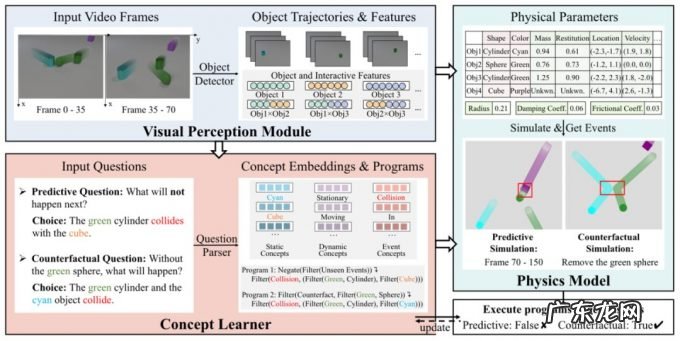
然而上述框架仍然存在一个难点, 现实世界中往往没有对物体的属性标注, 在这种情况下, 难以通过一个感知模块得到物体的相关属性(如颜色, 形状), 而没有这些先验信息就无法进行可微物理模拟, 更无法学到一个准确的物理模型 。 因此, 作者提出 VRDP 框架, 将视觉感知模块、概念学习器和物理模型结合, 使用三个无缝衔接的模块来解决上述问题 。 其中, 视觉感知模块用于对每帧图片进行分割, 得到每个物体和对应的轨迹;概念学习器负责从物体的轨迹信息和问题对中学习物体的属性;在物体的轨迹和属性都得到后, 通过可微物理模拟学到较为准确的物理模型;基于物理模型完成长时和反直觉的推理 。 整体框架如下:
文章插图
图 4. VRDP 框架 。 由三部分组成:视觉感知模块、概念学习器和可微物理模型
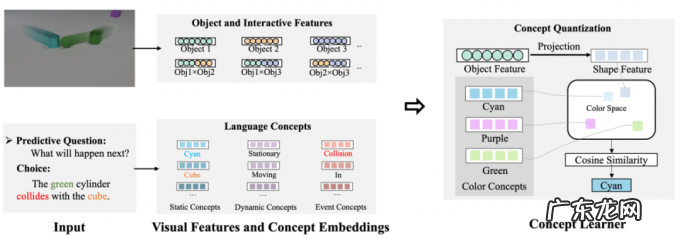
具体来说, 框架中的物理引擎为一个基于动量和动能守恒的碰撞模型, 它从单个视频轨迹中估计物体的实时速度和加速度, 并以此估计场景的摩擦力等参数 。 此外, 它通过碰撞事件来估计碰撞物体的相对质量和弹性系数, 一旦这些参数学习完成, 它便可以自由地进行各种模拟和推理 。 本文的概念学习器为问题中的每个概念词分配一个编码(embedding), 并从视频轨迹中学习物体感知的特征, 通过讲视觉特征和语义编码投影到同一空间下并检索来得到每个物体对应的属性, 参考 NS-CL [1] 。 如下图所示 。
文章插图
图 5. 概念学习器
本文的神经符号执行器利用了 NS-DR [2] 和 DCL [4] 中的方案, 通过预测出的物体轨迹和碰撞事件进行显式的符号推理, 如 filter(Green) 代表得到所有的绿色物体, filter(Collision, filter(Green), filter(Cube)) 则代表找出绿色物体和方块的碰撞事件 。 通过显式的物理模型以及神经符号执行器, 本文框架的每一步都是可解释且完全透明的, 整个推理过程和人类的逐步推理类似 。
Demo 展示

文章插图
图 6. 物理模拟示例, 左侧为原视频, 右侧为模拟结果

文章插图
图 7. 预测问题推理示例

文章插图
图 8. 反事实问题推理示例
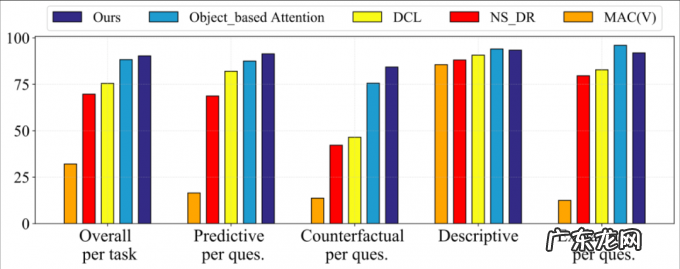
实验部分本文提出的 VRDP 框架具有优越的性能, 在全部 CLEVRER 数据集上测试, 它在更加困难的 Predictive 和 Counterfactual 两类问题上都取得了最高的性能, 在 Descriptive 和 Explanatory 问题上也得到了有竞争力的结果, 如下表所示 。
文章插图
图 9. 实验结果(全部数据)
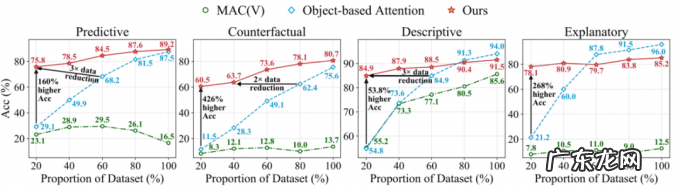
此外, 它具有极高的数据利用效率, 仅使用 20% 的数据就可以得到相当不错的结果, 远超现有的其他方案, 如下图所示 。
文章插图
图 10. 数据效率评估(部分数据)
作者还证明了, 通过使用可微物理模型, VRDP 可以轻易扩展到数据集中不存在的新的概念中, 如概念 “更重”, VRDP 成功进行物理模拟并准确预测了当蓝色圆柱更重时的情况, 这是更加复杂的反事实情形 。

文章插图
- 得物垂涎“范冰冰”,小红书失去“杨超越”
- 下一任「影史第一」拿什么超越《长津湖》?
- 骁龙8 Gen 1跑分曝光,超越天玑9000
- 海马云战略副总裁许琳:元宇宙所要求的高精度,沉浸感和超低延时需要全新的云计算基础设施| 2021WISE元宇宙·机器人峰会
- 杨超越投资成立文化传媒公司,注册资本900万
- 36氪首发 | 「方位角」完成近亿元天使轮融资,打造室内外全域高精度定位导航授时系统
- 凶猛!搭载最新AMD显卡的黑苹果来了:跑分超越老款iMac
- 平台人脸识别未成年人?何延哲:考虑降低精度仅识别年龄特征
- 无上超越魂 无上超越
- 乔丹的经典语录有哪些呢 为什么乔丹被认为无法超越
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。