分别表示在尺度 m 下的生成器、合成图像和高斯噪声向量 。 符号↑代表上采样 。
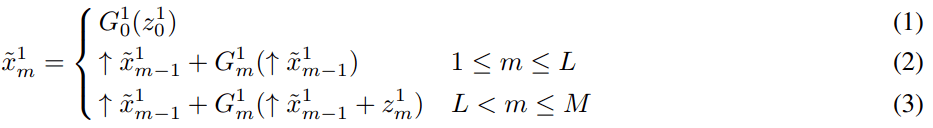
文章图片
首先 , 如等式 (1) 所示 , HP-VAE-GAN 从高斯噪声
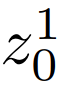
文章图片
生成初始图像 , 然后如等式 (2)(3) 所示 , 逐渐增加分辨率 。 在 1 ≤ m ≤ L 的早期阶段 , 为了多样性 , HP-VAE-GAN 应用 patch VAE [19] , 如方程式 (2) , 因为 GAN 模型的多样性由于模式崩溃问题而受到限制 。 然而 , 在 L < m ≤ M 的后期阶段 , 为了细节的保真 , 它应用了 patch GAN [22] , 如等式 (3) 。
in-memory、子区域级超分辨率
在第二步和第三步中 , OUR-GAN 专注于保真度 , 并通过添加精细细节来提高先前合成图像的分辨率 。 在第三步中 , OUR-GAN 应用子区域超分辨率以将图像分辨率提高到超出内存限制 。 这些步骤中最大的技术挑战是使用单个训练图像学习超分辨率模型 。 该研究通过预训练 ESRGAN(一种以良好的输出质量而闻名的超分辨率模型)来实现高保真度 , 然后使用单个训练图像对其进行微调 。 在之前的工作中 , 有超分辨率模型 , 例如 ZSSR 和 MZSR [21] , 可以从单个图像中学习 。 然而 , 在初步实验中 , 预训练 ESRGAN 表现出比零样本超分辨率模块更高的图像质量 。 该研究使用 DIV2K 和 Flickr2K 数据集来预训练 ESRGAN 。
在第二步中 , 研究者在先前合成的图像
文章图片
中加入随机噪声
文章图片
, 然后通过
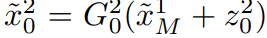
文章图片
中的超分辨率模型
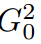
文章图片
提高分辨率 。 在第三步中 , 他们将图像划分为子区域 , 对每个子区域图像进行超分辨率处理 , 然后将缩放后的子区域图像拼接成一幅更高分辨率的图像 , 如图 5 所示 。 这样的分区超分辨率可以重复多次 , 以产生 4K 或更高分辨率的 UHR 图像 。
文章图片
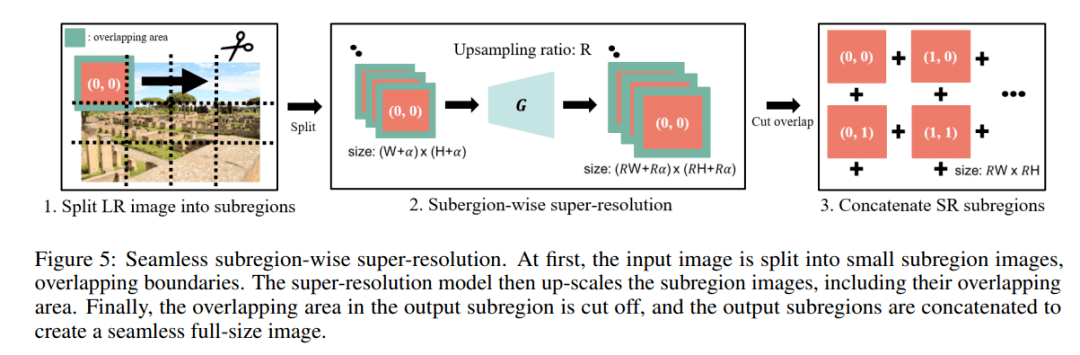
然而 , 如果没有精心设计 , 这种分区域的超分辨率会在边界处表现出不连续 。 在以前的工作中 , 有一些方法可以防止不连续性 。 以前的工作表明 , 不连续性的主要原因是输入特征图周围的零填充(zero-padding) , 并提出了一些补救措施 。 [28] 应用了重叠平铺(overlap-tile)策略 , 扩展输入子区域以阻止边界处零填充的影响 。 [12] 通过仔细设计具有交替卷积和转置卷积的网络来消除零填充 。
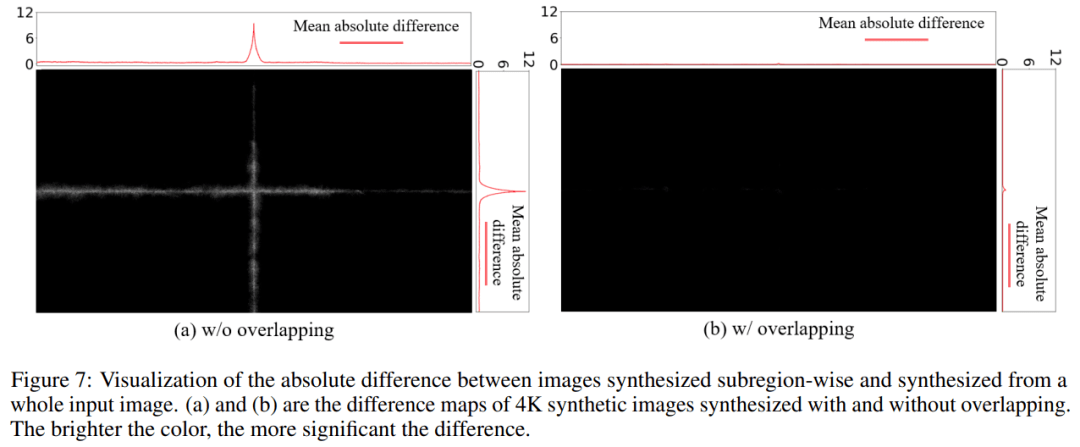
由于后者需要重新设计网络 , 因此研究者对前者进行了改进 。 受 Wenjie Luo 等人 (2016) 的启发 , 研究者将重叠大小设置为 ERF 的半径 , 如图 6 所示 , 它明显小于 TRF 。 图 7 中的实验结果表明 , 等于 ERF 半径的重叠足以防止不连续性 。 ERF 的渐近逼近是 O (√depth) ,而 TRF 的渐近逼近是 O (depth) , 这表明方法的好处是不可忽略的 。
文章图片
文章图片
研究者比较了没有重叠和 ERF 半径重叠的子区域超分辨率的结果 。 图 7 显示了子区域超分辨率输出图像与将图像整体放大的普通超分辨率输出图像之间的差异 。 图 7 (a) 表明 , 在没有重叠的情况下 , 子区域超分辨率在子区域边界处产生显着差异 。 然而 , 重叠的子区域减弱了这种差异 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。