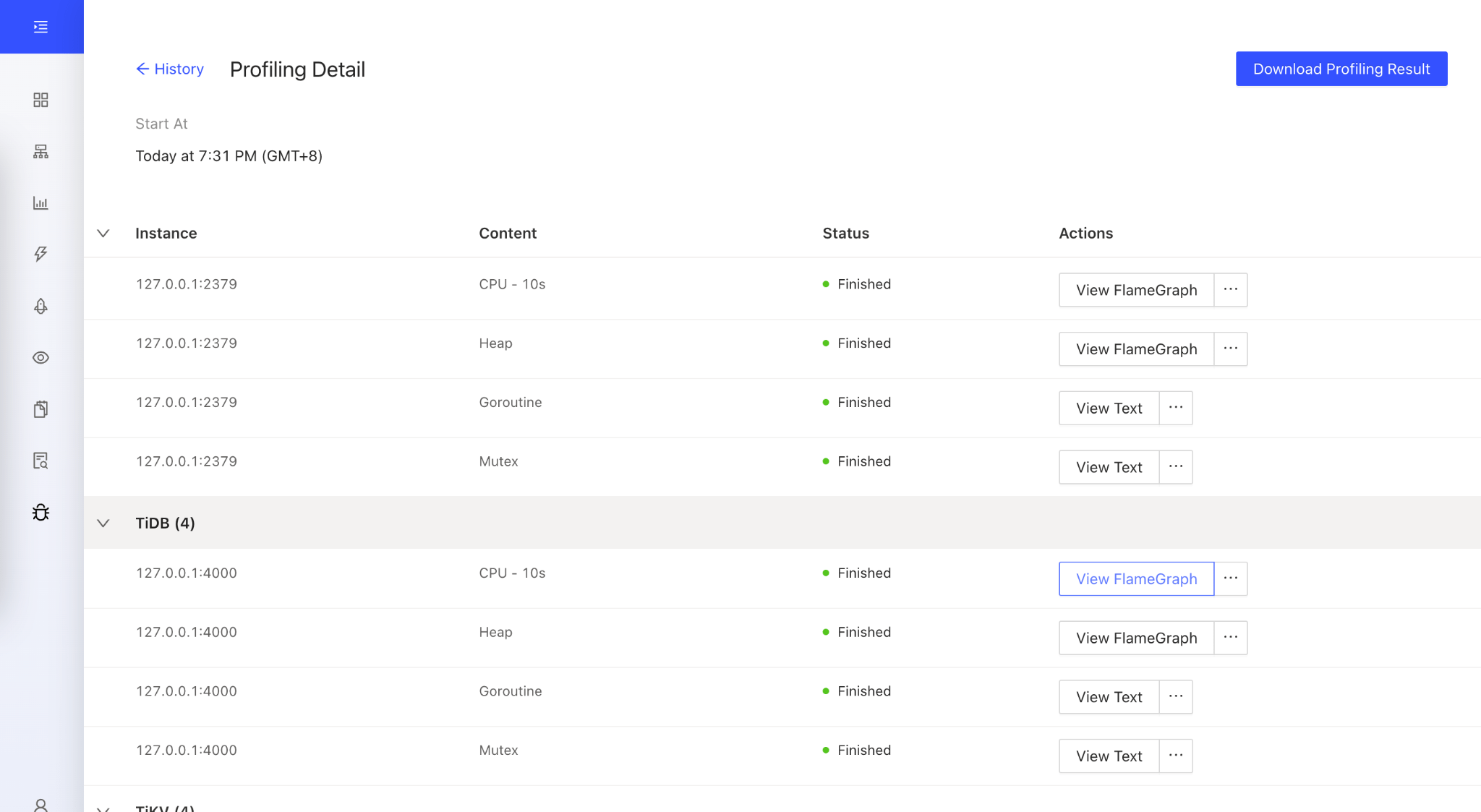
TiDB Dashboard 中 Profiling
我心目中对于一个基础软件产品是不是好 , 我有一个特别的标准:自带 Profiler 的 , 基本上都是良心产品 , 能够把 Profile 体验做 UX 优化的 , 更是良心中的良心 。 例如 Golang 的 pprof , 用过都说香 。 其实这个点说起来也不难做 , 但是关键时刻能救命 , 而且通常出事的时候也没法 Profile 了 , 这个时候如果系统告诉你 , 自己在故障的时候保存了一份当时的 profile 记录 , 这种雪中送炭似的帮助的体验是很好的 。
文章图片
文章图片
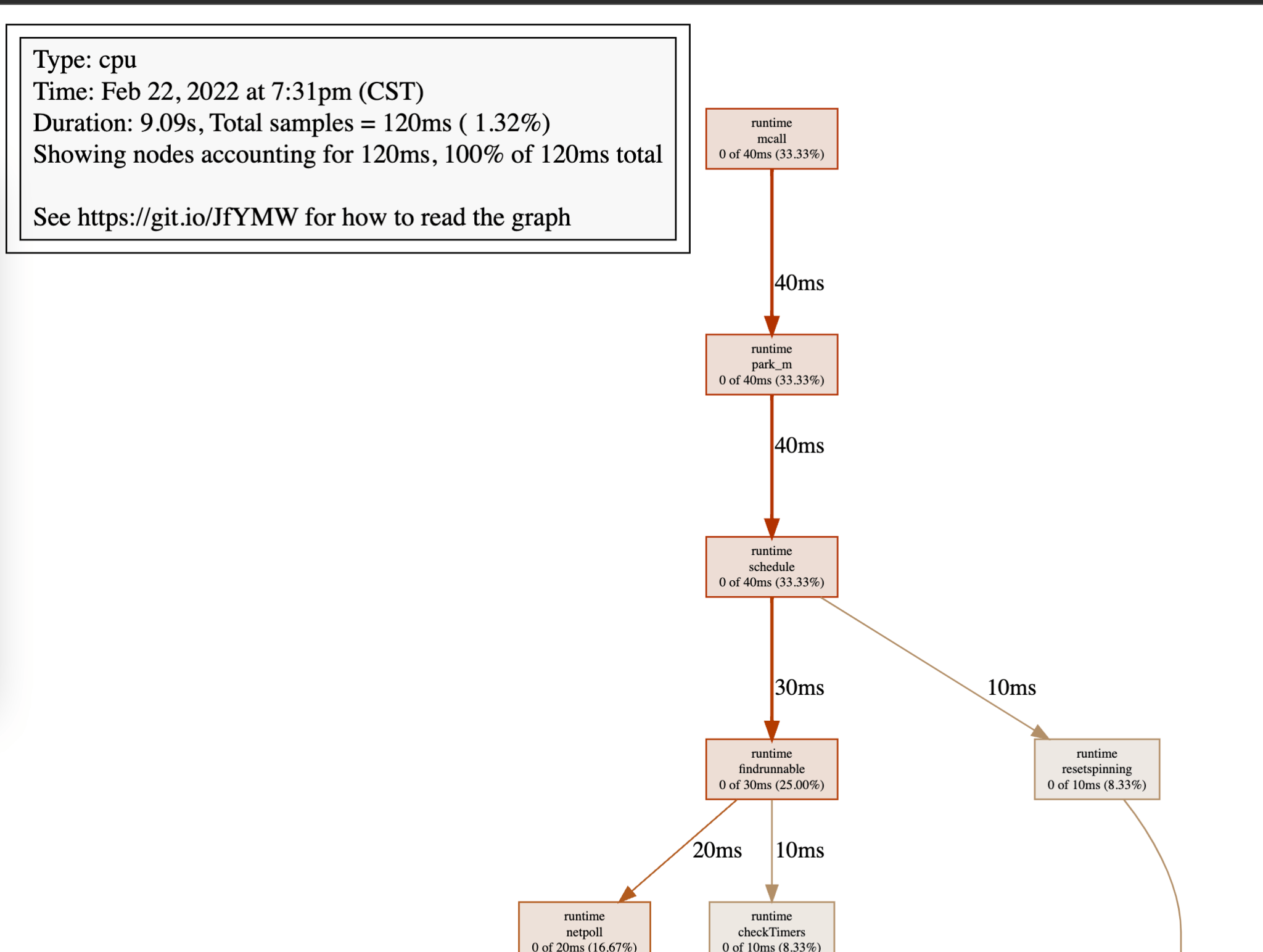
其实这个功能来自于几个我们实际处理过的 oncall case , 都是一些通过 metric 没法覆盖到的问题 , 有一大类故障 , 是遇到硬件瓶颈了 , 大概逃不过 CPU 和磁盘 , 磁盘瓶颈相对好查 , 大致看有没有大的 IO(Update / Delete / Insert)或者 RocksDB 本身的 Compaction 就好 , 但是 CPU 瓶颈的查找方式就模糊许多 , Profiler 几乎是唯一的方式:
- CPU 的关键路径上的 Call Stack 是什么样子
- 这些关键路径上的函数调用暗示了什么?
目前 TiDB 在 5.x 中提供了两种 Profile 方式:手动 Profile 和自动持续 Profile , 两种应用场景不同 , 手动的通常用于针对性的性能优化;自动持续 Profile 通常用于系统出现问题后的回溯 。
面临的挑战
快结尾了 , 说点挑战 。 PingCAP 是在 2015 年成立的 , 到现在已经马上就要 7 岁了 , 在这 7 年里 , 正好经历了一些很重要的行业变革:
- 数据库技术从分布式系统过渡到云原生;虽然很多人可能觉得这两个词并不是一个层面上的概念 , 因为云原生也是分布式系统实现的呀?但是我觉得云原生是一种设计系统的思考方式的根本改变 , 这点我在我其他很多文章里提过 , 就不赘述了 。
- 开源的数据库软件公司找到了可规模化商业化的模式:在云上的 Managed Service 。
- 全球的基础软件领域正在经历从‘能用’变成‘好用’的阶段
- 在技术上 , 需要完成从依赖计算机的操作系统和硬件变成依赖云服务 , 这一点对于技术的挑战是巨大的 , 例如:使用 EBS 的话 , 是否 Data Replication 还是必须的?使用 Serverless 的话 , 是否能够打破有限的计算资源的限制?如果这个问题再叠加上已有的系统可能有大量的现有用户会变得更加复杂 , 当然 , 云原生技术并不等于公有云 Only , 但如何设计出一条路径 , 慢慢的过渡到以云原生技术为基础的新架构上?这会是对于研发和产品团队一个巨大的挑战 。
- 第二个改变会是更大的挑战 , 因为商业模式在转变 , 在传统的开源数据库公司 , 主流的商业模式是以服务支持为主的人力生意 , 高级一点是类似 Oracle 这样的卖保险的生意 , 但是这些商业模式都没有办法很好的回答两个问题:
- 商业版和开源版的价值差异
- 如何规模化 , 已经靠人力是无法规模化的
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。