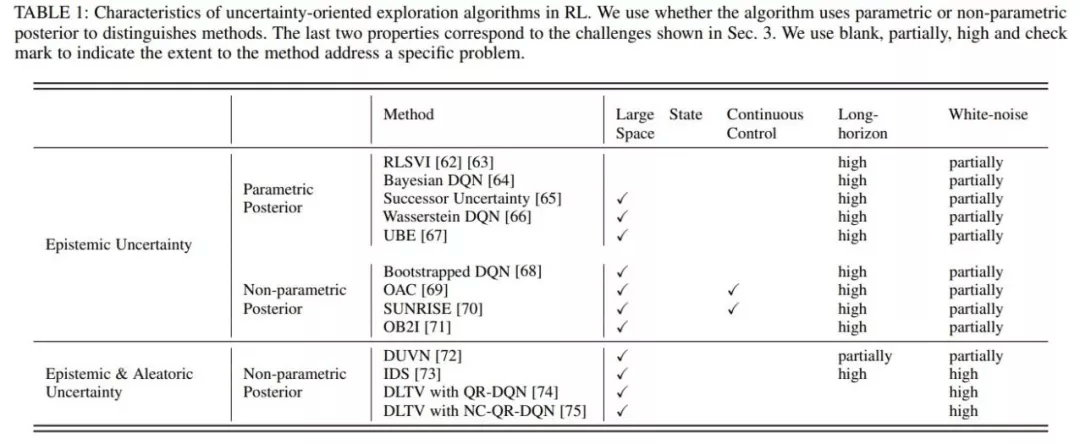
第?类只考虑在认知不确定性的引导下乐观探索 , 典型?作有RLSVI「2」、Bootstrapped DQN「3」、OAC「4」、OB2I「5」等;第?类在乐观探索的同时考虑避免环境不确定性的影响 , 典型?作有IDS「6」、DLTV「7」等 。
2、?向内在激励信号的探索策略
?类通常会通过不同?式的?我激励 , 积极主动地与世界交互并获得成就感 。 受此启发 , 内在激励信号导向的探索?法通常通过设计内在奖励来创造智能体的成就感 。 从设计内在激励信号所使?的技术 , 单智能体?法中?向内在激励信号的探索策略可分为三类 , 也即估计环境动?学预测误差的?法、状态新颖性估计?法和基于信息增益的?法 。 ?在多智能体问题中 , ?前的探索策略主要通过状态新颖性和社会影响两个?度考虑设计内在激励信号 。
估计环境动?学预测误差的?法主要是基于预测误差 , ?励智能体探索具有更?预测误差的状态 , 典型?作有ICM「8」、EMI「9」等 。
状态新颖性?法不局限于预测误差 , ?是直接通过衡量状态的新颖性(Novelty) , 将其作为内在激励信号引导智能体探索更新颖的状态 , 典型?作有RND「10」、Novelty Search「11」、LIIR「12」等 。
基于信息增益的?法则将信息获取作为内在奖励 , 旨在引导智能体探索未知领域 , 同时防?智能体过于关注随机领域 , 典型?作有VIME「13」等 。
?在多智能体强化学习中 , 有?类特别的探索策略通过衡量“社会影响” , 也即衡量智能体对其他智能体的影响作? , 指导作为内在激励信号 , 典型?作有EITI和 EDTI「14」等 。
3、其他
除了上述两?类主流的探索算法 , 综述?还调研了其他?些分?的?法 , 从其他?度进?有效的探索 。 这些?法为如何在DRL中实现通?和有效的探索提供了不同的见解 。
这主要包括以下三类 , ?是基于分布式的探索算法 , 也即使?具有不同探索行为的异构actor , 以不同的?式探索环境 , 典型?作包括Ape-x「15」、R2D2「16」等 。 ?是基于参数空间噪声的探索 , 不同于对策略输出增加噪声 , 采?噪声对策略参数进?扰动 , 可以使得探索更加多样化 , 同时保持?致性 , 典型?作包括NoisyNet「17」等 。 除了以上两类 , 综述还介绍了其他?种不同思路的探索?法 , 包括Go-Explore「18」 , MAVEN「19」等 。
四大挑战
综述重点总结了?效的探索策略主要?临的四?挑战 。
- ?规模状态动作空间 。 状态动作空间的增加意味着智能体需要探索的空间变? , 就?疑导致了探索难度的增加 。
- 稀疏、延迟奖励信号 。 稀疏、延迟的奖励信号会使得智能体的学习?常困难 , ?探索机制合理与否直接影响了学习效率 。
- 观测中的?噪声 。 现实世界的环境通常具有很?的随机性 , 即状态或动作空间中通常会出现不可预测的内容 , 在探索过程中避免?噪声的影响也是提升效率的重要因素 。
- 多智能体探索挑战 。 多智能体任务下 , 除了上述挑战 , 指数级增长的状态动作空间、智能体间协同探索、局部探索和全局探索的权衡都是影响多智能体探索效率的重要因素 。
文章图片
三个经典的benchmark
为了对不同的探索?法进?统?的实验评价 , 综述总结了上述?种有代表性的?法在三个代表性 benchmark上的实验结果: 《蒙特祖玛的复仇》 , 雅达利和Vizdoom 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。