可信联邦学习的特征
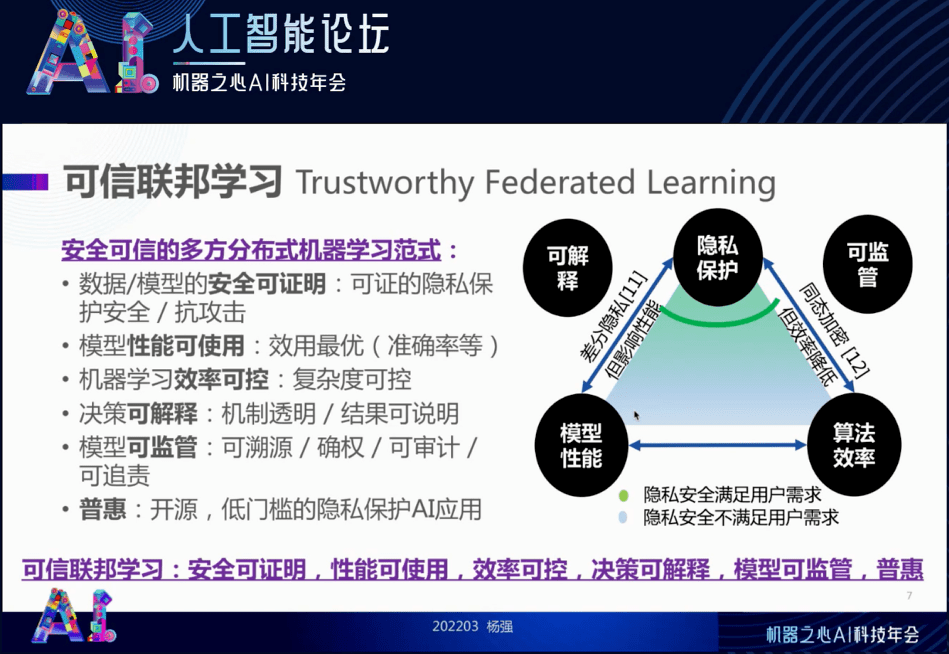
这就引出了我接下来要说的 “可信联邦学习” 。 我们刚才说的是安全、攻击和可能的威胁模式 , 但是不要忘记我们做所有这些事都是满足做到高效 。 一个叫做效用 , 如准确率、覆盖率等 。 还有一个是效率 , 即速度和计算复杂度 。 这两个我们都要一定保证 , 对于可信任的联邦学习而言 , 既要给出一个完整的安全证明 , 又要给出完整的性能和效率保证 。
同时 , 由于我们有多方用户 , 有工程师 , 有终端用户 , 有监管 , 有社会大众 。 因此 , 这种模型的决策一定要机制透明、结果可解释 , 模型也要可监管可管理 。 也就是说 , 关于模型到底是谁的 , 我们可以溯源和确权 。 这个数据是谁的 , 我们可以审计 。 数据出了问题到底是谁的责任 , 我们可以追责 。 这就叫可监管 。
另外 , 我们希望整个模型不是被少数垄断者所用 , 而希望大家都低成本地用起来这个技术 , 这就是 “普惠” 的概念 。 达到普惠的一种方式就是开源 , 以实现低门槛的隐私保护 AI 应用 。
总结一下 , 我们所说的可信联邦学习是指安全可证明、性能可使用、效率可控、决策可解释、模型可监管和普惠的 。 下图三角形的节点都是我们所说的特性 , 它们之间其实是平衡的关系 。 可以看到从上到下绿色越来越浅 , 就是从隐私保护和模型性能的要求出发 , 在这个过程中划分边界 。 针对某个系统 , 这个边界到底应该划在哪呢?这是我下面要解决的问题 , 也即可信联邦学习如何落地 。
文章图片
可信联邦学习的实现
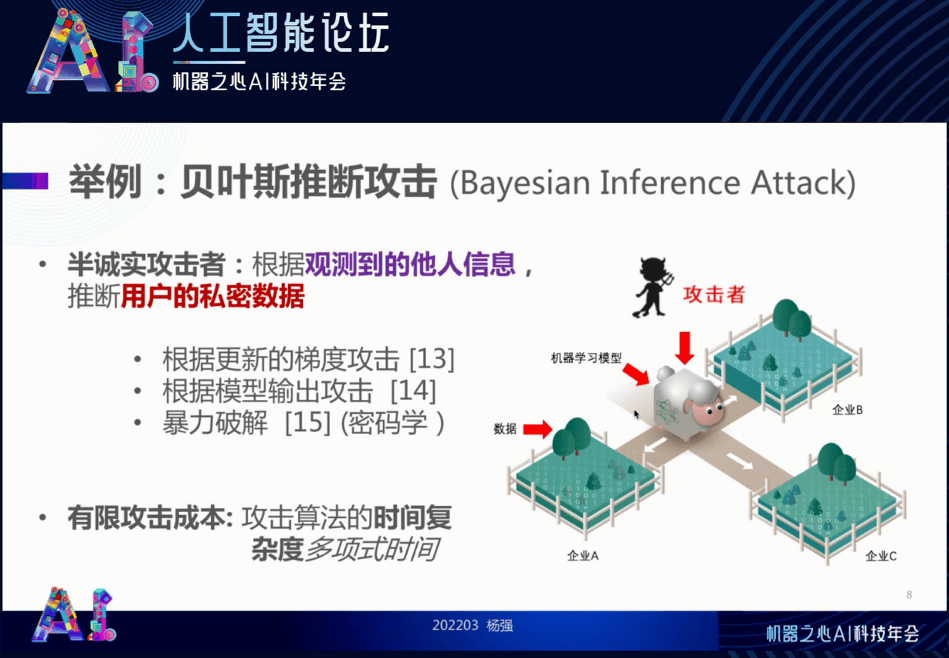
首先我们要清楚攻击的方式 。 在现实工作中 , 隐私有可能被泄露 , 有可能存在恶意的攻击者 , 也可能有好奇的人或参与者 , 如下图(右)所示 。 这个攻击者可以攻击我们的模型 , 对 “羊” 进行攻击 , 也可能是一个半诚实的攻击者 , 通过观测到了解羊和草料的信息 , 用以推断用户的隐私数据 。 我们称后面这种针对隐私的攻击为 “贝叶斯推断攻击”(Bayesian Inference Attack) 。 这种攻击覆盖很多的可能性 , 如通过梯度信息进行攻击的深度泄露型的攻击 , 就是观察合作者发过来的梯度并以此反猜用户的原始数据 。 此外还有通过输出的模型进行隐私攻击和以及暴力破解等(故意地猜密码) 。
我们的目的是要增加攻击者的成本 , 让攻击算法的复杂度足够的高 , 使之在有效的时间内就没有办法进行完整的对其有益的攻击 。 这是我们安全保障所希望达到的目标 。
文章图片
那么 , 贝叶斯推断攻击下 , 是不是把安全指标推到最高就可以了呢?不要忘记 , 我们还有一个要求 , 就是在保证安全的同时 , 我们系统的效能也好!如果一个系统极为安全 , 但准确率极低 , 那这个系统是不能落地的 。
所以 , 我们要在安全和效能之间划一个最佳的平衡点 , 最大化我们的效能和安全 , 使得这两者都可以得到兼顾 。
安全与效能的「无免费午餐」理论
有没有可能我们在隐私计算当中 , 将安全和效能同时都最大化呢?下面引入可信隐私计算里面一个最新的重要成果 , 叫做「No-free lunch(无免费午餐)定理」 , 这个定理告诉我们信息的相互泄露和模型效能是互相制约的 。 了解了这个制约规律有助于我们设计即实用又安全的隐私计算和联邦学习系统 。 以下是我们小组最近做的一项重要理论工作 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。