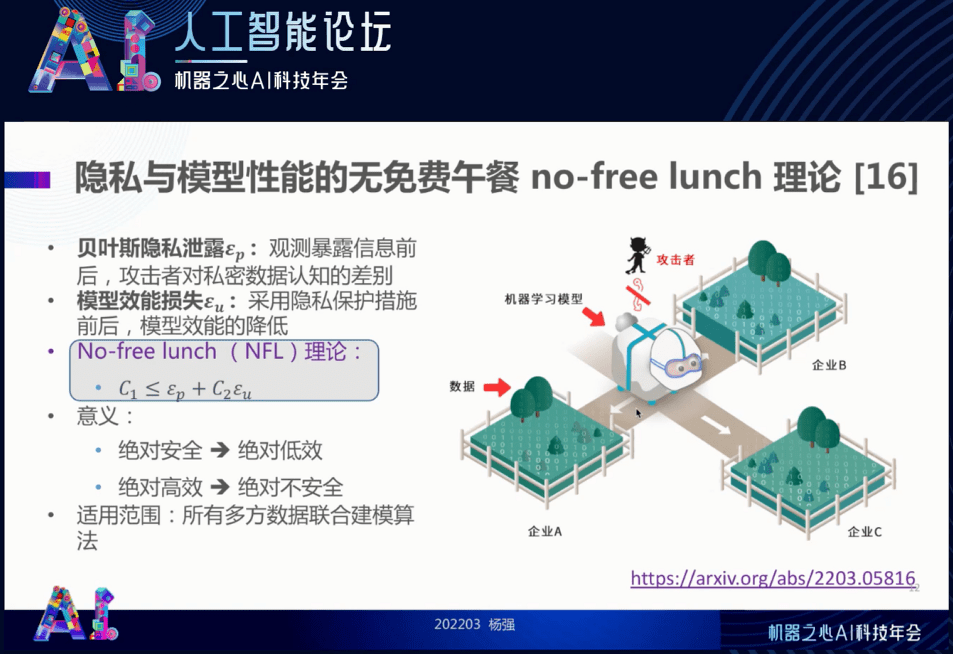
简单而言 , 对于满足贝叶斯隐私的多方计算系统而言(即覆盖整个隐私计算) , 只要有多方的系统 , 安全和效能分别作为一个因子 , 两者的和是有上界的 , 它是一个正常数 。 我们想要安全大 , 效能就不可能这么大;要效能最大 , 信息泄露方面就得做出让步 。 因此 , 两者之间如何达到最好的平衡 , 就是要看我们系统设计的聪明程度了 。 但是 , 并不像有些人所说的那样 , 为了追求极度的安全而不管效能;我们也不可能像有些学术文章中假设的那样效能是极大的 , 而不去管安全 。
这个定理的证明很费劲 , 我把文章的链接发给大家 , 而这里只做其结果的介绍 。 我们要假设有一种隐私泄露 —— 贝叶斯隐私泄露 , 通过观察某些参与者互相之间交换的信息来反猜这个数据 。 就像下图中这只不幸的小羊 , 效能的损失我们也给出一个量 , 如果羊保护的太严密 , 它没有足够的草吃 , 会长不大 。 这两个损失 , 就是效能和安全的损失 , 可以用错误率表达 , 它们值的和是大于等于一个常数的 。 效能和安全的最佳平衡也要受到这个公式的制约 。
文章图片
我特别要解释一下隐私计算的 “无免费午餐定理” 的意义 。
首先 , 它可以指导设计隐私保护多方计算的算法 , 满足用户「防止贝叶斯隐私泄露」的要求 , 同时使得性能损失最小 。 我们可以用来加噪声和差分隐私 , 传递部分参数数据 , 同态加密以保护这些参数数据或者部分参数数据 , 也可以用来保护安全多方计算的通用保护机制 。
总之 , 如下图(右)所示 , 我们可以在安全与效能之间找到一个最佳的平衡点 。 相关文章已放在了 arXiv , 感兴趣的读者可以下载阅读 。
论文地址:https://arxiv.org/abs/2203.05816
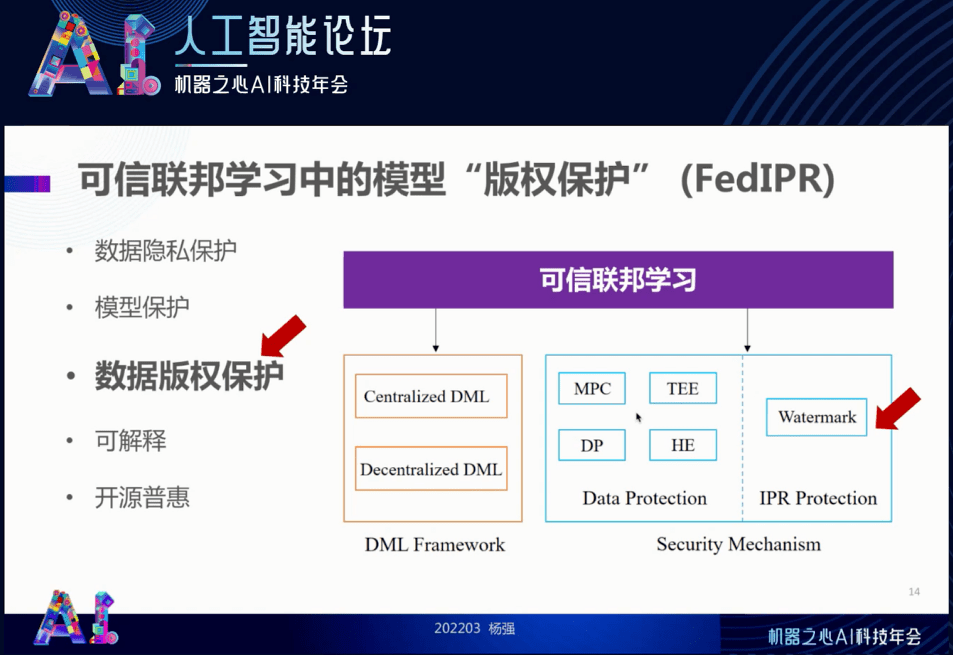
可信联邦学习的版权保护
前面讲了安全以及如何利用安全与效能的「无免费午餐」定理来设计一个最佳的算法 。 接下来我们考虑可信联邦学习中的版权保护问题 。 这里所说的版权不是指书和文章的版权 , 而是模型和数据的版权 。 我们将它叫做 FedIPR , “联邦知识产权” 。 我们怎么样解决版权的计算、保护和管理呢?我们可以通过在模型里面加水印(Watermark)的方法解决 。
文章图片
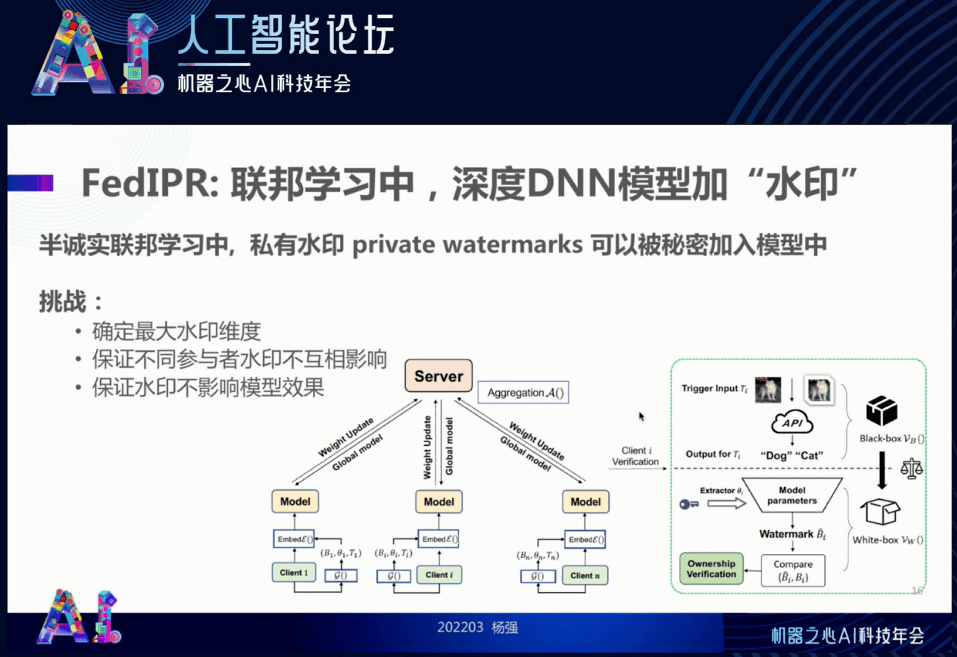
首先来看如果不保护模型可能发生什么呢?模型有可能被盗窃、被贩卖 , 就像很久以前的盗版光碟一样 。 此外 , 由于联邦学习是多方参与的 , 也许有人会滥竽充数 , 也就是他其实没有贡献数据和模型 , 但却对一个更新后的模型加以使用 。 这种就叫滥竽充数 。 还有一种是剽窃 , 比如剽窃你的数据或参数来学习你花了很大精力才得到的结果 。
我们假设自己是在这种服务器方传递的过程中需要保护可信参与方里面的模型 , 该如何去做呢?水印的设计取决于一个概念:私有水印 。 每一个参与方都可以秘密地把自己特有的私有水印加入模型里面 , 所以在与服务器的交换中这个水印是被烙在通用模型里面的 。 要做到这一点 , 我们的水印等于是一个 “嵌入” (Embedding) 。 它的维度是越大越好 , 这样才能保证容量足够得大 , 参与方足够多 , 不同参与方的水印互相不影响 , 也不会影响模型的效果 。 但一个嵌入的维度也是有代价的 , 因此也要找一个最优嵌入维度 。
文章图片
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。