文章插图
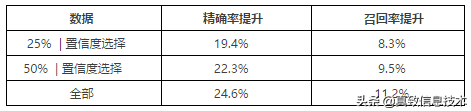
每一行表示的是,从上一版的模型召回的数据中,用相应的策略选择样本,进行标注后加入训练,然后相比于上一版的模型的精确率提升量和召回率提升量(注:本文所有的提升量都是指的绝对值) 。最后一行是指标注全部数据,|代表取并集 。从中可以看出,相比于最后一行,只需要标注30%的数据(25%的数据和置信度选择的数据取并集),就获得大部分的精确率提升和召回数量提升 。也就是说,后续performance的提升主要来源于这些难例数据,而在这个过程中可以减少约70%的标注量 。
2、噪声样本识别
在解决业务问题时,我们总希望能获得高质量的训练样本,而从业务场景中拿到的数据都含有一定比例的噪声样本,可能是因为标注规则不清晰,培训不够完善,或者是有一些边界样本,或者是其他的一些原因,即使是外包同学标注的数据往往也存在误标的情况 。如下图所示,这些都被标注成了正样本,如果将这些数据送入模型训练,很容易造成误杀 。

文章插图
在实验中我们发现,如果不对噪声样本进行处理的话,无论怎么改进算法本身,在验证集的精度一直上不去,到达了一个瓶颈 。
经过调研之后,我们发现,针对噪声样本问题,大致有以下四种解决方案:
(1)多人标注后进行投票,这种方法能在根源上消除噪声样本,但是成本巨大;
(2)训练时采取更大的batch size,这种方法能够在一定程度上降低噪声样本带来的影响,但是无法完全消除,而且容易受到计算资源的限制;
(3)设计一个noise-robust model,这种方法一般会设计特殊的网络结构或者loss函数,来提高模型的抗噪性能,但是其设计往往过于复杂;
(4)通过噪声样本识别方法来识别出噪声样本并进行校验,然后在干净的数据集重新训练 。
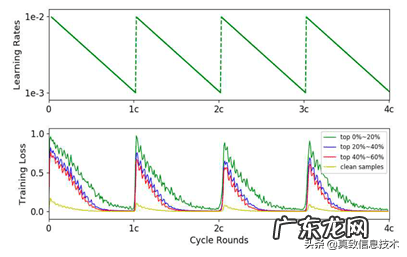
最终,我们选择了上面第四种方案 。我们使用本团队发表在ICCV2019的论文《O2U-Net: A Simple Noisy Label Detection Approachfor Deep Neural Networks》 。其基本思想为:在训练过程中循环调整学习率,使得模型在过拟合和欠拟合状态间反复切换 。突然增大学习率,使得网络跳出局部最优,进入欠拟合状态,此时噪声样本产生的loss较大,而干净样本的loss偏小,随着训练,学习率衰减,网络慢慢进入过拟合状态 。此时噪声样本和干净样本的loss都很小 。在此过程中噪声样本的loss的均值和方差都比干净样本大 。论文中学习率和样本loss的周期性变化如下图所示:
文章插图
网络的训练分为三步:
(1)pre-training阶段 。学习率设为正常值,训练直到在验证集的accuracy达到稳定 。
(2)循环学习率阶段 。
(3)对疑似噪声样本进行校验,在干净的数据集上重新训练 。
我们对loss均值排名前5%的疑似噪声数据重新进行了标注 。发现其中有约71%的是错标的噪声样本(其他的是难例样本),将这些噪声样本重新标注后加入训练集训练,在验证集的精度提高了0.74%,在线上的精确率提高了约8% 。从此可以看出,验证集的一个小的进步可以在线上改进很多,反之一个小的错误在线上会被放大很多倍 。
3、OHEM +级联
在数据量达到一定的规模之后,此时mobilenet_v2的performance表现非常疲软,在线上的结果表明,densenet的精确率比mobilenet_v2高5个百分点,于是我们果断切到了densenet 。另一方面,面临样本不平衡问题,如何保证精确率达到90%以上,同时要保证召回率,就构成一个挑战 。我们调研了一些处理样本不平衡问题的方法 。其中,我们注意到目标检测领域的经典的adaboost+cascade的算法 。目标检测领域里会生成很多候选区域,所以会产生很多负样本 。用adaboost算法构建强分类器,然后将多个分类器级联就可以使大部分正样本通过的同时拒绝掉几乎所有的负样本 。在我们的业务场景下,我们采用了OHEM(online hard example mining)+级联的方法,如下图所示:
- 淘宝相当于美国的什么 淘宝美国
- 直通车恶意点击怎么办 淘宝恶意点击直通车软件
- 淘小铺现在还可以赚钱吗 淘小铺怎样赚钱
- 免费注册淘宝账号 淘宝网注册淘宝账号
- 淘宝店铺营销方案 淘宝产品营销方案
- 海外代购 淘宝海外代购耐克是真的吗
- 淘宝店标制作教程 淘宝店标制作方法
- 淘宝新品福利购物券 淘宝购物券怎么买
- 淘宝秒杀什么意思
- 淘宝商品会自动上架吗 淘宝自动上架什么意思
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。