文章插图
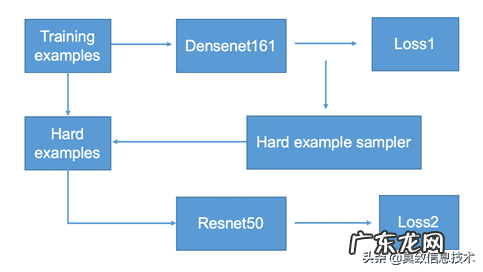
在训练的时候,第一个网络densenet161的batch size为A,然后将其loss最大的B个样本,送入到第二个网络resnet50进行训练 。这样每次第二个网络学习到的是第一个网络觉得比较难的样本 。在inference的时候,对两个模型的结果取与 。第二个网络选择resnet50是因为其表现优异,在验证集的精度只比densenet161低0.2%,之所以不选择同系列更大的网络是为了防止过拟合 。另一方面,OHEM算法本身就可以处理样本不平衡问题,因此不需要像某些two stage的目标检测算法,在第一个网络中设置1:3的超参数来进行欠采样 。
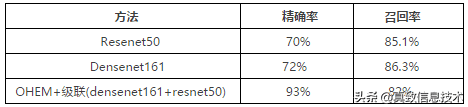
采用级联的方法后,在线上的精确率和召回率的变化见下表 。相比于单网络densenet161,精确率提高了21%,召回率降低了4.3% 。
文章插图
四、attention机制恶心图大致可以分为三类 。第一种类型是跟动物有关的,包括各种令人感到惊悚的爬行动物(从无腿的到无数条腿的都有),昆虫,以及一些颜色鲜红的死体活体,动物内脏等 。第二种类型,是跟人有关的,展示的是人体的各个丑陋、病态的部位 。如过度肥胖,脏牙齿,脸部、鼻子、身体、手脚等各种皮肤问题 。第三种是其他类型,即一些物体,包括惊悚的衣服、模型,脏乱的洗衣机、房间,马桶等 。(下图高能,可直接跳过)
文章插图
恶心样本多种多样,样本的特征分布非常分散 。我们分析样本后观察到,大部分图片都是某个或者某几个局部区域表现出令人恶心的特征,而不是全局都呈现出恶心的特征 。所以针对各种各样的恶心图,如何让模型focus到这些局部的恶心区域,对于提高模型的performance和泛化能力至关重要 。我们首先调研了论文《Learning Deep Features for
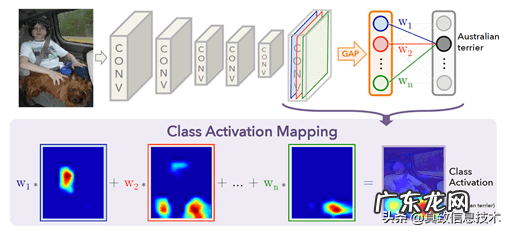
DiscriminativeLocalization》,作者将分类网络中最后的全连接层换成了GAP(Global average pooling)层,针对某一个类别,将最后一次卷积操作得到的feature map与其权重进行累加求和,于是就得到了这个类别的class activation map(CAM),如下图所示:
文章插图
CAM反映了这个类别关注图片中的哪个区域 。那么反过来,如果我们能够调整各个feature map的权重,对每个通道进行加权,那么就能够调整网络所关心的区域 。另一方面,卷积操作本身涉及到通道和空间两个维度,我们不仅可以对每个通道的特征进行加权,也可以对每个空间位置的特征进行加权 。因此我们采用了下图的方案 。
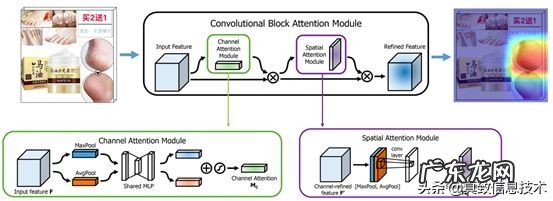
文章插图
我们在网路的基础block中嵌入了上图中的attention block 。其中,每个attentionblock由一个channel attention module和一个spatial attention module组成 。(具体实现细节可参考《CBAM:Convolutional Block Attention Module》) 。我们使用Grad-CAM的方法,利用梯度信息对网络关注的特征进行了可视化,如下图所示(高能,可直接跳过),反映出模型focus在恶心的区域上 。
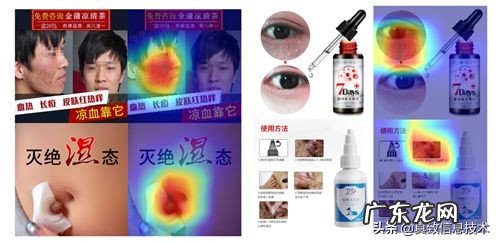
文章插图
五、业务结果目前,我们的恶心图模型已经在首猜上线,持续扫描首猜的增量商品池 。主要取得的业务结果如下:
(1)在今年双十一的前两天,对首猜的全量商品池进行扫描,为双十一期间消费者购物体验的提升作出了贡献;
- 淘宝相当于美国的什么 淘宝美国
- 直通车恶意点击怎么办 淘宝恶意点击直通车软件
- 淘小铺现在还可以赚钱吗 淘小铺怎样赚钱
- 免费注册淘宝账号 淘宝网注册淘宝账号
- 淘宝店铺营销方案 淘宝产品营销方案
- 海外代购 淘宝海外代购耐克是真的吗
- 淘宝店标制作教程 淘宝店标制作方法
- 淘宝新品福利购物券 淘宝购物券怎么买
- 淘宝秒杀什么意思
- 淘宝商品会自动上架吗 淘宝自动上架什么意思
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。