文章图片
3. 通过α来计算训练下一个弱分类器样本的权重D , 如果对应样本分类正确 , 则减小该样本的权重 , 公式为:
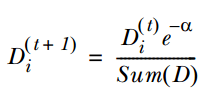
文章图片
如果样本分类错误 , 则增加该样本的权重 , 公式为:
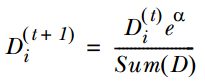
文章图片
4. 循环步骤1,2,3来继续训练多个分类器 , 只是其D值不同而已 。
测试过程如下:
输入一个样本到训练好的每个弱分类中 , 则每个弱分类都对应一个输出标签 , 然后该标签乘以对应的α , 最后求和得到值的符号即为预测标签值 。
Boosting算法的优点:
1. 低泛化误差;
2. 容易实现 , 分类准确率较高 , 没有太多参数可以调;
3. 缺点:
4. 对outlier比较敏感;
聚类:
根据聚类思想划分:
1. 基于划分的聚类:
K-means, k-medoids(每一个类别中找一个样本点来代表),CLARANS.
k-means是使下面的表达式值最小:
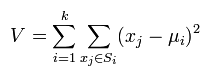
文章图片
k-means算法的优点:
(1)k-means算法是解决聚类问题的一种经典算法 , 算法简单、快速 。
(2)对处理大数据集 , 该算法是相对可伸缩的和高效率的 , 因为它的复杂度大约是O(nkt) , 其中n是所有对象的数目 , k是簇的数目,t是迭代的次数 。 通常k<<n 。 这个算法通常局部收敛 。
(3)算法尝试找出使平方误差函数值最小的k个划分 。 当簇是密集的、球状或团状的 , 且簇与簇之间区别明显时 , 聚类效果较好 。
缺点:
(1)k-平均方法只有在簇的平均值被定义的情况下才能使用 , 且对有些分类属性的数据不适合 。
(2)要求用户必须事先给出要生成的簇的数目k 。
(3)对初值敏感 , 对于不同的初始值 , 可能会导致不同的聚类结果 。
(4)不适合于发现非凸面形状的簇 , 或者大小差别很大的簇 。
(5)对于"噪声"和孤立点数据敏感 , 少量的该类数据能够对平均值产生极大影响 。
2. 基于层次的聚类:
自底向上的凝聚方法 , 比如AGNES 。
自上向下的分裂方法 , 比如DIANA 。
3. 基于密度的聚类:DBSACN,OPTICS,BIRCH(CF-Tree),CURE.
4. 基于网格的方法:STING, WaveCluster.
5. 基于模型的聚类:EM,SOM,COBWEB.
推荐系统:推荐系统的实现主要分为两个方面:基于内容的实现和协同滤波的实现 。
基于内容的实现:不同人对不同电影的评分这个例子 , 可以看做是一个普通的回归问题 , 因此每部电影都需要提前提取出一个特征向量(即x值) , 然后针对每个用户建模 , 即每个用户打的分值作为y值 , 利用这些已有的分值y和电影特征值x就可以训练回归模型了(最常见的就是线性回归) 。
这样就可以预测那些用户没有评分的电影的分数 。 (值得注意的是需对每个用户都建立他自己的回归模型)
从另一个角度来看 , 也可以是先给定每个用户对某种电影的喜好程度(即权值) , 然后学出每部电影的特征 , 最后采用回归来预测那些没有被评分的电影 。
当然还可以是同时优化得到每个用户对不同类型电影的热爱程度以及每部电影的特征 。
基于协同滤波的实现:协同滤波(CF)可以看做是一个分类问题 , 也可以看做是矩阵分解问题 。 协同滤波主要是基于每个人自己的喜好都类似这一特征 , 它不依赖于个人的基本信息 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。