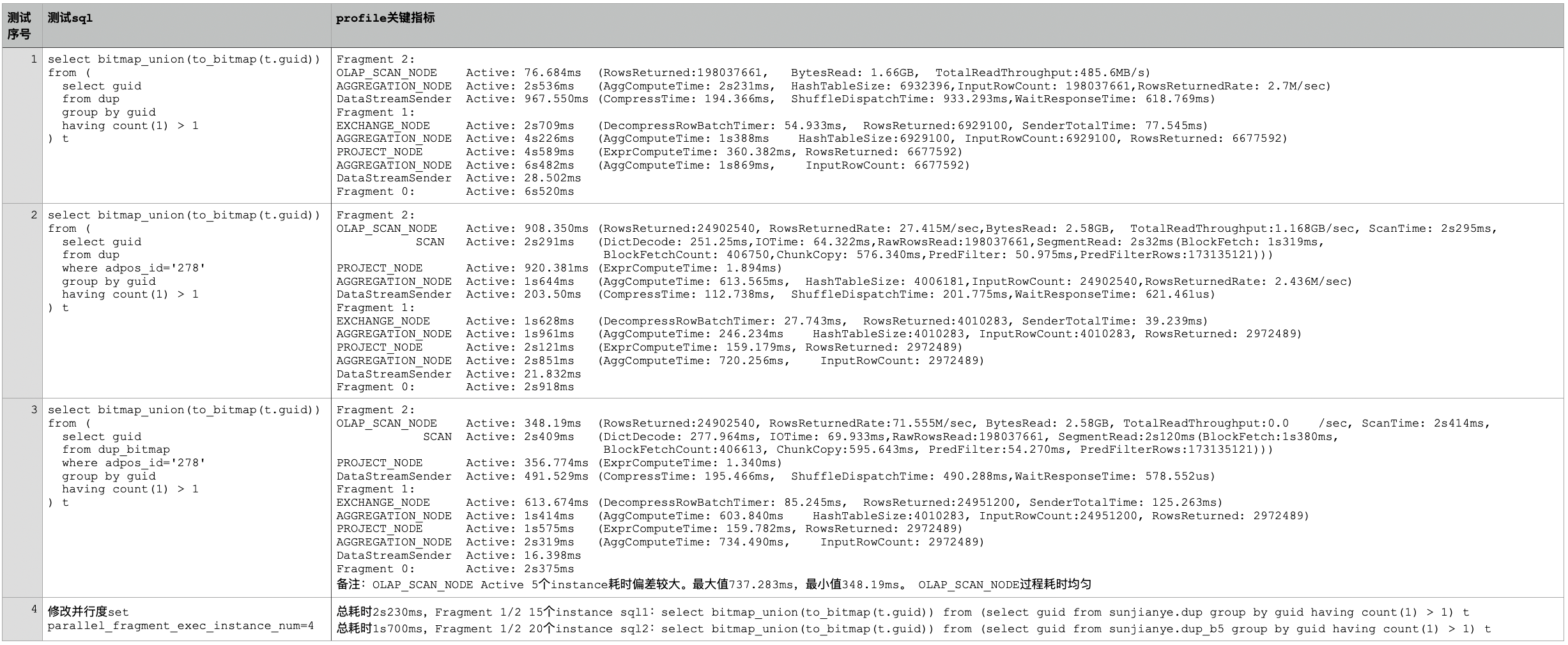
(2)Fact + Dup 测试
实时场景 Fact + Agg/Uniq 和 Profile + Agg 情况差不多 , 相关优化可结合上边结论 。 针对离线场景 Fact + Dup 模型测试数据如下:
测试所用集群:32C 96G 1TSSD * 5台 , 3个FE , 5个BE , 5个Broker 。 1.19.5版本
表数据:按日期天级别分区、3个分区有数据 , 每个分区3.4亿 , DUPLICATE KEY(`guid`), DISTRIBUTED BY HASH(`guid`) , 其他字段见上边建表sql 。 测试过程无数据写入 。
dup表: bucket 5 。 共15个tablet , 每个tablet 450M , 单副本数据分布均匀 , 总大小6G左右
dup_b5表: bucket 20 共60个tablet , 每个tablet 110M , 单副本数据分布均匀 , 总大小6G左右
dup_bitmap表:bucket 5 。 共15个tablet , 每个tablet 670M , 单副本数据分布均匀 , 总大小9G左右 , adpos_id、unit_id加bitmap索引
测试数据说明:
Fragment 2/1有5个instance , 下边均采用ip为211的instance相关数据 。
Fragment 0有1个instance , 直接引用结果 。
数据均为多次查询后取相对合理且耗时较少的profile信息 。
复制代码
文章图片
结论 1:测试 1/2 可知查询耗时点为:
- Scan 过程[OLAP_SCAN_NODE] 。
- 两阶段 group by guid [Fragment2 AGGREGATION_NODE 和 Fragment1 的第一个 AGGREGATION_NODE] 。 group by 耗时主要为 HashTable 构建时间含 count(1)结果更新 , 本质取决于 scan 返回数据条数以及 HashTableSize 大小。
- to_bitmap[Fragment1 的第一个 PROJECT_NODE] 和 bitmap_union[Fragment1 的第二个 AGGREGATION_NODE] 算子 , 总体优化思路见上边测试结论 。 结论 2:测试 2/3 分析无论是否增加 bitmap 索引 , 查询都有一定程度的下推到存储层【simd filter】 , 增加 bitmap 索引但未应用 , 因区分度太低而不走 bitmap 索引【过滤条件枚举值数量/总数据条数 < 1/1000, 可通过 bitmap_max_filter_ratio 参数调节】 , 但执行计划发生变化 bitmap 表少了一次 group by agg 操作 , 就总体查询耗时变化不大 。 同时增加 bitmap 索引后存储成本增加 , 所以不增加 bitmap 索引 。
结论 4:测试 4 分析 fragment 1/2 实际并行度计算公式如下 。 适当增加 tablet 个数【partition、bucket】和 exec instance num 可以加快查询速度 。 此加速过程会作用于结论 1 中全部耗时点 。
- 当 tablet 个数【不含副本】小于 parallel_fragment_exec_instance_num * BE 个数时取 tablet 个数
- 当 tablet 个数【不含副本】大于 parallel_fragment_exec_instance_num * BE 个数时取 exec_instance_num * BE 个数
此部分主要用于存储标签枚举值较少的用户集合 , 所以数据量并不多 , 基本 1s 内返回 。
根据查询模板猜测当数据量较大时可能的性能瓶颈点主要:
- Scan 过程[OLAP_SCAN_NODE]:bitmap 对象反序列化和 SegmentRead 过程 。可考虑用 enable_bitmap_union_disk_format_with_set 优化 。
- bitmap_union 算子 , 如果按照上边优化方案调整 bitmap 元素分布就需要在表中增加更多行的数据性能未必会好 。 需要测试看数据后选择平衡 。
遇到的坑 :
- 查询 bitmap_or(to_bitmap(字段 A) , to_bitmap(字段 B)) , 字段 A/B 有空值时计算错误 。 通过 ifnull(to_bitmap(字段名),bitmap_empty())解决 。
- Uniq 模型多副本排除外部干扰的情况下 , 5be 节点、无分区、bucket 为 5、副本数为 2 , 数据分布均匀、tablet 状态正常 。 查询时会出现 4 个 Be 节点工作 , 其中一个扫描 2 个 tablet , BE 接收的 task 分布不均匀的情况导致总体耗时变长 。 已反馈 StarRocks 同学 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。