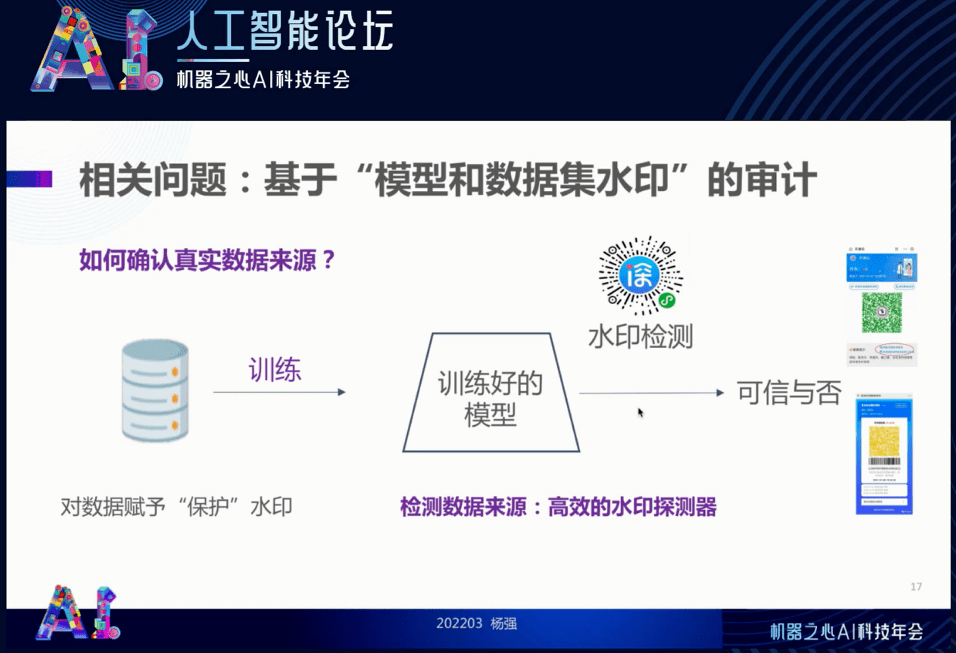
我们最近也做了一个工作 , 找到了最佳水印维度的方法 。 利用这一方法 , 我们训练一个模型(下图从左到右) , 然后用同样的方法确认这个模型的归属和来源 , 确定它是合法的 。 同时 , 我们可以提供一个水印检测 , 就像核酸检测一样 , 会产生像绿码一样的水印探测结果 。 同样的手段也可以用在对外来数据的确权管理上 。
文章图片
【FATE联邦学习开源社区技术指导委员会主席杨强:重视可信联邦学习】联邦学习的进展及取得的成就
最后简单回顾一下联邦学习的发展 , 它在 2016 至 2018 年期间逐步完善 , 集中在横向联邦、多参与方和终端 。 然后 , 我们在 2018 年提出了纵向联邦、联邦迁移学习 , 异构数据和模型之间的联邦学习 , 并在激励机制、自动化联邦学习等领域不断地推进 。 可以说 , 现在联邦学习不管在学术上还是在实践上都有了长足的进展 。
首先是标准 。 我们在去年 3 月份发布了联邦学习标准 , 之后又有多个国内和国际的标准发布 , 包括编写中的标准 。 这里特别提一下中国电信领衔制作的联邦学习安全标准 IEEE P2986 。
同时 , 我们现在逐步完善了全球首个隐私计算和联邦学习开源社区 —— FATE 。 目前 , 该社区有 3000 多个个人参与者(工程师与开发者) , 以及 800 多家企业机构 。 我担任指导委员会主席 , 并有幸邀请到清华大学唐杰教授任指导委员会名誉主席 。 我们有非常专业的治理架构、技术指导委员会和专业委员会等 , 并且有大量的主流参与者、贡献者以及社区主要贡献方 。 这也是我们可信联邦学习的 “普惠” 维度的一个具体体现 。
该平台作为一个基准服务了很多企业级联邦学习和工业级平台 , 并支持多个主流算法 。 在可信联邦学习这个维度上 , 我们希望利用 FATE 现有资源向前迅猛推进 , 带领整个全球的隐私计算向前发展 。 同时 , 我们也欢迎大家积极地参与进来 。

文章图片
我们在联邦学习领域取得的成就也是有目共睹的 , 在去年终于被纳入 Gartner 技术成熟度曲线 , 这是对我们的肯定 。 我们还有很多案例 , 比如利用可信联邦学习制作智能培训机器人和坐席助手机器人 , 真正实现语音对话以及图像功能 , 从而综合地对人产生协助 , 对业务做出贡献 。
同时 , “可解释性” 是可信联邦学习的一个重要部分 。 在这方面 , 我们正在撰写一本书并且马上就会出版 。 这本书叫做《可解释人工智能导论》 , 希望大家加以关注 。

文章图片
总的来说 , 可信联邦学习是联邦学习的又一个进步和一个新的发展阶段 。 应该说 , 可信联邦学习是对整个隐私计算的一个新观点 。 这个观点首先基于我们终于发现在整个隐私计算领域 , 效能和安全其实需要一个最优化平衡 。 在保证安全的前提下如何能够最大化效能 , 这个就是我们算法设计的核心 。 同时 , 我们要保证对威胁模型、保护模型、知识产权保护给出很好的定义 , 使得模型可解释 , 并且整体普惠 。 我们 FATE 开源社区在可信联邦学习上不断进取 。
要达到可信联邦学习的目标 , 我们需要大家的共同努力 , 一起向前发展 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。