文章图片
项目地址:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/few_shot
高性能预测加速:文本生成场景高达 28 倍加速效果
PaddleNLP 与 NVDIA 强强联合 , 以 FasterTransformer[5] 为基础 , 提供了 Faster 系列的推理 API , 重点拓展了更多主流网络结构适配与解码策略支持 。 同时结合飞桨核心框架 2.1 版本全新的自定义 OP 的功能 , 提供了与飞桨框架无缝衔接的使用体验 。
文章图片
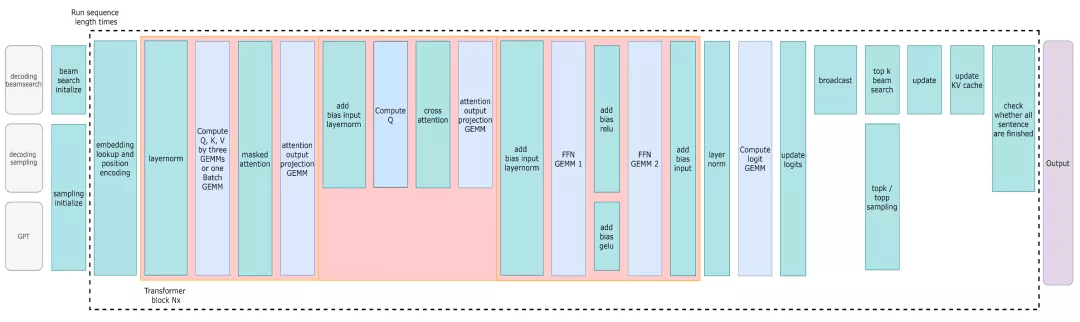
FasterTransformer Decoding Workflow
(1) 大幅提升生成任务的推理能力
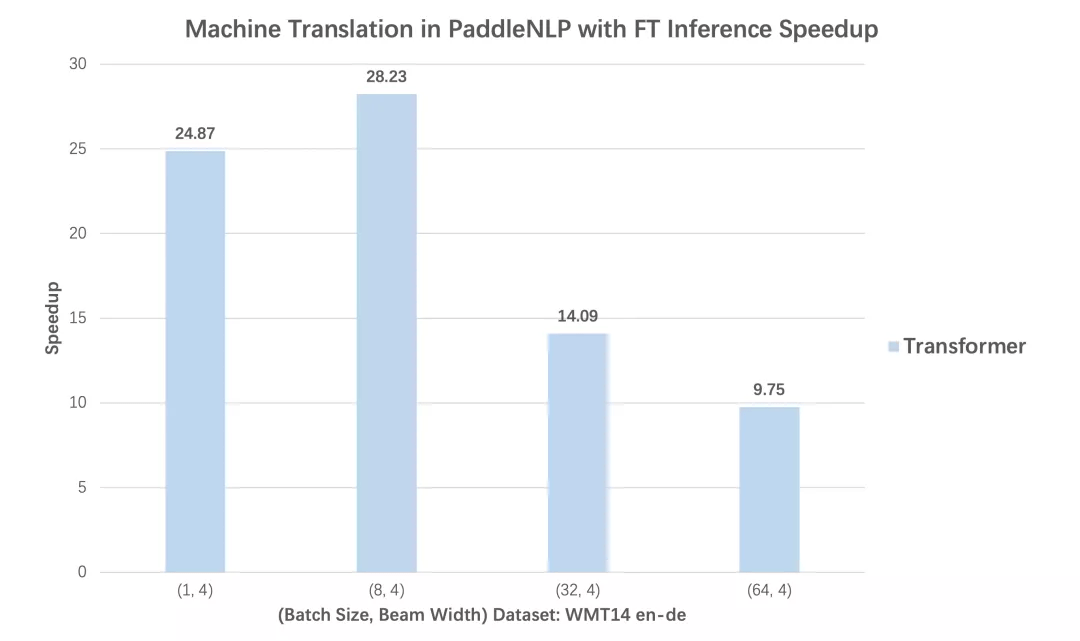
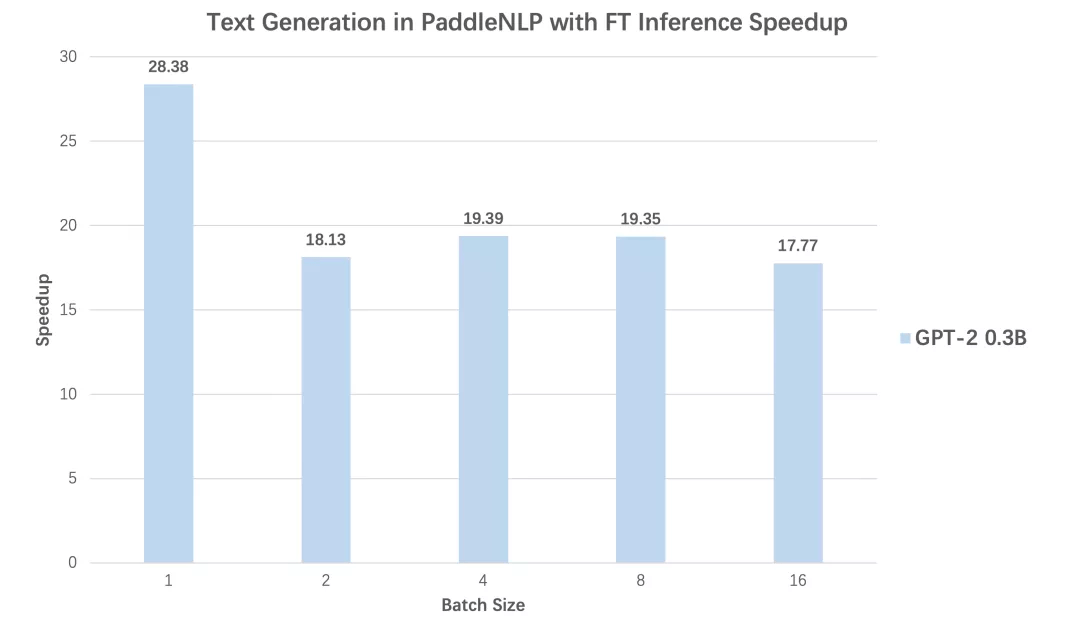
在 Transformer 机器翻译、GPT 文本生成两个任务中 , 分别对比使用动态图版本的性能和内置 Faster 系列的推理 API 后 , 不同 batch size 下预测性能加速比 , 从对比数据可以看到无论 Transformer 还是 GPT , 均可得到高达 28 倍推理速度提升!
文章图片
文章图片

文章图片

文章图片
PaddleNLP Transformer 翻译模型加速优化前后的Nsight Profling 对比图
(2)支持丰富的经典解码策略
PaddleNLP v2.1 提供工业界主流的解码加速支持 , 包括经典的 Beam Search , 以及多个 Sampling-based 的解码方式:如 Diverse Sibling Search[6]、T2T 版本的 Beam Search 实现 [7]、Top-k/Top-p Sampling 等 。 丰富的加速策略可以满足对话、翻译等工业场景的实际应用 , 同时 PaddleNLP 的加速实现也在百度内部经过了大规模互联网业务的真实考验 。

文章图片
表 1:PaddleNLP 2.1 支持加速的模型结构与解码策略
更多 PaddleNLP 加速使用文档可以参考:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/advanced_guide/fastertransformer.rst
别的不需要多说了 , 大家访问 GitHub 点过 star 之后自己体验吧:
https://github.com/PaddlePaddle/PaddleNLP
直播预告 除了重磅发版以外呢 , 我们还为大家精心准备了配套课程 , 在 10 月 13-15 日 , 连续三天 PaddleNLP 技术精讲课程 , 百度飞桨的明星讲师们历时一个月呕心沥血打磨的三日课 , 小伙伴们速度报名 , 快速 get PaddleNLP 最新技能点!
直播预告报名链接:https://paddleqiyeban.wjx.cn/vj/QG4uBYa.aspx?udsid=126583
[1] Entailment as Few-Shot Learner
(https://arxiv.org/pdf/2104.14690.pdf)
[2] Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
(https://arxiv.org/pdf/2001.07676.pdf)
[3] GPT Understands, Too
(https://arxiv.org/pdf/2103.10385.pdf)
[4]FewCLUE: A Chinese Few-shot Learning Evaluation Benchmark
(https://arxiv.org/pdf/2107.07498.pdf)
[5] https://github.com/NVIDIA/FasterTransformer
[6] A Simple, Fast Diverse Decoding Algorithm for Neural Generation
(https://arxiv.org/pdf/1611.08562.pdf)
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。