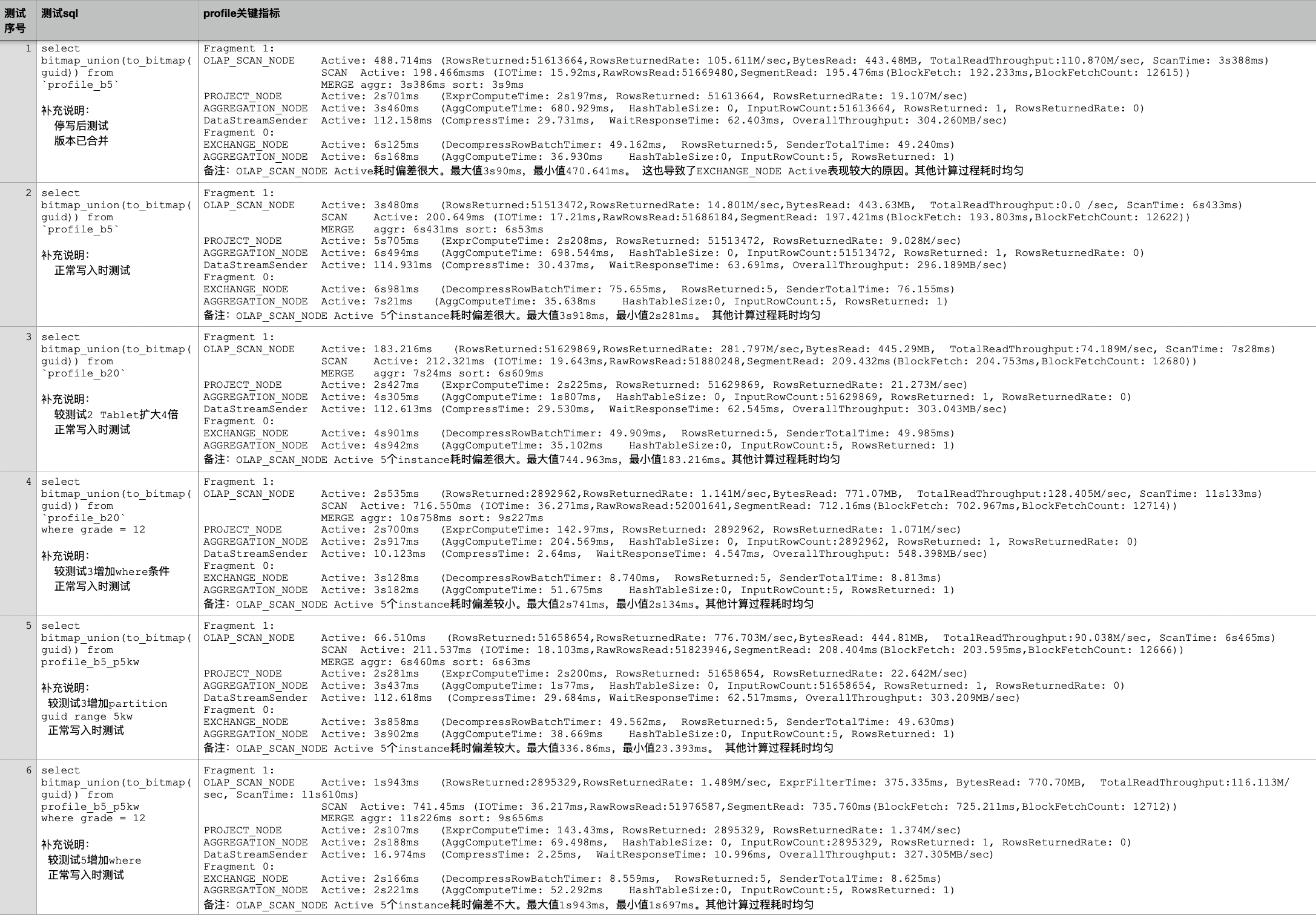
结论 1:测试 1/2 可知查询耗时点为 Fragment 1 阶段 Scan 操作含 Merge-on-Read 过程[OLAP_SCAN_NODE]、to_bitmap[PROJECT_NODE]、bitmap_union[AGGREGATION_NODE] , 而 Fragment 0 阶段因数据量很少所以耗时很少 。
结论 2:测试 2/3 对比考虑优化 Scan 耗时 。 增加 bucket 数量后 , Scan 耗时明显下降 。 tablet 数量增加引起 scan 并行度提高 。 doris_scanner_thread_pool_thread_num 默认 48 , tablet 数量调整前后为 5->25 均在此范围内 , 除 profile 信息外还可以通过 Manager 查看对应时间 Scan 相关监控 。 可根据集群负载情况适当增加线程数用于提高查询速度 。
结论 3:测试 3/5 对比考虑优化 bitmap_union 耗时并兼顾写负载平衡 。 采用 Range guid 分区 , 5kw 一个步调 , bucket 设为 5 。 每个 tablet 大约 1kw 数据量且差值低于 5kw , 避免部分 guid 活跃度高带来的单分区写热点问题 。 同为 5160W+数据量 bitmap_union 耗时减少约 700ms 。
结论 4:测试 3/4 对比考虑加上 where 条件后的查询耗时表现 , 因返回数据量降低一个数量级 bitmap_union(to_bitmap(guid))耗时明显减少 , 性能瓶颈主要表现在 Scan 阶段 。 因增加 where 条件后多扫描了 grade 列 , 增加耗时部分主要消耗在此列的数据扫描和 merge 过程 , 暂无较好优化方式 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。