三、算法迭代流程
在线上数据中,正负样本的比例非常不均衡(远低于千分之一),大部分都是各种各样的正常图片,只有少量的恶心图 。这意味着,即使模型在验证集上能达到99%的准确率,剩下的1%的错误也会在线上被无限放大,而且线上还有很多训练集里没出现过的负样本 。
在模型版本快速的更替中,我们采取了active learning,噪声样本识别,OHEM+级联的迭代流程,如下图所示 。
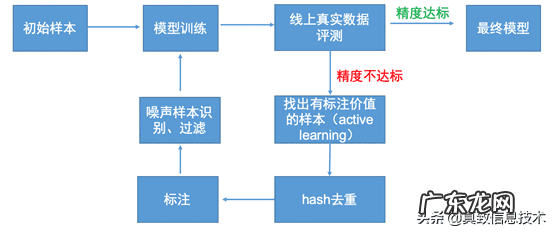
文章插图
1、active learning
在每次的版本迭代过程中,模型都会召回一批数据 。在一开始数据量比较少的情况下,可以全部标注然后进行训练 。但是当数据变多了以后,一方面标注成本是非常巨大的,而另一方面根据curriculum learning的思想,应该让模型的学习由易到难,先学习简单的样本,然后逐渐学习更难的样本,提高难例样本在训练集的权重,这样能够加快模型的训练,找到更好的局部最优 。因此如果每次都将所有的召回样本全部标注投入训练,结果是吃力又不太讨好的 。在此我们借鉴active learning的思想,去找出有标注价值的难例样本 。样本选择策略有两方面:
(1)在每次召回来的样本中,选择置信度在
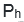
文章插图
以上的和在
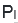
文章插图
以下的样本进行标注,挑选出前者中的负样本和后者中的正样本;
(2)在训练时引入损失预测模块,训练的时候预测各个样本的相对损失大小 。通过该模块对召回来的样本进行loss预测,并取出排名靠前的样本进行标注 。
上面两个策略都是挑选出难例样本进行标注 。选择第一个策略是因为,一般情况下,我们希望模型对正样本预测的置信度越高越好,希望模型对负样本的置信度越低越好,而置信度在
文章插图
以上的负样本和
文章插图
以下的正样本对于模型来说都是难例样本 。实际中选择的阈值可以根据情况来进行调节 。选择第二个策略是因为,我们可以根据loss的大小来判断是否是难例样本,但是这些样本都没有现成的label,因此我们借鉴论文《learning loss for active learning》的方法,在训练的时候加入一个损失预测(loss prediction,以下简称LP)模块,来预测各个样本的loss 。
LP模块从target prediction模块(简称TP)的一些中间层抽取特征(使其特征更加丰富),组合起来用于loss预测 。训练流程为:每次一个batch进来B个样本(B为偶数),将这B个样本拆分成B/2个样本对,分别送入TP模块和下面的LP模块 。LP模块的loss如下所示:
【淘宝专用背景图片 淘宝背景图】
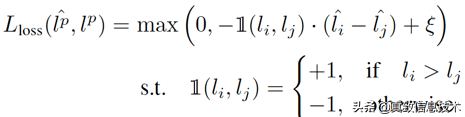
文章插图
对于每个样本对,LP模块预测出来的loss的相对大小要与TP模块预测出来的相对大小保持一致,且绝对值要大于一定的阈值,才会使loss等于0 。TP模块的loss在这里就是Ground Truth 。由于Ground Truth是随着训练不断变化的,直接对两个模块的输出计算MSE损失函数会导致效果非常差 。而且在做inference的时候,并不需要知道每个样本具体的loss大小,而只需要知道他们的loss的排名 。
在实际场景运用中,我们同时运用了置信度选择和LP模块两个策略,并且在线上做了测试 。结果如下:
- 淘宝相当于美国的什么 淘宝美国
- 直通车恶意点击怎么办 淘宝恶意点击直通车软件
- 淘小铺现在还可以赚钱吗 淘小铺怎样赚钱
- 免费注册淘宝账号 淘宝网注册淘宝账号
- 淘宝店铺营销方案 淘宝产品营销方案
- 海外代购 淘宝海外代购耐克是真的吗
- 淘宝店标制作教程 淘宝店标制作方法
- 淘宝新品福利购物券 淘宝购物券怎么买
- 淘宝秒杀什么意思
- 淘宝商品会自动上架吗 淘宝自动上架什么意思
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。